ML – 基于内容的推荐系统
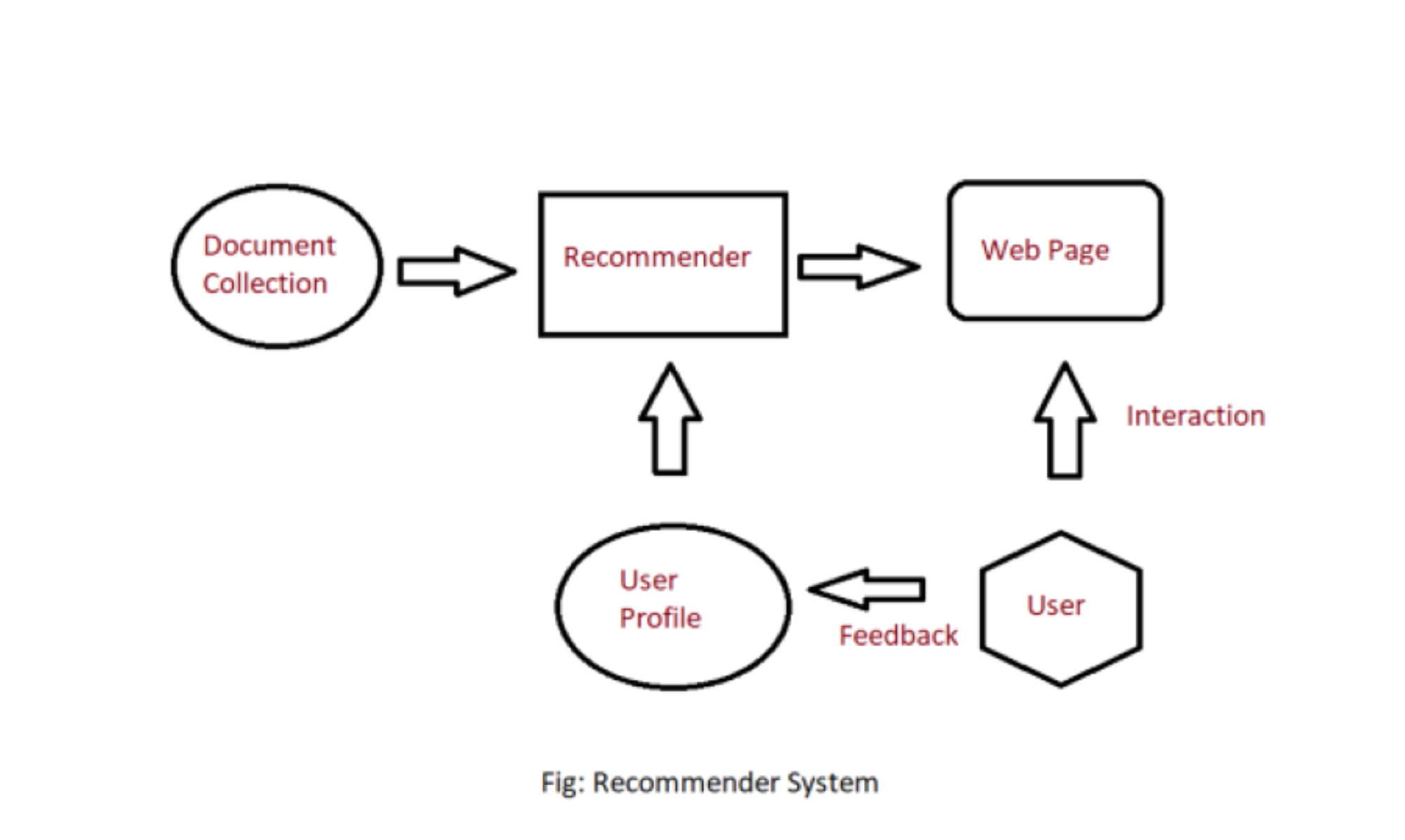
基于内容的推荐器根据我们从用户那里获取的数据工作,无论是显式(评级)还是隐式(单击链接)。我们通过数据创建用户配置文件,然后用于向用户提出建议,随着用户提供更多输入或对推荐采取更多操作,引擎变得更加准确。
用户资料:
在用户配置文件中,我们创建了描述用户偏好的向量。在创建用户配置文件时,我们使用效用矩阵来描述用户和项目之间的关系。有了这些信息,我们可以对用户喜欢哪个项目做出的最佳估计是这些项目的配置文件的一些聚合。
项目简介:
在 Content-Based Recommender 中,我们必须为每个项目构建一个配置文件,它将代表该项目的重要特征。
例如,如果我们制作一部电影作为一个项目,那么它的演员、导演、发行年份和类型是这部电影最重要的特征。我们还可以在项目配置文件中添加来自 IMDB(互联网电影数据库)的评级。
效用矩阵:
效用矩阵表示用户对某些项目的偏好。在从用户收集的数据中,我们必须找到用户喜欢的项目和不喜欢的项目之间的某种关系,为此我们使用效用矩阵。在其中我们为每个用户-项目对分配一个特定的值,这个值被称为偏好程度。然后我们绘制一个用户与各个项目的矩阵来识别他们的偏好关系。
