将分类变量转换为虚拟变量
所有的统计和机器学习模型都建立在数据的基础上。将与特定问题相关的分组或复合实体称为数据集。这些数据集由自变量或特征和因变量或标签组成。所有这些变量都可以分为两类数据:定量的和分类的。
在本文中,我们将讨论将分类变量转换为虚拟变量的各种方法,这是数据预处理的重要组成部分,它本身就是机器学习或统计模型的一个组成部分。分类变量可以进一步细分为以下几类:
- 二元或二分法本质上是只能有两种结果的变量,例如赢/输、开/关等。
- 名义变量用于表示没有特定排名的组,例如颜色、品牌等。
- 序数变量代表具有指定排名顺序的组,例如比赛获胜者、应用评级等。
虚拟变量充当分类变量中某个类别是否存在的指标。通常的约定规定 0 代表缺席,而 1 代表存在。将类别变量转换为虚拟变量导致形成二维二进制矩阵,其中每一列代表一个特定类别。下面的例子将进一步阐明转换的过程。
包含分类变量的数据集:OUTLOOK TEMPERATURE HUMIDITY WINDY Rainy Hot High No Rainy Hot High Yes Overcast Hot High No Sunny Mild High No Sunny Cool Normal No
包含虚拟变量的数据集:RAINY OVERCAST SUNNY HOT MILD COOL HIGH NORMAL YES NO 1 0 0 1 0 0 1 0 0 1 1 0 0 1 0 0 1 0 1 0 0 1 0 1 0 0 1 0 0 1 0 0 1 0 1 0 1 0 0 1 0 0 1 0 0 1 0 1 0 1
解释:
上述数据集包含四个分类列:OUTLOOK、TEMPERATURE、HUMIDITY、WINDY。
让我们考虑由两个类别组成的列 WINDY:YES 和 NO。因此,在包含虚拟变量的数据集中,WINDY 列被两列替换,每列代表类别:YES 和 NO。现在将 YES 和 NO 列的行与 WINDY 进行比较,我们将 YES 标记为 0,表示 YES 不存在,1 表示存在。对 NO 列也是如此。所有分类列均采用此方法。需要注意的重要一点是,每个分类列都被它在包含虚拟变量的数据集中拥有的唯一类别的数量替换。
在本文中,我们将探索将分类变量转换为虚拟变量的三种方法。
这些方法如下:
- 使用来自 sklearn 的 LabelBinarizer
- 使用 category_encoders 中的 BinaryEncoder
- 使用 pandas 库的 get_dummies()函数
创建数据集:
第一步是创建数据集。该数据集包含 4 个分类列,名称分别为 OUTLOOK、TEMPERATURE、HUMIDITY、WINDY。下面是创建数据集的代码。我们使用 pandas.DataFrame() 和字典制作这个数据集。
Python3
# code to create the dataset
# importing the libraries
import pandas as pd
# creating the dictionary
dictionary = {'OUTLOOK': ['Rainy', 'Rainy',
'Overcast', 'Sunny',
'Sunny', 'Sunny',
'Overcast', 'Rainy',
'Rainy', 'Sunny',
'Rainy', 'Overcast',
'Overcast', 'Sunny'],
'TEMPERATURE': ['Hot', 'Hot', 'Hot',
'Mild', 'Cool',
'Cool', 'Cool',
'Mild', 'Cool',
'Mild', 'Mild',
'Mild', 'Hot', 'Mild'],
'HUMIDITY': ['High', 'High', 'High',
'High', 'Normal', 'Normal',
'Normal', 'High', 'Normal',
'Normal', 'Normal', 'High',
'Normal', 'High'],
'WINDY': ['No', 'Yes', 'No', 'No', 'No',
'Yes', 'Yes', 'No', 'No',
'No', 'Yes', 'Yes', 'No',
'Yes']}
# converting the dictionary to DataFrame
df = pd.DataFrame(dictionary)
display(df)Python3
# importing the libraries
from sklearn.preprocessing import LabelBinarizer
# creating a copy of the
# original data frame
df1 = df.copy()
# creating an object
# of the LabelBinarizer
label_binarizer = LabelBinarizer()
# fitting the column
# TEMPERATURE to LabelBinarizer
label_binarizer_output = label_binarizer.fit_transform( df1['TEMPERATURE'])
# creating a data frame from the object
result_df = pd.DataFrame(label_binarizer_output,
columns = label_binarizer.classes_)
display(result_df)Python3
# importing the libraries
import category_encoders as cat_encoder
# creating a copy of the original data frame
df2 = df.copy()
# creating an object BinaryEncoder
# this code calls all columns
# we can specify specific columns as well
encoder = cat_encoder.BinaryEncoder(cols = df2.columns)
