- 使用 python 代码示例进行自然语言处理
- 自然语言处理教程
- 自然语言处理教程(1)
- 自然语言处理的应用
- 自然语言处理的应用(1)
- 自然语言处理简介(1)
- 自然语言处理-简介(1)
- 自然语言处理简介
- 自然语言处理-简介
- 讨论自然语言处理
- 自然语言处理 - 概述
- 自然语言处理 - 概述(1)
- 语法树 - 自然语言处理
- 语法树 - 自然语言处理(1)
- AI-自然语言处理(1)
- AI-自然语言处理
- 自然语言处理 |可能的词标签(1)
- 自然语言处理 |可能的词标签
- 自然语言处理-初始(1)
- 自然语言处理-初始
- 带有Python的AI –自然语言处理(1)
- 带有Python的AI –自然语言处理
- 自然语言处理-有用的资源
- 自然语言处理-有用的资源(1)
- 自然语言处理 |拆分和合并块(1)
- 自然语言处理 |拆分和合并块
- 自然语言处理-语义分析
- 自然语言处理 |位置标签提取(1)
- 自然语言处理 |位置标签提取
📅 最后修改于: 2020-11-23 04:45:42 🧑 作者: Mango
在本章中,我们将学习使用Python语言处理。
以下功能使Python与其他语言不同-
-
Python被解释了-我们不需要在执行之前编译我们的Python程序,因为解释器会在运行时处理Python 。
-
交互式-我们可以直接与解释器进行交互以编写我们的Python程序。
-
面向对象– Python是在本质上面向对象的,它使这种语言更容易地编写程序,因为与编程它封装对象中代码的这种技术的帮助。
-
初学者可以轻松学习Python也被称为初学者的语言,因为它非常易于理解,并且支持各种应用程序的开发。
先决条件
Python 3的最新版本是Python 3.7.1,可用于Windows,Mac OS和大多数Linux OS。
-
对于Windows,我们可以转到链接www。 Python.org / downloads / windows /下载并安装Python。
-
对于MAC OS,我们可以使用链接www。 Python.org / downloads / mac-osx / 。
-
对于Linux,不同版本的Linux使用不同的软件包管理器来安装新软件包。
-
例如,要在Ubuntu Linux上安装Python 3,我们可以从终端使用以下命令-
-
$sudo apt-get install python3-minimal
要研究有关Python编程的更多信息,请阅读Python 3基本教程– Python 3
NLTK入门
我们将使用Python库NLTK(自然语言工具包)进行英语文本分析。自然语言工具包(NLTK)是Python库的集合,这些库专门设计用于识别和标记在自然语言(如英语)文本中找到的语音部分。
安装NLTK
在开始使用NLTK之前,我们需要先安装它。借助以下命令,我们可以将其安装在Python环境中-
pip install nltk
如果我们使用的是Anaconda,则可以使用以下命令为NLTK构建Conda软件包-
conda install -c anaconda nltk
下载NLTK的数据
安装NLTK之后,另一个重要任务是下载其预设的文本存储库,以便可以轻松使用它。但是,在此之前,我们需要以导入其他Python模块的方式导入NLTK。以下命令将帮助我们导入NLTK-
import nltk
现在,在以下命令的帮助下下载NLTK数据-
nltk.download()
安装所有可用的NLTK软件包将花费一些时间。
其他必要配套
其他一些Python软件包(如gensim和pattern)对于文本分析以及使用NLTK构建自然语言处理应用程序也是非常必要的。软件包可以如下所示安装-
Gensim
gensim是一个健壮的语义建模库,可以用于许多应用程序。我们可以通过以下命令安装它-
pip install gensim
模式
它可以用来使gensim包正常工作。以下命令有助于安装模式-
pip install pattern
代币化
令牌化可以定义为将给定文本分解为称为令牌的较小单元的过程。单词,数字或标点符号可以是标记。也可以称为分词。
例
输入-床和椅子是家具的类型。

我们有NLTK提供的用于令牌化的不同软件包。我们可以根据需要使用这些软件包。软件包及其安装细节如下-
