KNN 模型复杂度
KNN 是一种机器学习算法,用于分类(使用 KNearestClassifier)和回归(使用KNearestRegressor )问题。在 KNN 算法中,K 是超参数。选择正确的 K 值很重要。如果构建的模型具有低偏差和高方差,则称机器学习模型具有高模型复杂性。
我们知道,
- 高偏差和低方差 = 欠拟合模型。
- 低偏差和高方差 = 过拟合模型。 [表示高度复杂的模型]。
- 低偏差和低方差 = 最佳拟合模型。 [这是首选]。
- 高训练准确率和低测试准确率(样本外准确率)=高方差=过拟合模型=更多模型复杂度。
- 低训练精度和低测试精度(样本外精度)= 高偏差 = 欠拟合模型。
代码:了解 KNN 算法中的 K 值如何影响模型复杂度。
# This code may not run on GFG ide
# As required modules are not found.
# Import required modules
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split
import numpy as np
# Synthetically Create Data Set
plt.figure()
plt.title('SIMPLE-LINEAR-REGRESSION')
x, y = make_regression(
n_samples = 100, n_features = 1,
n_informative = 1, noise = 15, random_state = 3)
plt.scatter(x, y, color ='red', marker ='o', s = 30)
# Train the model.
knn = KNeighborsRegressor(n_neighbors = 7)
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = 0.2, random_state = 0)
knn.fit(x_train, y_train)
predict = knn.predict(x_test)
print('Test Accuracy:', knn.score(x_test, y_test))
print('Training Accuracy:', knn.score(x_train, y_train))
# Plot The Output
x_new = np.linspace(-3, 2, 100).reshape(100, 1)
predict_new = knn.predict(x_new)
plt.plot(
x_new, predict_new, color ='blue',
label ="K = 7")
plt.scatter(x_train, y_train, color ='red' )
plt.scatter(x_test, predict, marker ='^', s = 90)
plt.legend()
输出:
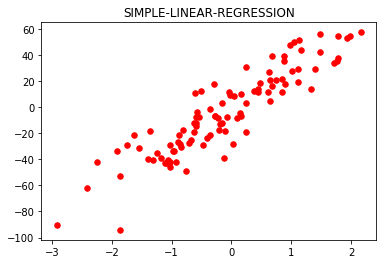
Test Accuracy: 0.6465919540035108
Training Accuracy: 0.8687977824212627
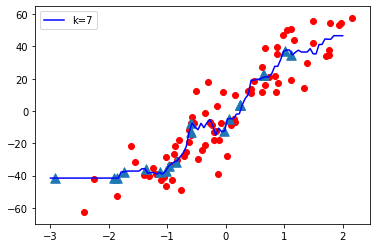
现在让我们将 K(超参数)的值从 Low 变为 High 并观察模型复杂度
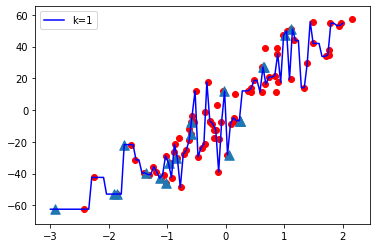
K = 1
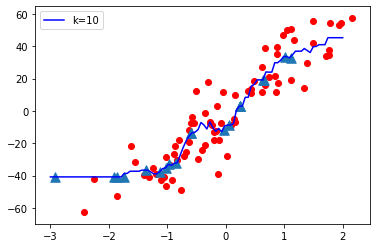
K = 10
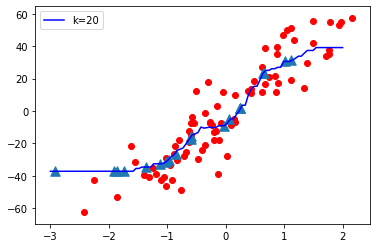
K = 20
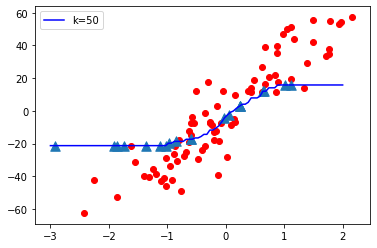
K = 50
K = 70
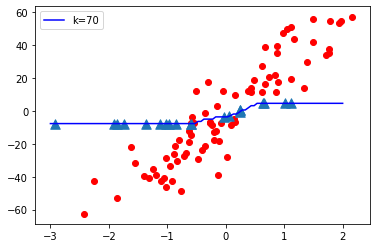
观察:
- 当 K 值较小即 K=1 时,模型复杂度较高(过拟合或高方差)。
- 当K值很大时,即K=70,模型复杂度降低(Under-fitting or High Bias)。
结论:
随着 K 值变小,模型复杂度增加,随着 K 值变大,模型复杂度降低。
代码:让我们考虑下图
# This code may not run on GFG
# As required modules are not found.
# To plot test accuracy and train accuracy Vs K value.
p = list(range(1, 31))
lst_test =[]
lst_train =[]
for i in p:
knn = KNeighborsRegressor(n_neighbors = i)
knn.fit(x_train, y_train)
z = knn.score(x_test, y_test)
t = knn.score(x_train, y_train)
lst_test.append(z)
lst_train.append(t)
plt.plot(p, lst_test, color ='red', label ='Test Accuracy')
plt.plot(p, lst_train, color ='b', label ='Train Accuracy')
plt.xlabel('K VALUES --->')
plt.title('FINDING BEST VALUE FOR K')
plt.legend()
输出:
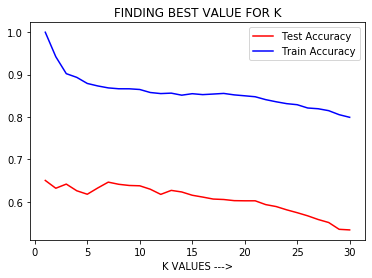
观察:
从上图中,我们可以得出结论,当 K 较小时,即 K=1,Training Accuracy 较高但 Test Accuracy 较低,这意味着模型过拟合(High Variance 或High Model Complexity )。当 K 值较大时,即 K=50,Training Accuracy 低,Test Accuracy 低,这意味着模型欠拟合(High Bias 或 Low Model Complexity)。
所以超参数调整是必要的,即在KNN算法中选择K的最佳值,模型具有低偏差和低方差,并产生具有高样本外精度的良好模型。
我们可以使用GridSearchCV或RandomSearchCv来找到超参数 K 的最佳值。
在评论中写代码?请使用 ide.geeksforgeeks.org,生成链接并在此处分享链接。