Pandas – 从整个数据帧中去除空白
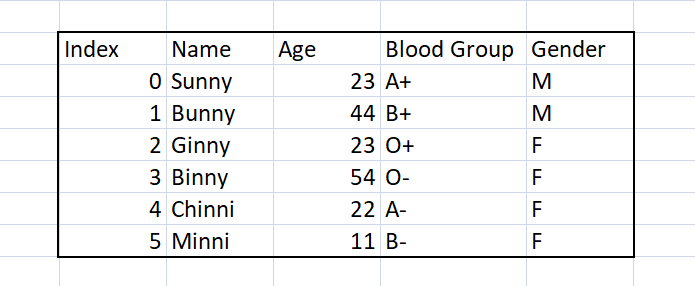
“我们可以在没有信息的情况下拥有数据,但没有数据我们就无法拥有信息。”这句话多么美妙。数据是数据科学家的支柱,根据一项调查,数据科学家花费大约 60% 的时间在清理和组织数据上,因此我们有责任让我们熟悉不同的技术以更好地组织数据。在本文中,我们将学习从整个 DataFrame 中删除额外的条带空白的不同方法。这里使用的数据集如下:

在上图中,我们观察到 Name、Age、Blood Group 和 Gender 列中的数据是不规则的。在特定列的大多数单元格中,值的前导部分存在额外的空白。所以我们的目标是删除所有额外的空白并以系统的方式组织它。我们将使用不同的方法来帮助我们从单元格中删除所有额外的空间。不同的方法是:
Using Strip() function
Using Skipinitialspace
Using replace function
Using Converters去除多余空格的不同方法
方法 1:使用 Strip()函数:
Pandas 提供了预定义方法“pandas.Series.str.strip()”来去除字符串中的空格。使用 strip函数,我们可以轻松地从凝视的前导和尾随空格中删除额外的空格。它返回一个对象的系列或索引。它需要我们想要从字符串的头部和尾部(前导和尾随字符)中删除的一组字符。默认情况下,它是 none,如果我们不传递任何字符,那么它将从字符串删除前导和尾随空格。它返回一个对象的系列或索引。
Syntax: pandas.Series.str.strip(to_strip = None)
Explanation: It takes set of characters that we want to remove from head and tail of string(leading and trailing character’s).
Parameter: By default it is none and if we do not pass any characters then it will remove leading and trailing whitespace from the string. It returns series or index of object.
例子 :
Python3
# importing library
import pandas as pd
# Creating dataframe
df = pd.DataFrame({'Names' : [' Sunny','Bunny','Ginny ',' Binny ',' Chinni','Minni'],
'Age' : [23,44,23,54,22,11],
'Blood Group' : [' A+',' B+','O+','O-',' A-','B-'],
'Gender' : [' M',' M','F','F','F',' F']
})
# As dataset having lot of extra spaces in cell so lets remove them using strip() function
df['Names'].str.strip()
df['Bolld Group'].str.strip()
df['Gender'].str.strip()
# Printing dataframe
print(df)Python3
# importing library
import pandas as pd
# reading csv file and at a same time using skipinitial attribute which will remobe extra space
df = pd.read_csv('\\student_data.csv', skipinitialspace = True)
# printing dataset
print(df)Python3
# importing library
import pandas as pd
# Creating dataframe
df = pd.DataFrame({'Name' : [' Sunny','Bunny','Ginny ',' Binny ',' Chinni','Minni'],
'Age' : [23,44,23,54,22,11],
'Blood Group' : [' A+',' B+','O+','O-',' A-','B-'],
'Gender' : [' M',' M','F','F','F',' F']
})
# As dataset having lot of extra spaces in cell so lets remove them using strip() function
df['Names'].str.replace(' ', '')
df['Bolld Group'].str.replace(' ', '')
df['Gender'].str.replace(' ', '')
# Printing dataframe
print(df)Python3
# importing library
import pandas as pd
# reading csv file and at a same time using converters attribute which will remove extra space
df = pd.read_csv('\\student_data.csv', converters={'Name': str.strip(),
'Blood Group' : str.strip(),
'Gender' : str.strip() } )
# printing dataset
print(df)Python3
# Importing required libraries
import pandas as pd
# Creating DataFrame having 4 columns and but
# the data is in unregularized way.
df = pd.DataFrame({'Names': [' Sunny', 'Bunny', 'Ginny ',
' Binny ', ' Chinni', 'Minni'],
'Age': [23, 44, 23, 54, 22, 11],
'Blood_Group': [' A+', ' B+', 'O+', 'O-',
' A-', 'B-'],
'Gender': [' M', ' M', 'F', 'F', 'F', ' F']
})
# Creating a function which will remove extra leading
# and tailing whitespace from the data.
# pass dataframe as a parameter here
def whitespace_remover(dataframe):
# iterating over the columns
for i in dataframe.columns:
# checking datatype of each columns
if dataframe[i].dtype == 'object':
# applying strip function on column
dataframe[i] = dataframe[i].map(str.strip)
else:
# if condn. is False then it will do nothing.
pass
# applying whitespace_remover function on dataframe
whitespace_remover(df)
# printing dataframe
print(df)输出:

