自然语言处理 |分块规则
以下是分块涉及的步骤 -
- 将句子转换为扁平树。
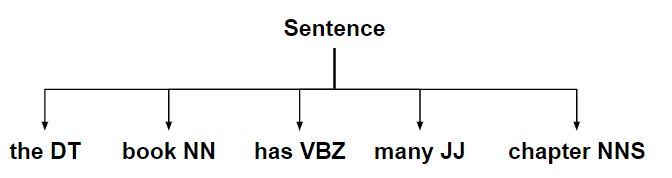
- 使用这棵树创建块字符串。
- 通过使用 RegexpParser 解析语法来创建 RegexpChunkParser。
- 将创建的块规则应用于将句子匹配成块的 ChunkString。

- 使用定义的块规则将较大的块拆分为较小的块。
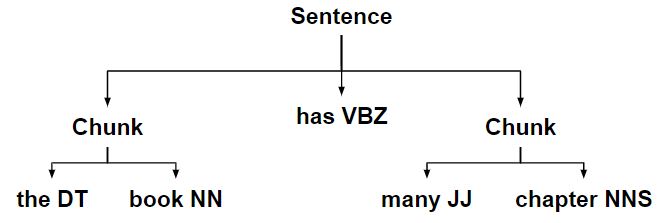
- 然后将 ChunkString 转换回具有两个块子树的树。
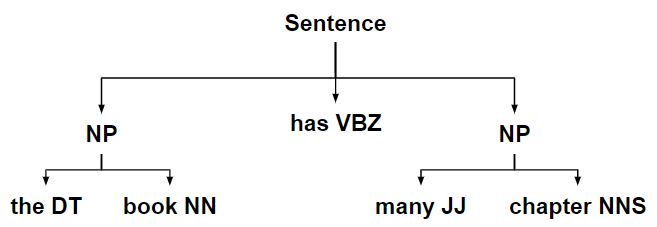
代码 #1:通过应用每个规则来修改 ChunkString。
Python3
# Loading Libraries
from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule
from nltk.tree import Tree
# ChunkString() starts with the flat tree
tree = Tree('S', [('the', 'DT'), ('book', 'NN'),
('has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')])
# Initializing ChunkString()
chunk_string = ChunkString(tree)
print ("Chunk String : ", chunk_string)
# Initializing ChunkRule
chunk_rule = ChunkRule('<.*>*', 'chunk determiners and nouns')
chunk_rule.apply(chunk_string)
print ("\nApplied ChunkRule : ", chunk_string)
# Another ChinkRule
ir = ChinkRule('', 'chink verbs')
ir.apply(chunk_string)
print ("\nApplied ChinkRule : ", chunk_string, "\n")
# Back to chunk sub-tree
chunk_string.to_chunkstruct() Python3
# Loading Libraries
from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule
from nltk.tree import Tree
from nltk.chunk import RegexpChunkParser
# ChunkString() starts with the flat tree
tree = Tree('S', [('the', 'DT'), ('book', 'NN'),
('has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')])
# Initializing ChunkRule
chunk_rule = ChunkRule('<.*>*', 'chunk determiners and nouns')
# Another ChinkRule
chink_rule = ChinkRule('', 'chink verbs')
# Applying RegexpChunkParser
chunker = RegexpChunkParser([chunk_rule, chink_rule])
chunker.parse(tree) Python3
# Loading Libraries
from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule
from nltk.tree import Tree
from nltk.chunk import RegexpChunkParser
# ChunkString() starts with the flat tree
tree = Tree('S', [('the', 'DT'), ('book', 'NN'),
('has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')])
# Initializing ChunkRule
chunk_rule = ChunkRule('<.*>*', 'chunk determiners and nouns')
# Another ChinkRule
chink_rule = ChinkRule('', 'chink verbs')
# Applying RegexpChunkParser
chunker = RegexpChunkParser([chunk_rule, chink_rule], chunk_label ='CP')
chunker.parse(tree) 输出:
Chunk String : <
Applied ChunkRule : { }
Applied ChinkRule : { } { }
Tree('S', [Tree('CHUNK', [('the', 'DT'), ('book', 'NN')]),
('has', 'VBZ'), Tree('CHUNK', [('many', 'JJ'), ('chapters', 'NNS')])]) 注意:此代码的工作方式与上述 ChunkRule 步骤中解释的方式完全相同。代码 #2:如何直接使用 RegexpChunkParser 执行此任务。
Python3
# Loading Libraries
from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule
from nltk.tree import Tree
from nltk.chunk import RegexpChunkParser
# ChunkString() starts with the flat tree
tree = Tree('S', [('the', 'DT'), ('book', 'NN'),
('has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')])
# Initializing ChunkRule
chunk_rule = ChunkRule('<.*>*', 'chunk determiners and nouns')
# Another ChinkRule
chink_rule = ChinkRule('', 'chink verbs')
# Applying RegexpChunkParser
chunker = RegexpChunkParser([chunk_rule, chink_rule])
chunker.parse(tree)
输出:
Tree('S', [Tree('CHUNK', [('the', 'DT'), ('book', 'NN')]),
('has', 'VBZ'), Tree('CHUNK', [('many', 'JJ'), ('chapters', 'NNS')])])
代码#3:使用不同的 ChunkType 进行解析。
Python3
# Loading Libraries
from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule
from nltk.tree import Tree
from nltk.chunk import RegexpChunkParser
# ChunkString() starts with the flat tree
tree = Tree('S', [('the', 'DT'), ('book', 'NN'),
('has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')])
# Initializing ChunkRule
chunk_rule = ChunkRule('<.*>*', 'chunk determiners and nouns')
# Another ChinkRule
chink_rule = ChinkRule('', 'chink verbs')
# Applying RegexpChunkParser
chunker = RegexpChunkParser([chunk_rule, chink_rule], chunk_label ='CP')
chunker.parse(tree)
输出:
Tree('S', [Tree('CP', [('the', 'DT'), ('book', 'NN')]), ('has', 'VBZ'),
Tree('CP', [('many', 'JJ'), ('chapters', 'NNS')])])