# fitting the columns to a data frame
df_category_encoder = encoder.fit_transform( df2 )
display(df_category_encoder)Python3
# importing the libraries
import pandas as pd
# creating a copy of the original data frame
df3 = df.copy()
# calling the get_dummies method
# the first parameter mentions the
# the name of the data frame to store the
# new data frame in
# the second parameter is the list of
# columns which if not mentioned
# returns the dummies for all
# categorical columns
df3 = pd.get_dummies(df3,
columns = ['WINDY', 'OUTLOOK'])
display(df3)输出:

以上是我们将用于未来方法的数据集。
方法一:
使用这种方法,我们使用来自 sklearn 的 LabelBinarizer,它一次将一个分类列转换为具有虚拟变量的数据框。如果存在多个 Categorical 列,则可以将此数据框附加到主数据框。
蟒蛇3
# importing the libraries
from sklearn.preprocessing import LabelBinarizer
# creating a copy of the
# original data frame
df1 = df.copy()
# creating an object
# of the LabelBinarizer
label_binarizer = LabelBinarizer()
# fitting the column
# TEMPERATURE to LabelBinarizer
label_binarizer_output = label_binarizer.fit_transform( df1['TEMPERATURE'])
# creating a data frame from the object
result_df = pd.DataFrame(label_binarizer_output,
columns = label_binarizer.classes_)
display(result_df)
输出:
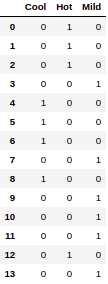
TEMPERATURE 列的换算
同样,我们也可以转换其他分类列。
方法二:
使用 category_encoders 库中的 BinaryEncoder。使用这种方法,我们可以一次性将多个分类列转换为虚拟变量。
category_encoders: category_encoders 是在 scikit-learn-transformers 库下开发的Python库。该库的主要目标是将分类变量转换为可量化的数字变量。这个库有很多优点,比如很容易与 sklearn 转换器兼容,这使得它们可以很容易地训练和存储在可序列化的文件中,例如 pickle 以备后用。这个库在处理数据框架方面也很有效,这在处理机器学习和统计模型时非常有用。它还提供了大量的从分类变量到数值变量的转换方法,可以分为有监督和无监督。
对于安装,在终端中运行此命令:
pip install category_encoders对于康达:
conda install -c conda-forge category_encoders代码:
蟒蛇3
# importing the libraries
import category_encoders as cat_encoder
# creating a copy of the original data frame
df2 = df.copy()
# creating an object BinaryEncoder
# this code calls all columns
# we can specify specific columns as well
encoder = cat_encoder.BinaryEncoder(cols = df2.columns)
# fitting the columns to a data frame
df_category_encoder = encoder.fit_transform( df2 )
display(df_category_encoder)
输出:
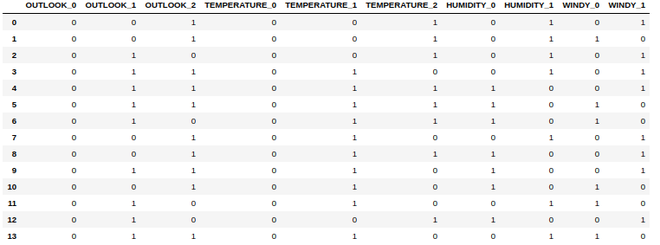
从所有分类列创建的数据框
方法三:
在这种方法下,我们部署了最简单的方法,通过使用 pandas 库的 get_dummies() 方法将数据框中所有可能的分类列转换为虚拟列。
我们可以指定默认情况下获取虚拟列的列,它将所有可能的分类列转换为它们的虚拟列。
蟒蛇3
# importing the libraries
import pandas as pd
# creating a copy of the original data frame
df3 = df.copy()
# calling the get_dummies method
# the first parameter mentions the
# the name of the data frame to store the
# new data frame in
# the second parameter is the list of
# columns which if not mentioned
# returns the dummies for all
# categorical columns
df3 = pd.get_dummies(df3,
columns = ['WINDY', 'OUTLOOK'])
display(df3)
输出:
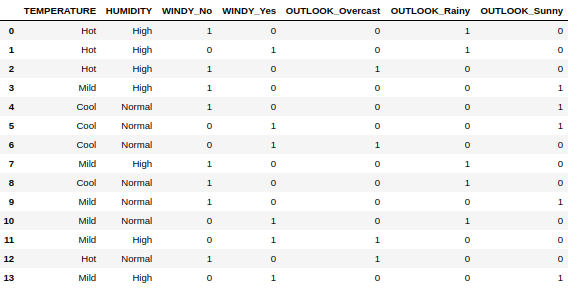
对 WINDY 和 OUTLOOK 列使用 get_dummies()