Pytorch 中的数据集和数据加载器
PyTorch是 Facebook 开发的Python库,用于运行和训练机器学习和深度学习模型。训练深度学习模型需要我们将数据转换成模型可以处理的格式。 PyTorch提供了torch.utils.data库,通过DataSets和Dataloader类使数据加载变得容易。
Dataset本身是DataLoader构造函数的参数,它指示要从中加载的数据集对象。有两种类型的数据集:
- 地图样式数据集:该数据集提供两个函数 __getitem__( ) 和 __len__( ),分别返回引用的样本数据的索引和样本数。在示例中,我们将使用这种类型的数据集。
- 可迭代样式数据集:可以用一组可迭代数据样本表示的数据集,为此我们使用 __iter__( )函数。
另一方面, Dataloader不仅允许我们批量迭代数据集,还允许我们访问用于多处理的内置函数(允许我们并行加载多批数据,而不是一次加载一个批次),混洗, 等等。
句法:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, *, prefetch_factor=2, persistent_workers=False)
使用的数据集:心脏
让我们来处理一个例子,以便更清楚地了解这个概念。
首先导入所有必需的库和要使用的数据集。在通过 __getitem__( ) 协议访问的火炬张量中加载数据集,以获取特定数据集的索引。然后我们解包数据并打印相应的特征和标签。
例子:
Python3
# importing libraries
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
import numpy as np
import math
# class to represent dataset
class HeartDataSet():
def __init__(self):
# loading the csv file from the folder path
data1 = np.loadtxt('heart.csv', delimiter=',',
dtype=np.float32, skiprows=1)
# here the 13th column is class label and rest
# are features
self.x = torch.from_numpy(data1[:, :13])
self.y = torch.from_numpy(data1[:, [13]])
self.n_samples = data1.shape[0]
# support indexing such that dataset[i] can
# be used to get i-th sample
def __getitem__(self, index):
return self.x[index], self.y[index]
# we can call len(dataset) to return the size
def __len__(self):
return self.n_samples
dataset = HeartDataSet()
# get the first sample and unpack
first_data = dataset[0]
features, labels = first_data
print(features, labels)Python3
# Loading whole dataset with DataLoader
# shuffle the data, which is good for training
dataloader = DataLoader(dataset=dataset, batch_size=4, shuffle=True)
# total samples of data and number of iterations performed
total_samples = len(dataset)
n_iterations = total_samples//4
print(total_samples, n_iterations)
for i, (targets, labels) in enumerate(dataloader):
print(targets, labels)Python3
num_epochs = 2
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(dataloader):
# here: 303 samples, batch_size = 4, n_iters=303/4=75 iterations
# Run our training process
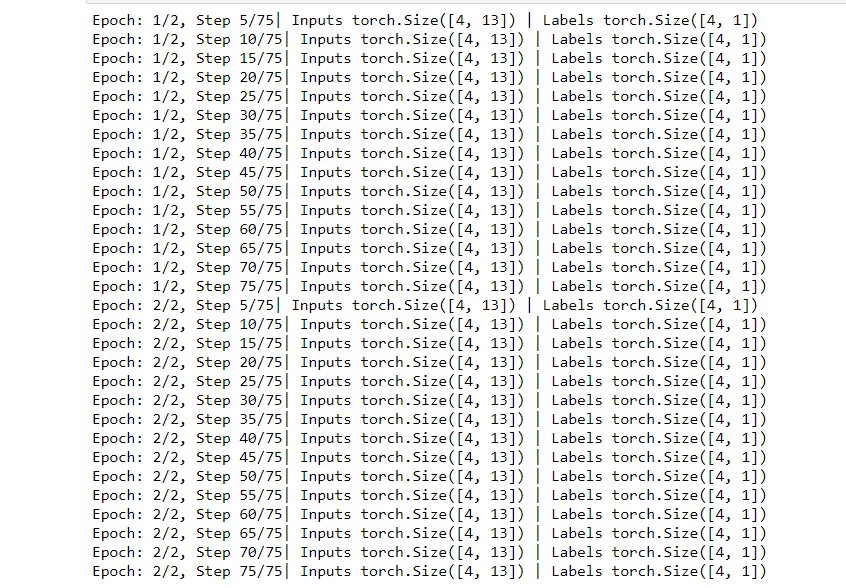
if (i+1) % 5 == 0:
print(f'Epoch: {epoch+1}/{num_epochs}, Step {i+1}/{n_iterations}|\
Inputs {inputs.shape} | Labels {labels.shape}')输出:
tensor([ 63.0000, 1.0000, 3.0000, 145.0000, 233.0000, 1.0000, 0.0000,
150.0000, 0.0000, 2.3000, 0.0000, 0.0000, 1.0000]) tensor([1.])
torch dataLoader 将这个数据集作为输入,连同其他用于 batch_size、shuffle 等的参数,计算每批的 nums_samples,然后分批打印出目标和标签。
例子:
蟒蛇3
# Loading whole dataset with DataLoader
# shuffle the data, which is good for training
dataloader = DataLoader(dataset=dataset, batch_size=4, shuffle=True)
# total samples of data and number of iterations performed
total_samples = len(dataset)
n_iterations = total_samples//4
print(total_samples, n_iterations)
for i, (targets, labels) in enumerate(dataloader):
print(targets, labels)
输出:

我们现在通过首先循环遍历 epoch 然后遍历样本来训练数据,然后在每次迭代中打印出 epoch 数、输入张量和标签张量。
例子:
蟒蛇3
num_epochs = 2
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(dataloader):
# here: 303 samples, batch_size = 4, n_iters=303/4=75 iterations
# Run our training process
if (i+1) % 5 == 0:
print(f'Epoch: {epoch+1}/{num_epochs}, Step {i+1}/{n_iterations}|\
Inputs {inputs.shape} | Labels {labels.shape}')
输出: