- PyTorch-数据集(1)
- PyTorch-数据集
- Pytorch 中的数据集和数据加载器(1)
- Pytorch 中的数据集和数据加载器
- PyTorch (1)
- PyTorch-加载数据(1)
- PyTorch-加载数据
- 在 Pytorch 中加载数据
- pytorch 逆 - Python (1)
- pytorch 1.7 - Python (1)
- pytorch 减少数据集数据加载器 - Python (1)
- PyTorch简介|什么是PyTorch
- PyTorch简介|什么是PyTorch(1)
- pytorch 减少数据集数据加载器 - Python 代码示例
- pytorch 逆 - Python 代码示例
- pytorch - Python 代码示例
- pytorch 1.7 - Python 代码示例
- 在 Pytorch 中创建张量
- 在 Pytorch 中创建张量(1)
- PyTorch - 任何代码示例
- 数据框创建 - Python (1)
- 创建数据框 python (1)
- 创建数据框 - Python (1)
- PyTorch-安装(1)
- PyTorch-安装
- pytorch 创建张量 - Python (1)
- pytorch - Shell-Bash (1)
- PyTorch安装|如何安装PyTorch(1)
- PyTorch安装|如何安装PyTorch
📅 最后修改于: 2020-11-11 00:46:23 🧑 作者: Mango
创建感知器模型数据集
现在,我们将获得有关如何创建,学习和测试Perceptron模型的知识。在PyTorch中Perceptron模型的实现是通过几个步骤完成的,例如为模型创建数据集,设置模型,训练模型以及测试模型。
让我们从第一步开始,即创建数据集。