方法 2:使用 Skipinitialspace :
它不是任何方法,但它是 Pandas 中 read_csv() 方法中存在的参数之一。在pandas.read_csv()方法中存在skipinitialspace参数,使用它我们可以跳过整个数据帧中存在的初始空间。默认情况下,它是 False,使它成为 True 以删除额外的空间。
Syntax : pandas.read_csv(‘path_of_csv_file’, skipinitialspace = True)
# By default value of skipinitialspace is False, make it True to use this parameter.
例子 :
蟒蛇3
# importing library
import pandas as pd
# reading csv file and at a same time using skipinitial attribute which will remobe extra space
df = pd.read_csv('\\student_data.csv', skipinitialspace = True)
# printing dataset
print(df)
输出:
方法3:使用替换函数:
使用 replace()函数我们还可以从数据框中删除多余的空格。 Pandas 提供了预定义方法“pandas.Series.str.replace()”来删除空格。它的程序将与strip()方法程序相同,唯一不同的是这里我们将在strip()的地方使用replace函数。
Syntax : pandas.Series.str.replace(' ', '')例子 :
蟒蛇3
# importing library
import pandas as pd
# Creating dataframe
df = pd.DataFrame({'Name' : [' Sunny','Bunny','Ginny ',' Binny ',' Chinni','Minni'],
'Age' : [23,44,23,54,22,11],
'Blood Group' : [' A+',' B+','O+','O-',' A-','B-'],
'Gender' : [' M',' M','F','F','F',' F']
})
# As dataset having lot of extra spaces in cell so lets remove them using strip() function
df['Names'].str.replace(' ', '')
df['Bolld Group'].str.replace(' ', '')
df['Gender'].str.replace(' ', '')
# Printing dataframe
print(df)
输出:

方法 4:使用转换器:
它类似于skipinitialspace,它是pandas预定义方法名称“read_csv”中存在的参数之一。它用于在特定列上应用不同的功能。我们必须在字典中传递函数。这里我们将直接传递 strip()函数,它会在读取 csv 文件时去除多余的空间。
Syntax : pd.read_csv(“path_of_file”, converters={‘column_names’: function_name})
# Pass dict of functions and column names, where column names act as unique keys and function as value.
例子 :
蟒蛇3
# importing library
import pandas as pd
# reading csv file and at a same time using converters attribute which will remove extra space
df = pd.read_csv('\\student_data.csv', converters={'Name': str.strip(),
'Blood Group' : str.strip(),
'Gender' : str.strip() } )
# printing dataset
print(df)
输出:
通过创建一些代码从整个 DataFrame 中删除额外的空白:
蟒蛇3
# Importing required libraries
import pandas as pd
# Creating DataFrame having 4 columns and but
# the data is in unregularized way.
df = pd.DataFrame({'Names': [' Sunny', 'Bunny', 'Ginny ',
' Binny ', ' Chinni', 'Minni'],
'Age': [23, 44, 23, 54, 22, 11],
'Blood_Group': [' A+', ' B+', 'O+', 'O-',
' A-', 'B-'],
'Gender': [' M', ' M', 'F', 'F', 'F', ' F']
})
# Creating a function which will remove extra leading
# and tailing whitespace from the data.
# pass dataframe as a parameter here
def whitespace_remover(dataframe):
# iterating over the columns
for i in dataframe.columns:
# checking datatype of each columns
if dataframe[i].dtype == 'object':
# applying strip function on column
dataframe[i] = dataframe[i].map(str.strip)
else:
# if condn. is False then it will do nothing.
pass
# applying whitespace_remover function on dataframe
whitespace_remover(df)
# printing dataframe
print(df)
在上面的第一行代码片段中,我们导入了所需的库,这里使用 pandas 对数据执行读、写和许多其他操作,然后我们使用具有 4 列'Names', 'Age' , 'Blood_Group' 的pandas 创建了一个 DataFrame和“性别” 。几乎所有列都有不规则数据。现在主要部分从这里开始,我们创建了一个函数,它将从数据中删除额外的前导和尾随空格。此函数将数据帧作为参数并检查每列的数据类型,如果列的数据类型为“对象”,则在该列上应用在 Pandas 库中预定义的条带函数,否则它将什么也不做。然后在下一行,我们在数据帧上应用 whitespace_remover()函数,它成功地从列中删除了多余的空格。
输出: