理解Python中的 for 循环
Pythonic for 循环与其他编程语言的 for 循环非常不同。 Python中的 for 循环用于遍历迭代器,但在其他语言中,它用于遍历条件。在本文中,我们将深入探讨 Pythonic for 循环,并见证这种差异背后的原因。让我们先熟悉一下循环陷阱:
for循环中的陷阱
如果你不知道“gotcha”是什么意思:编码中的“gotcha”是一个术语,用于描述一种编程语言的特性(比如 for-loop、 函数、return 语句等),它可能通过显示来玩诡计与预期结果不符的行为。这里有两个臭名昭著的 for 循环陷阱:
考虑这个例子:
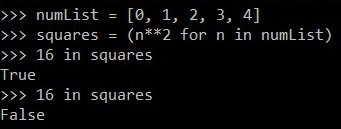
numList = [0, 1, 2, 3, 4]
squares = (n**2 for n in numList)
这里,变量squares包含numList元素的可迭代平方。如果我们检查 16 是否在squares中,我们得到 True,但如果我们再次检查,我们得到 False。
for循环的总和:
看看这个:
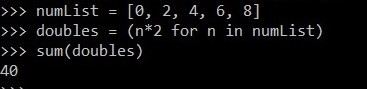
numList = [0, 2, 4, 6, 8]
doubles = (n * 2 for n in numList)
我们可以把它doubles一个列表或元组来查看它的元素。让我们计算双精度元素的总和。根据预期,结果应该是 40。
但是,我们得到的是 0。
为了理解这个异常,让我们首先看看 for 循环的“幕后”工作。
在for循环内部
如前所述,其他编程语言(如 C、C++、 Java)的 for 循环会循环一个条件。例如:
let numList = [0, 1, 2, 3, 4];
for (let i = 0; i < numList.length; i += 1) {
print(numList[i])
}
上面的代码是用 Javascript 编写的。正如所见,for 循环与我们在Python中看到的完全不同。这是因为我们在Python中所说的 for 循环实际上是一个“foreach”循环。 foreach 循环不像 for 循环那样维护计数器。 for 循环作用于可迭代元素的索引,而不是元素本身。但是 foreach 循环直接作用于元素而不是它们的索引,因此没有条件,没有初始化,也没有索引的增量。
numList = [0, 1, 2, 3, 4]
# for loop in Python
for n in numList:
print(n)
因此,可以说我们在Python中没有 for 循环,但我们有 foreach 循环,这些循环是作为 for 循环实现的!
有人可能会认为Python在底层使用索引在 for 循环中循环。但答案是否定的。让我们看一个例子来证明这一点:
我们将借助 while 循环来使用索引。
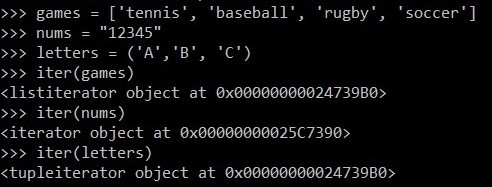
games = { 'tennis', 'baseball', 'rugby', 'soccer' }
i = 0
while i < len(games):
print(games[i])
i += 1
输出:

这证明Python没有使用索引进行循环,因此我们不能使用索引遍历所有内容。现在出现了一个简单的问题, Python使用什么来循环?答案是,迭代器!
迭代器
我们知道什么是可迭代对象(列表、字符串、元组等)。迭代器可以被认为是可迭代对象的电源。可迭代对象由迭代器组成,这有助于Python循环遍历可迭代对象。为了从可迭代对象中提取迭代器,我们使用 Python 的iter函数。
让我们看一个例子:
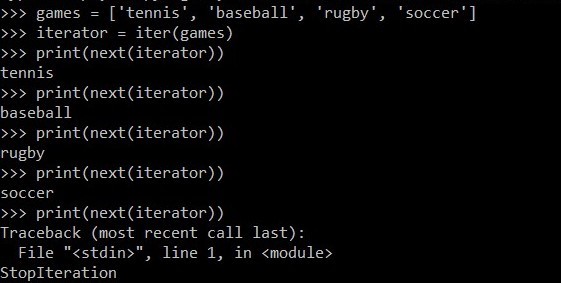
games = ['tennis', 'baseball', 'rugby', 'soccer']
iterator = iter(games)
# we use the next() function to
# print the next item of iterable
print(next(iterator))
print(next(iterator))
print(next(iterator))
如果我们在到达最后一项后继续使用next()函数,我们将得到一个 StopIteration 错误。
注意:一旦迭代器中的项目全部用完(迭代结束),它就会从内存中删除!
现在我们知道了循环是如何工作的,让我们尝试使用迭代器的强大功能创建我们自己的循环。
# Python program to demonstrate
# power of iterators
# creating our own loop
def newForLoop(iterable):
# extracting iterator out of iterable
iterator = iter(iterable)
# condition to check if looping is done
loopingFinished = False
while not loopingFinished:
try:
nextItem = next(iterator)
except StopIteration:
loopingFinished = True
else:
print(nextItem)
# Driver's code
newForLoop([1, 2, 3, 4])
输出:
1
2
3
4
我们需要了解迭代器,因为我们几乎每次都使用迭代器,甚至知道它。最常见的例子是生成器。生成器是迭代器。我们可以将迭代器的每一个函数都应用到生成器上。
numList = [0, 2, 4]
# creating a generator named "squares"
squares = (n**2 for n in numList)
print(next(squares))
print(next(squares))
print(next(squares))
输出:
0
4
16
解决循环问题
现在我们知道了 for 循环到底是什么以及它们在Python中是如何工作的,我们将从我们开始的地方结束这篇文章,也就是说,通过尝试推理出前面看到的循环陷阱。
部分耗尽迭代器:
当我们这样做时:
numList = [0, 1, 2, 3, 4]
squares = (n**2 for n in numList)
并询问 9 是否在squares中,我们得到了 True。但再次询问会返回 False。这是因为当我们第一次询问 9 是否存在时,它会遍历迭代器(生成器)以找到 9,并且我们知道一旦到达迭代器中的下一项,就会删除前一项。这就是为什么一旦我们找到 9,9 之前的所有数字都会被删除并再次询问返回 False。因此,我们已经部分用尽了迭代器。
完全耗尽迭代器:
在这段代码中:
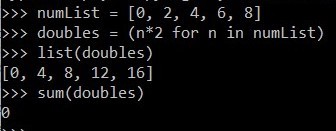
numList = [0, 2, 4, 6, 8]
doubles = (n * 2 for n in numList)
当我们将doubles转换为列表时,我们已经在迭代迭代器中的每个项目。因此,迭代器完全耗尽,最后没有任何项目留在其中。这就是元组上的函数sum()返回零的原因。如果我们在不将其转换为列表的情况下进行求和,它将返回正确的输出。