为了创建数据集,我们将直接从SDK学习导入数据集。 SDK学习功能使我们可以访问许多预先准备的数据集。我们只需导入数据集即可访问所有这些数据集。在此,我们还使用numpy库进一步处理和分析此数据,最后使用最常用的库来绘制数据集,即,将导入matplotlib.pyplot。
在此,我们首先使用SDK学习创建线性可分离的数据集,然后使用火炬创建基于感知的神经网络。之后,神经网络将训练以学习如何拟合我们的数据集,以便能够将我们的数据分为两个离散的类。这将使用您可能熟悉的优化算法(梯度下降)来完成。
在此,我们将使用make_blobs()方法。此函数将创建一个数据点集群,这些数据点全部随机地以该集群的选定中心点为中心。
让我们看看创建数据集的步骤
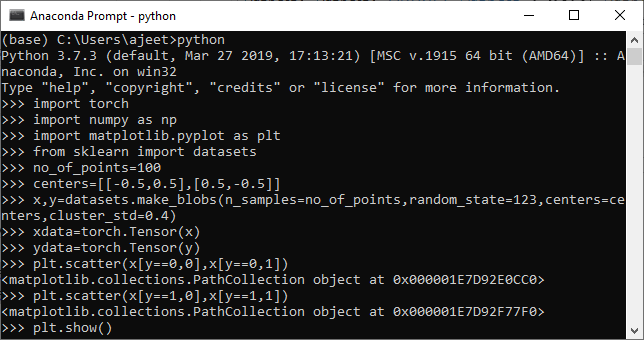
1.第一步是导入所有必需的库,例如torch,sklearn,numpy和matplotlib.pyplot。
import torch
import numpy as np
import matplotlib.pyplot as plt
fromsk learn import datasets
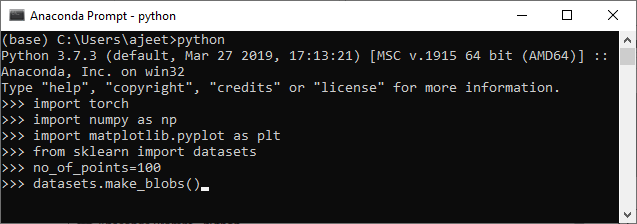
2.在第二步中,我们没有定义任何数据点,然后使用make_blobs()函数创建一个数据集。正如我告诉您的那样,此函数将创建一个数据点集群。
no_of_points=100
datasets.make_blobs()
3.在调用make_blobs()函数,我们需要创建一个嵌套列表,该列表指定集群中心的坐标。因此,我们必须调用列表中心,并通过以下方式为集群定义中心坐标。
centers=[[-0.5,0.5],[0.5,-0.5]]
4.现在,我们将创建数据集,并将数据点存储到变量x中,而将值存储到变量y中,我们将使用一下标签。