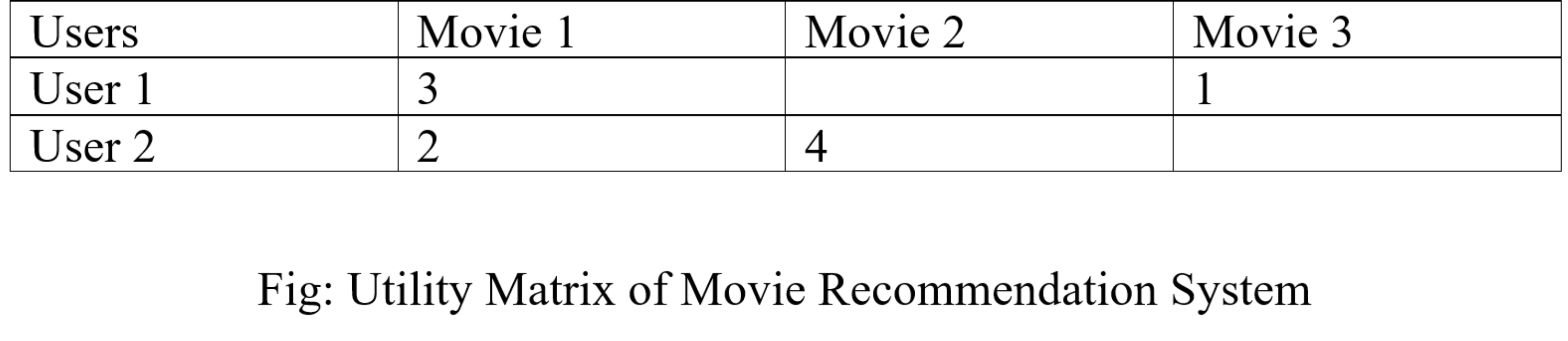
矩阵中有些列是空白的,这是因为我们不是每次都从用户那里得到全部输入,推荐系统的目标不是填满所有列,而是向用户推荐一部电影,他/她会更喜欢。通过这张表,我们的推荐系统不会向用户 2 推荐电影 3,因为在电影 1 中他们给出的评分大致相同,而在电影 3 中用户 1 给出的评分较低,因此用户 2 很有可能也给出了不会喜欢。
根据内容向用户推荐项目:
- 方法一:
我们可以使用物品向量与用户之间的余弦距离来确定其对用户的偏好。为了解释这一点,让我们考虑一个例子:
我们观察到,用户的向量对于倾向于出现在用户喜欢的电影中的演员将具有正数,对于用户不喜欢的演员具有负数,考虑一部电影,其中有用户喜欢的演员,只有少数演员是用户不喜欢,那么用户向量和电影向量之间的余弦角将是一个很大的正分数。因此,角度将接近于 0,因此向量之间的余弦距离很小。
它表示用户倾向于喜欢这部电影,如果余弦距离很大,那么我们倾向于避免推荐该项目。 - 方法二:
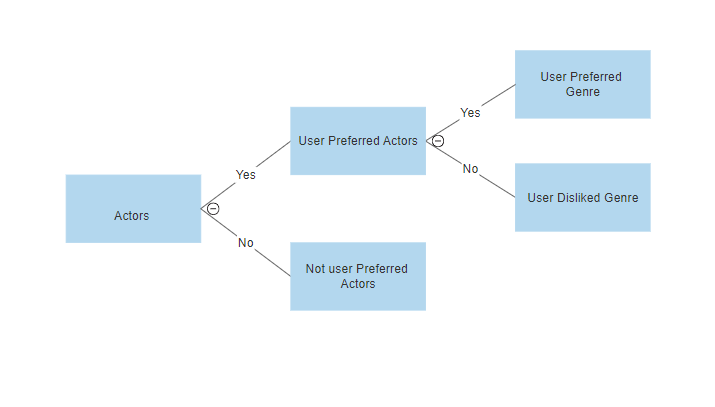
我们也可以在推荐系统中使用分类方法,比如我们可以使用决策树来确定用户是否想看电影,比如在每个级别我们可以应用特定条件来优化我们的推荐。例如: