使用 memory_profiler 在Python中进行内存分析
如果你经常使用Python ,那么你可能知道很多人声称Python需要更多的时间来执行。好吧,您可能已经看到了诸如执行部分代码所花费的总时间之类的方法,但有时您需要更多的东西。内存使用情况如何?没有人真正谈论这一点,但它同样重要。这可能看起来真的微不足道,但在为生产编写代码时它实际上非常重要。
我们将使用 PyPi的内存分析器。我们还需要请求来测试功能。为此,只需在终端中输入以下内容
pip3 install memory-profiler requests注意:如果您在 windows 上工作或使用虚拟环境,那么它将是pip而不是pip3
现在一切都设置好了,休息显然很容易和有趣。创建一个名为word_extractor.py的新文件并将代码添加到其中。下面是代码的实现。一切都很好地记录为内联注释。
Python3
# imports
from memory_profiler import profile
import requests
class BaseExtractor:
# decorator which specifies which
# function to monitor
@profile
def parse_list(self, array):
# create a file object
f = open('words.txt', 'w')
for word in array:
# writing words to file
f.writelines(word)
# decorator which specifies which
# function to monitor
@profile
def parse_url(self, url):
# fetches the response
response = requests.get(url).text
with open('url.txt', 'w') as f:
# writing response to file
f.writelines(response)Python3
from word_extractor import BaseExtractor
if __name__ == "__main__":
# url for word list (huge)
url = 'https://raw.githubusercontent.com/dwyl/english-words/master/words.txt'
# word list in array
array = ['one', 'two', 'three', 'four', 'five']
# initializing BaseExtractor object
extractor = BaseExtractor()
# calling parse_url function
extractor.parse_url(url)
# calling pasrse_list function
extractor.parse_list(array)注意@profile这是一个装饰器。任何被这个装饰函数,都会被跟踪。现在,我们的主要代码已经准备好了。让我们编写将调用此类函数的驱动程序代码。现在,创建另一个名为run.py的文件并在其中插入以下代码。
Python3
from word_extractor import BaseExtractor
if __name__ == "__main__":
# url for word list (huge)
url = 'https://raw.githubusercontent.com/dwyl/english-words/master/words.txt'
# word list in array
array = ['one', 'two', 'three', 'four', 'five']
# initializing BaseExtractor object
extractor = BaseExtractor()
# calling parse_url function
extractor.parse_url(url)
# calling pasrse_list function
extractor.parse_list(array)
所以,基本上现在我们已经完成了。您会注意到parse_url()将比parse_list()消耗更多的内存,这很明显,因为 parse_url 调用 URL 并将响应内容写入文本文件。如果你打开链接,那么你会发现单词列表是巨大的。因此,现在要测试您的代码,只需运行run.py文件。您可以通过键入
python3 run.py注意:如果您在 windows 上工作或使用虚拟环境,那么它将是Python而不是 python3
如果一切运行成功,那么您应该会看到类似这样的内容
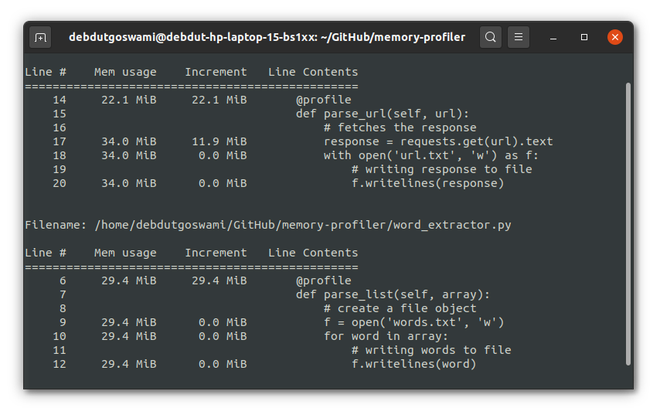
内存分析器统计
要记住的重要一点是内存分析器本身会消耗大量内存。仅在开发中使用它,但在生产中避免使用它。