sent_tokenize包
该软件包可用于将输入文本分为句子。我们可以使用以下命令导入它-
from nltk.tokenize import sent_tokenize
word_tokenize软件包
该包可用于将输入文本分为单词。我们可以使用以下命令导入它-
from nltk.tokenize import word_tokenize
WordPunctTokenizer程序包
该软件包可用于将输入文本分为单词和标点符号。我们可以使用以下命令导入它-
from nltk.tokenize import WordPuncttokenizer
抽干
由于语法原因,语言包含很多变化。语言,英语以及其他语言也具有不同形式的单词,这是一种变化形式。例如,民主,民主和民主化之类的词。对于机器学习项目,机器要理解这些不同的词(如上)具有相同的基本形式,这一点非常重要。因此,在分析文本时提取单词的基本形式非常有用。
词干处理是一种启发式过程,可通过切掉单词的结尾来帮助提取单词的基本形式。
NLTK模块提供的用于阻止的不同软件包如下-
PorterStemmer包装
此词干包使用Porter算法提取单词的基本形式。借助以下命令,我们可以导入该包-
from nltk.stem.porter import PorterStemmer
例如, “ write”将是单词“ writing”的输出,作为此词干的输入。
LancasterStemmer软件包
此词干包使用Lancaster的算法来提取单词的基本形式。借助以下命令,我们可以导入该包-
from nltk.stem.lancaster import LancasterStemmer
例如, “书面”将是单词“写作”的输出,作为此词干的输入。
SnowballStemmer包装
此词干包使用Snowball的算法来提取单词的基本形式。借助以下命令,我们可以导入该包-
from nltk.stem.snowball import SnowballStemmer
例如, “ write”将是单词“ writing”的输出,作为此词干的输入。
合法化
这是提取单词基本形式的另一种方法,通常旨在通过词汇和词法分析来消除词尾变化。词形化后,任何单词的基本形式称为词形。
NLTK模块提供以下软件包以进行词法化-
WordNetLemmatizer程序包
该软件包将提取单词的基本形式,具体取决于它是用作名词还是用作动词。以下命令可用于导入此软件包-
from nltk.stem import WordNetLemmatizer
计数POS标签-整理
可以借助分块来识别语音部分(POS)和短短语。它是自然语言处理中的重要过程之一。正如我们所知道的,创建令牌的令牌化过程一样,分块实际上是对这些令牌进行标记。换句话说,可以说我们可以借助分块过程来获得句子的结构。
例
在以下示例中,我们将使用NLTK Python模块实现名词短语分块,这是一种分块的类别,可以在句子中找到名词短语分块。
考虑以下步骤以实现名词短语组块-
步骤1:块语法定义
在这一步中,我们需要定义用于分块的语法。它由规则组成,我们需要遵循这些规则。
步骤2:建立区块解析器
接下来,我们需要创建一个块解析器。它将解析语法并给出输出。
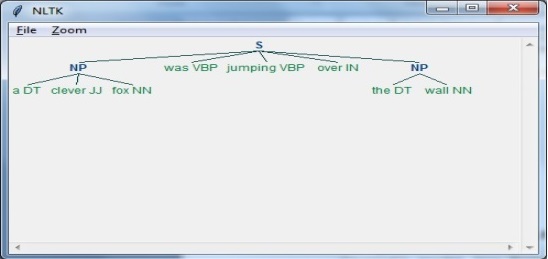
步骤3:输出
在此步骤中,我们将以树格式获取输出。
运行NLP脚本
首先导入NLTK包-
import nltk
现在,我们需要定义句子。
这里,
-
DT是决定因素
-
VBP是动词
-
JJ是形容词
-
IN是介词
-
NN是名词
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
接下来,应以正则表达式的形式给出语法。
grammar = "NP:{?*}"
现在,我们需要定义一个语法分析器。
parser_chunking = nltk.RegexpParser(grammar)
现在,解析器将解析句子,如下所示:
parser_chunking.parse(sentence)
接下来,输出将在变量中如下所示:
Output = parser_chunking.parse(sentence)
现在,以下代码将帮助您以树的形式绘制输出。
output.draw()