PySpark DataFrame - 过滤器
在本文中,我们将了解 PySpark Dataframe 中的过滤器位置。 Where() 是一种用于根据给定条件从 DataFrame 中过滤行的方法。 where() 方法是 filter() 方法的别名。这两种方法的操作完全相同。我们还可以使用 where() 方法在 DataFrame 列上应用单个和多个条件。
Syntax: DataFrame.where(condition)
示例 1:
以下示例是查看如何使用 where() 方法在 Dataframe 上应用单个条件。
Python3
# importing required module
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of Employees data
data = [
(121, ("Mukul", "Kumar"), 25000, 25),
(122, ("Arjun", "Singh"), 28000, 23),
(123, ("Rohan", "Verma"), 30000, 27),
(124, ("Manoj", "Singh"), 30000, 22),
(125, ("Robin", "Kumar"), 28000, 23)
]
# specify column names
columns = ['Employee ID', 'Name', 'Salary', 'Age']
# creating a dataframe from the lists of data
df = spark.createDataFrame(data, columns)
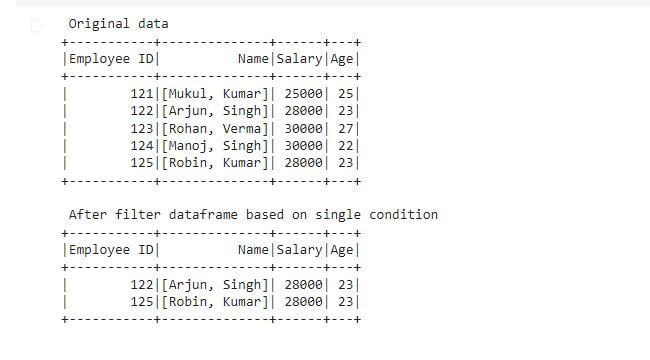
print(" Original data ")
df.show()
# filter dataframe based on single condition
df2 = df.where(df.Salary == 28000)
print(" After filter dataframe based on single condition ")
df2.show()Python3
# importing required module
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of Employees data
data = [
(121, ("Mukul", "Kumar"), 22000, 23),
(122, ("Arjun", "Singh"), 23000, 22),
(123, ("Rohan", "Verma"), 24000, 23),
(124, ("Manoj", "Singh"), 25000, 22),
(125, ("Robin", "Kumar"), 26000, 23)
]
# specify column names
columns = ['Employee ID', 'Name', 'Salary', 'Age']
# creating a dataframe from the lists of data
df = spark.createDataFrame(data, columns)
print(" Original data ")
df.show()
# filter dataframe based on multiple conditions
df2 = df.where((df.Salary > 22000) & (df.Age == 22))
print(" After filter dataframe based on multiple conditions ")
df2.show()Python3
# importing required module
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of Employees data
data = [
(121, "Mukul", 22000, 23),
(122, "Arjun", 23000, 22),
(123, "Rohan", 24000, 23),
(124, "Manoj", 25000, 22),
(125, "Robin", 26000, 23)
]
# specify column names
columns = ['Employee ID', 'Name', 'Salary', 'Age']
# creating a dataframe from the lists of data
df = spark.createDataFrame(data, columns)
print("Original Dataframe")
df.show()
# where() method with SQL Expression
df2 = df.where(df["Age"] == 23)
print(" After filter dataframe")
df2.show()Python3
# importing required module
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of Employees data
data = [
(121, "Mukul", 22000, 23),
(122, "Arjun", 23000, 22),
(123, "Rohan", 24000, 23),
(124, "Manoj", 25000, 22),
(125, "Robin", 26000, 23)
]
# specify column names
columns = ['Employee ID', 'Name', 'Salary', 'Age']
# creating a dataframe from the lists of data
df = spark.createDataFrame(data, columns)
print("Original Dataframe")
df.show()
# where() method with SQL Expression
df2 = df.where("Age == 22")
print(" After filter dataframe")
df2.show()输出:
示例 2:
以下示例是了解如何使用 where() 方法在 Dataframe 上应用多个条件。
Python3
# importing required module
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of Employees data
data = [
(121, ("Mukul", "Kumar"), 22000, 23),
(122, ("Arjun", "Singh"), 23000, 22),
(123, ("Rohan", "Verma"), 24000, 23),
(124, ("Manoj", "Singh"), 25000, 22),
(125, ("Robin", "Kumar"), 26000, 23)
]
# specify column names
columns = ['Employee ID', 'Name', 'Salary', 'Age']
# creating a dataframe from the lists of data
df = spark.createDataFrame(data, columns)
print(" Original data ")
df.show()
# filter dataframe based on multiple conditions
df2 = df.where((df.Salary > 22000) & (df.Age == 22))
print(" After filter dataframe based on multiple conditions ")
df2.show()
输出:

示例 3:
下面的例子是要知道如何使用 where() 方法和 Column 条件来过滤 Dataframe。我们将在特定条件下使用 where() 方法。
Python3
# importing required module
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of Employees data
data = [
(121, "Mukul", 22000, 23),
(122, "Arjun", 23000, 22),
(123, "Rohan", 24000, 23),
(124, "Manoj", 25000, 22),
(125, "Robin", 26000, 23)
]
# specify column names
columns = ['Employee ID', 'Name', 'Salary', 'Age']
# creating a dataframe from the lists of data
df = spark.createDataFrame(data, columns)
print("Original Dataframe")
df.show()
# where() method with SQL Expression
df2 = df.where(df["Age"] == 23)
print(" After filter dataframe")
df2.show()
输出:

示例 4:
下面的例子是要知道如何使用带有 SQL 表达式的 where() 方法。
Python3
# importing required module
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of Employees data
data = [
(121, "Mukul", 22000, 23),
(122, "Arjun", 23000, 22),
(123, "Rohan", 24000, 23),
(124, "Manoj", 25000, 22),
(125, "Robin", 26000, 23)
]
# specify column names
columns = ['Employee ID', 'Name', 'Salary', 'Age']
# creating a dataframe from the lists of data
df = spark.createDataFrame(data, columns)
print("Original Dataframe")
df.show()
# where() method with SQL Expression
df2 = df.where("Age == 22")
print(" After filter dataframe")
df2.show()
输出:
