R编程中的朴素贝叶斯分类器
朴素贝叶斯是 R 编程中的监督非线性分类算法。朴素贝叶斯分类器是一系列简单的概率分类器,它们基于应用贝叶斯定理和特征或变量之间的强(朴素)独立假设。朴素贝叶斯算法之所以称为“朴素”,是因为它假设某个特征的出现与其他特征的出现无关。
理论
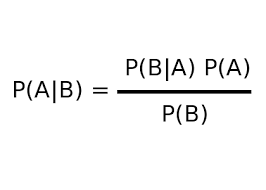
朴素贝叶斯算法基于贝叶斯定理。贝叶斯定理给出了在另一个事件 B 已经发生的情况下,一个事件 A 的条件概率。
where,
P(A|B) = Conditional probability of A given B.
P(B|A) = Conditional probability of B given A.
P(A) = Probability of event A.
P(B) = Probability of event B.
对于许多预测变量,我们可以将后验概率表述如下:
P(A|B) = P(B1|A) * P(B2|A) * P(B3|A) * P(B4|A) …
例子
Consider a sample space:
{HH, HT, TH, TT}
where,
H: Head
T: Tail
P(Second coin being head given = P(A|B)
first coin is tail) = P(A|B)
= [P(B|A) * P(A)] / P(B)
= [P(First coin is tail given second coin is head) *
P(Second coin being Head)] / P(first coin being tail)
= [(1/2) * (1/2)] / (1/2)
= (1/2)
= 0.5数据集
鸢尾花数据集由来自 3 种鸢尾花(Iris setosa、Iris virginica、Iris versicolor)中的每一种的 50 个样本和英国统计学家和生物学家 Ronald Fisher 在其 1936 年论文 The use of multiple measurement in taxonomic questions 中引入的多元数据集组成。从每个样本中测量了四个特征,即萼片和花瓣的长度和宽度,基于这四个特征的组合,Fisher 开发了一个线性判别模型来区分物种。
Python3
# Loading data
data(iris)
# Structure
str(iris)Python3
# Installing Packages
install.packages("e1071")
install.packages("caTools")
install.packages("caret")
# Loading package
library(e1071)
library(caTools)
library(caret)
# Splitting data into train
# and test data
split <- sample.split(iris, SplitRatio = 0.7)
train_cl <- subset(iris, split == "TRUE")
test_cl <- subset(iris, split == "FALSE")
# Feature Scaling
train_scale <- scale(train_cl[, 1:4])
test_scale <- scale(test_cl[, 1:4])
# Fitting Naive Bayes Model
# to training dataset
set.seed(120) # Setting Seed
classifier_cl <- naiveBayes(Species ~ ., data = train_cl)
classifier_cl
# Predicting on test data'
y_pred <- predict(classifier_cl, newdata = test_cl)
# Confusion Matrix
cm <- table(test_cl$Species, y_pred)
cm
# Model Evaluation
confusionMatrix(cm)在数据集上执行朴素贝叶斯
在包含 11 个人和 6 个变量或属性的数据集上使用朴素贝叶斯算法
Python3
# Installing Packages
install.packages("e1071")
install.packages("caTools")
install.packages("caret")
# Loading package
library(e1071)
library(caTools)
library(caret)
# Splitting data into train
# and test data
split <- sample.split(iris, SplitRatio = 0.7)
train_cl <- subset(iris, split == "TRUE")
test_cl <- subset(iris, split == "FALSE")
# Feature Scaling
train_scale <- scale(train_cl[, 1:4])
test_scale <- scale(test_cl[, 1:4])
# Fitting Naive Bayes Model
# to training dataset
set.seed(120) # Setting Seed
classifier_cl <- naiveBayes(Species ~ ., data = train_cl)
classifier_cl
# Predicting on test data'
y_pred <- predict(classifier_cl, newdata = test_cl)
# Confusion Matrix
cm <- table(test_cl$Species, y_pred)
cm
# Model Evaluation
confusionMatrix(cm)
输出:
- 模型分类器_cl:
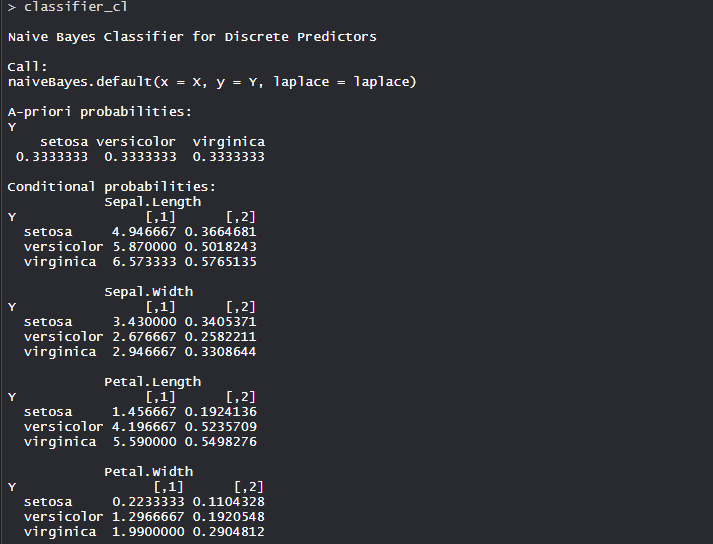
- 每个特征或变量的条件概率由模型单独创建。还计算了先验概率,这表明了我们数据的分布。
- 混淆矩阵:
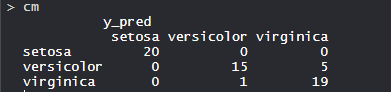
- 因此,20 个 Setosa 被正确归类为 Setosa。在 16 个 Versicolor 中,15 个 Versicolor 被正确归类为 Versicolor,1 个被归类为Virginica。在 24 个Virginica 中,19 个 virginica 被正确归类为 virginica,5 个被归类为 Versicolor。
- 模型评估:
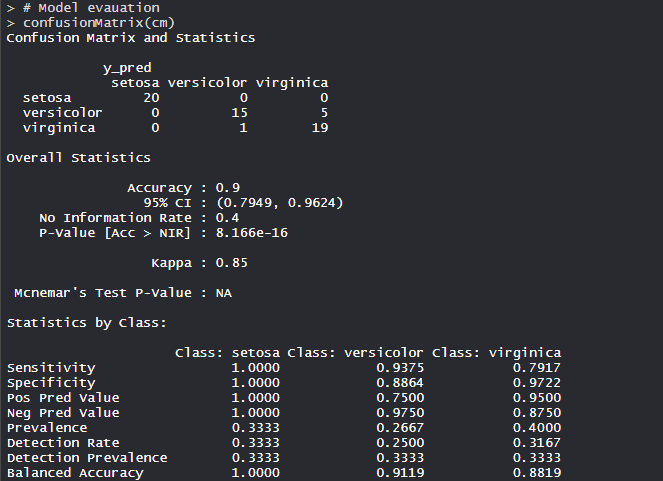
- 该模型实现了 90% 的准确度,p 值小于 1。具有灵敏度、特异性和平衡准确度,模型构建良好。
因此,朴素贝叶斯在行业中被广泛应用于情感分析、文档分类、垃圾邮件过滤等。