STING – 数据挖掘中的统计信息网格
STING 是一种基于网格的聚类技术。在 STING 中,数据集以分层方式递归划分。在数据集之后,每个单元格被分成不同数量的单元格。并且在单元格之后,收集单元格的统计度量,这有助于尽快回答查询。
数据挖掘中基于网格的方法:
在基于网格的方法中,实例空间被划分为网格结构。然后使用网格的单元而不是单个数据点作为基本单位来应用聚类技术。这种方法最大的优点是提高了处理时间。
统计信息网格(STING):
STING 是一种基于网格的聚类技术。它使用多维网格数据结构,将空间量化为有限数量的单元。它不是关注数据点,而是关注数据点周围的价值空间。
在 STING 中,空间区域被划分为矩形单元和不同分辨率级别的若干级单元。高层单元被分成几个低层单元。
在 STING 中,有关每个单元格中属性的统计信息(例如平均值、最大值和最小值)被预先计算并存储为统计参数。这些统计参数对于查询处理和其他数据分析任务很有用。
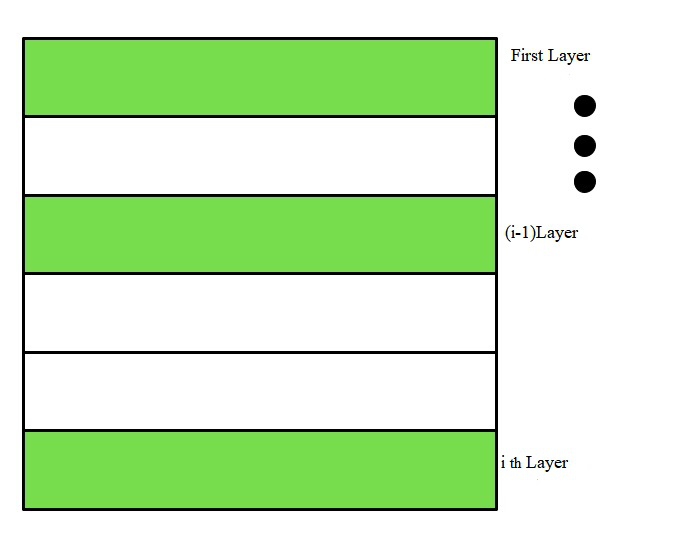
高层单元的统计参数可以很容易地从低层单元的参数中计算出来。
STING 的工作原理:
第 1 步:首先确定一个层。
第 2 步:对于该层的每个单元格,计算该单元格与查询相关的置信区间或估计概率范围。
第 3 步:根据上面的区间计算,它将单元格标记为相关或不相关。
第四步:如果该层是最底层,则转到第6点,否则转到第5点。
第 5 步:将层次结构向下一层。对于那些构成高层相关单元的单元,转到第 2 点。
第6步:如果满足查询规范,则转到第8点,否则转到第7点。
步骤 7:检索那些落入相关单元格的数据并进行进一步处理。返回满足查询要求的结果。转到第 9 点。
第 8 步:找到相关单元格的区域。返回满足查询要求的区域。转到第 9 点。
第 9 步:停止或终止。
好处:
- 基于网格的计算与查询无关,因为存储在每个单元格中的统计数据代表了网格单元格中数据的汇总,并且与查询无关。
- 网格结构有助于并行处理和增量更新。
坏处:
- Sting(统计网格)的主要缺点。我们知道,所有的簇边界要么是水平的,要么是垂直的,所以没有检测到对角线边界。