毫升 |线性判别分析
线性判别分析或正态判别分析或判别函数分析是一种降维技术,常用于监督分类问题。它用于对组中的差异进行建模,即分离两个或多个类。它用于将高维空间中的特征投影到低维空间。
例如,我们有两个类,我们需要有效地将它们分开。类可以有多个功能。仅使用单个特征对它们进行分类可能会导致一些重叠,如下图所示。因此,我们将继续增加特征的数量以进行适当的分类。

例子:
假设我们有两组数据点,它们属于我们想要分类的两个不同类别。如给定的二维图所示,当数据点绘制在二维平面上时,没有一条直线可以将两类数据点完全分开。因此,在这种情况下,使用 LDA(线性判别分析)将 2D 图简化为 1D 图,以最大化两个类之间的可分离性。
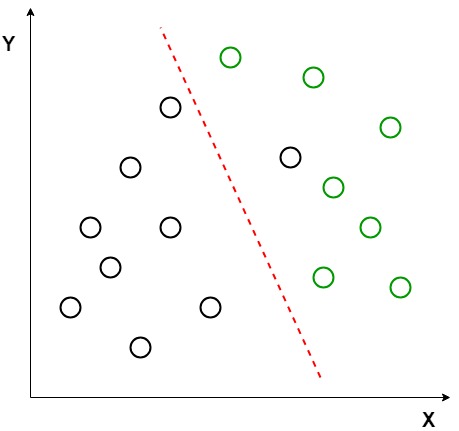
在这里,线性判别分析使用两个轴(X 和 Y)来创建一个新轴,并将数据投影到一个新轴上,以最大限度地分离两个类别,从而将 2D 图缩小为一维图。
LDA 使用两个标准来创建新轴:
- 最大化两个类的均值之间的距离。
- 最小化每个类中的变化。

在上图中,可以看到在 2D 图中生成并绘制了一个新轴(红色),以便最大化两个类的均值之间的距离并最小化每个类内的变化。简单来说,这个新生成的轴增加了两个类的数据点之间的间隔。使用上述标准生成这个新轴后,类的所有数据点都绘制在这个新轴上,如下图所示。

但是,当分布的均值共享时,线性判别分析会失败,因为 LDA 不可能找到使两个类线性可分的新轴。在这种情况下,我们使用非线性判别分析。
数学
假设我们有两个类和一个 d 维样本,例如 x1, x2 ... xn,其中:
- n1 个样本来自类 (c1),n2 个样本来自类 (c2)。
若xi为数据点,则其在单位向量v表示的直线上的投影可写为vTxi
假设 u1 和 u2 分别是投影前样本类 c1 和 c2 的均值,u1hat 表示投影后类样本的均值,计算公式为:
相似地,
现在,在 LDA 中,我们需要标准化 |\widetilde{\mu_1} -\widetilde{\mu_2} |。设 y_i = v^{T}x_i 为投影样本,则 c1 样本的散布为:
相似地:
现在,我们需要将我们的数据投影到方向为 v 的直线上
为了最大化上述等式,我们需要找到一个投影向量,该向量可以最大化减少两个类别的散布的均值差异。现在,类 c1 和 c2 的 s1 和 s2 的散点矩阵是:
和 s2

简化上述等式后,我们得到:
现在,我们定义,散布在类(s w )内并散布 b/w 类(s b ):
现在,我们尝试简化 J(v) 的分子部分
现在,为了最大化上述方程,我们需要计算关于 v 的微分
这里,对于 J(v) 的最大值,我们将使用对应于最高特征值的值。这将为我们提供 LDA 的最佳解决方案。
LDA 的扩展:
- 二次判别分析 (QDA):每个类使用自己的方差估计(或当有多个输入变量时的协方差)。
- 灵活判别分析 (FDA):使用输入的非线性组合,例如样条。
- 正则化判别分析(RDA):将正则化引入方差(实际上是协方差)的估计中,缓和不同变量对 LDA 的影响。
执行
- 在这个实现中,我们将使用 Scikit-learn 库对 Iris 数据集进行线性判别分析。
Python3
# necessary import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
# read dataset from URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
cls = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
dataset = pd.read_csv(url, names=cls)
# divide the dataset into class and target variable
X = dataset.iloc[:, 0:4].values
y = dataset.iloc[:, 4].values
# Preprocess the dataset and divide into train and test
sc = StandardScaler()
X = sc.fit_transform(X)
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# apply Linear Discriminant Analysis
lda = LinearDiscriminantAnalysis(n_components=2)
X_train = lda.fit_transform(X_train, y_train)
X_test = lda.transform(X_test)
# plot the scatterplot
plt.scatter(
X_train[:,0],X_train[:,1],c=y_train,cmap='rainbow',
alpha=0.7,edgecolors='b'
)
# classify using random forest classifier
classifier = RandomForestClassifier(max_depth=2, random_state=0)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# print the accuracy and confusion matrix
print('Accuracy : ' + str(accuracy_score(y_test, y_pred)))
conf_m = confusion_matrix(y_test, y_pred)
print(conf_m)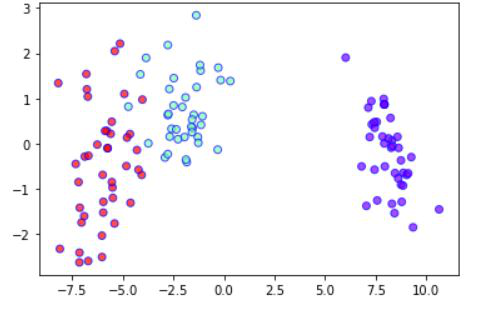
LDA 2 - 变量图
Accuracy : 0.9
[[10 0 0]
[ 0 9 3]
[ 0 0 8]]应用:
- 人脸识别:在计算机视觉领域,人脸识别是一个非常流行的应用,其中每张脸都由非常多的像素值表示。此处使用线性判别分析 (LDA) 以在分类过程之前将特征数量减少到更易于管理的数量。生成的每个新维度都是像素值的线性组合,形成模板。使用 Fisher 线性判别式获得的线性组合称为 Fisher 面。
- 医疗:在该领域中,线性判别分析 (LDA) 用于根据患者的各种参数和正在接受的医疗将患者的疾病状态分类为轻度、中度或重度。这有助于医生加强或减慢治疗速度。
- 客户识别:假设我们要识别最有可能在购物中心购买特定产品的客户类型。通过进行简单的问答调查,我们可以收集客户的所有特征。在这里,线性判别分析将帮助我们识别和选择可以描述最有可能在购物中心购买特定产品的客户群特征的特征。