x,y=dataset.make_blobs()

5.由于尚未传递此函数的任何适当参数,因此尚未创建数据集。因此,我们在这里传递所有参数。第一个参数表示样本点的数量;第二个参数是随机状态,第三个参数是中心和最后一个参数,这将使我们能够生成第一个线性可分离的数据集,即簇std。
x,y=datasets.make_blobs(n_samples=no_of_points,random_state=123,centers=centers,cluster_std=0.4)

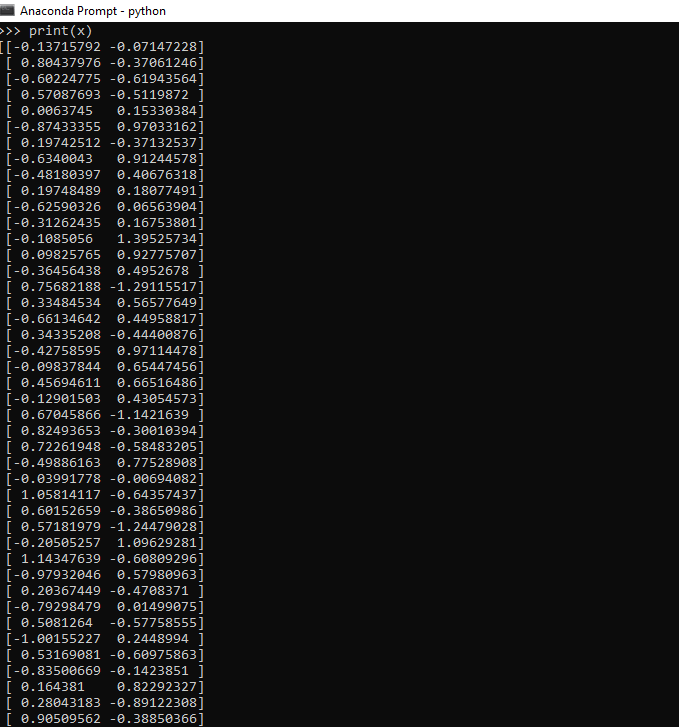
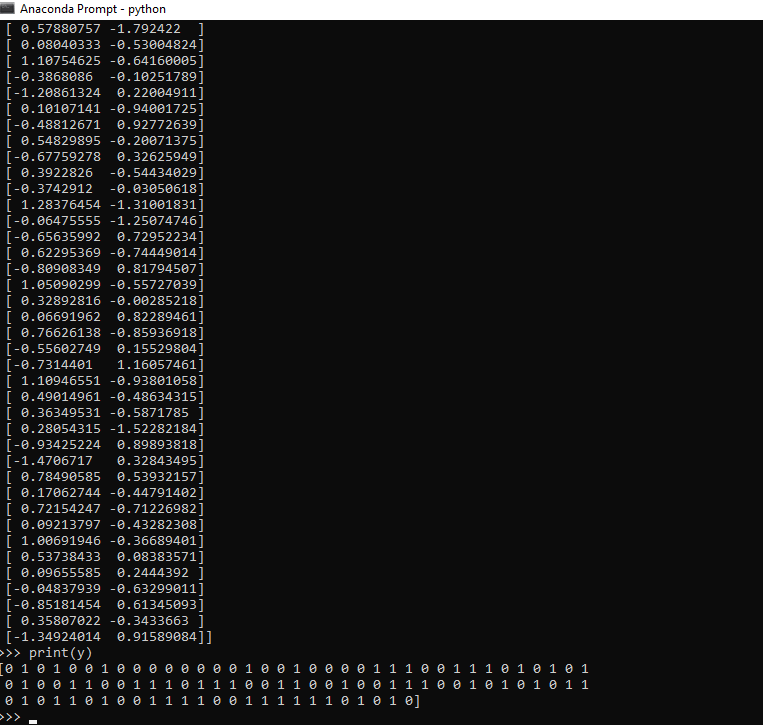
6.在下一步中,我们通过printx和y坐标将数据可视化,如下所示:
print(x)
print(y)
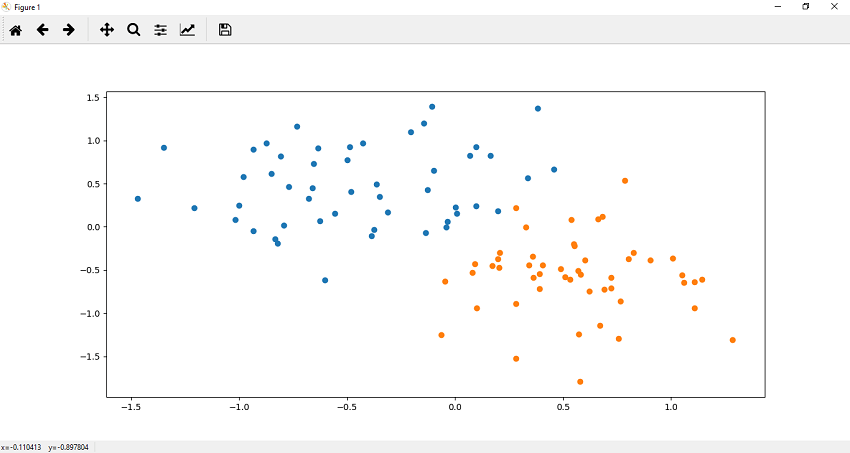
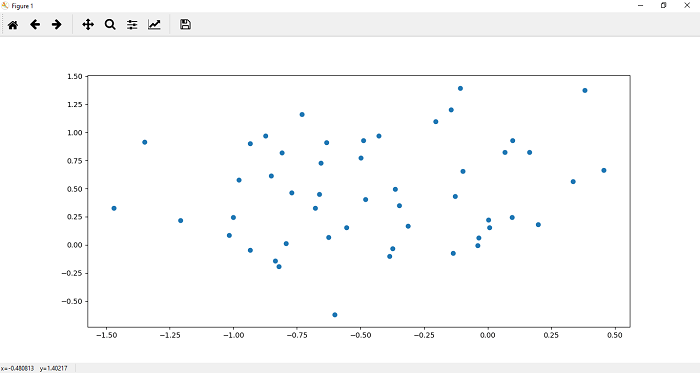
7.现在,根据需要自定义我们的数据集之后,我们可以使用plt.scatter()函数对其进行绘制和可视化。我们定义每个标签数据集的x和y坐标。让我们从标签为0的数据集开始。它绘制了数据的顶部区域。 0个标记数据集的散布函数定义为
plt.scatter(x[y==0,0],x[y==0,1])
8.现在,我们在数据的下部区域中绘制点。一个标记数据集的散点函数()定义为
plt.scatter(x[y==1,0],x[y==1,1])
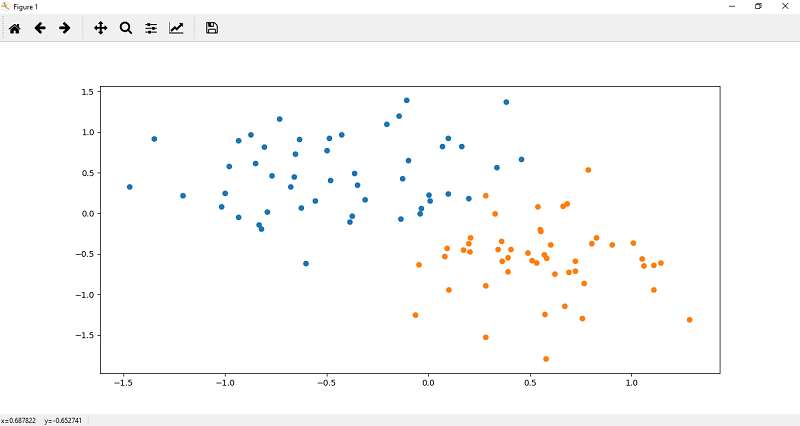
9.记住要训练模型x,并且y坐标都应为numpy数组。所以我们要做的是将x和y值更改为张量,如下所示
xdata=torch.Tensor(x)
ydata=torch.Tensor(y)