超参数调优
机器学习模型被定义为具有许多需要从数据中学习的参数的数学模型。通过使用现有数据训练模型,我们能够拟合模型参数。
但是,还有另一种参数,称为超参数,不能直接从常规训练过程中学习。它们通常在实际训练过程开始之前固定。这些参数表达了模型的重要属性,例如它的复杂性或它应该学习的速度。
模型超参数的一些示例包括:
- Logistic 回归分类器中的惩罚,即 L1 或 L2 正则化
- 训练神经网络的学习率。
- 支持向量机的 C 和 sigma 超参数。
- k 最近邻中的 k。
本文的目的是探索为机器学习模型调整超参数的各种策略。
模型可以有许多超参数,找到最佳参数组合可以视为搜索问题。超参数调整的两个最佳策略是:
- GridSearchCV
- 随机搜索CV
GridSearchCV
在 GridSearchCV 方法中,机器学习模型针对一系列超参数值进行评估。这种方法称为GridSearchCV ,因为它从超参数值网格中搜索最佳超参数集。
例如,如果我们要设置逻辑回归分类器模型的两个超参数 C 和 Alpha,具有不同的值集。网格搜索技术将使用超参数的所有可能组合构建模型的多个版本,并返回最佳版本。
如图所示,对于 C = [0.1, 0.2, 0.3, 0.4, 0.5] 和 Alpha = [0.1, 0.2, 0.3, 0.4]。
对于C=0.3 和 Alpha=0.2的组合,性能得分为0.726(Highest) ,因此被选中。 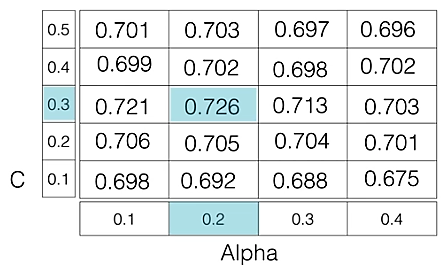
以下代码说明了如何使用 GridSearchCV
# Necessary imports
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Creating the hyperparameter grid
c_space = np.logspace(-5, 8, 15)
param_grid = {'C': c_space}
# Instantiating logistic regression classifier
logreg = LogisticRegression()
# Instantiating the GridSearchCV object
logreg_cv = GridSearchCV(logreg, param_grid, cv = 5)
logreg_cv.fit(X, y)
# Print the tuned parameters and score
print("Tuned Logistic Regression Parameters: {}".format(logreg_cv.best_params_))
print("Best score is {}".format(logreg_cv.best_score_))
输出:
Tuned Logistic Regression Parameters: {‘C’: 3.7275937203149381}
Best score is 0.7708333333333334
缺点:GridSearchCV 将遍历超参数的所有中间组合,这使得网格搜索的计算成本非常高。随机搜索CV
RandomizedSearchCV 解决了 GridSearchCV 的缺点,因为它只通过固定数量的超参数设置。它以随机方式在网格内移动以找到最佳的超参数集。这种方法减少了不必要的计算。
以下代码说明了如何使用 RandomizedSearchCV
# Necessary imports
from scipy.stats import randint
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import RandomizedSearchCV
# Creating the hyperparameter grid
param_dist = {"max_depth": [3, None],
"max_features": randint(1, 9),
"min_samples_leaf": randint(1, 9),
"criterion": ["gini", "entropy"]}
# Instantiating Decision Tree classifier
tree = DecisionTreeClassifier()
# Instantiating RandomizedSearchCV object
tree_cv = RandomizedSearchCV(tree, param_dist, cv = 5)
tree_cv.fit(X, y)
# Print the tuned parameters and score
print("Tuned Decision Tree Parameters: {}".format(tree_cv.best_params_))
print("Best score is {}".format(tree_cv.best_score_))
输出:
Tuned Decision Tree Parameters: {‘min_samples_leaf’: 5, ‘max_depth’: 3, ‘max_features’: 5, ‘criterion’: ‘gini’}
Best score is 0.7265625