使用Python抓取网络流量中的数据
在本文中,我们将学习如何使用Python网络流量中的数据。
需要的模块
- selenium : Selenium是一个用于控制 Web 浏览器的可移植框架。
- time:该模块提供各种与时间相关的功能。
- json :此模块需要处理 JSON 数据。
- browsermobproxy:这个模块帮助我们从网络流量中获取 HAR 文件。
我们可以通过两种方式来清除网络流量数据。
方法一:使用selenium的get_log()方法
首先,根据您的 chrome 浏览器的版本,从这里下载并提取chrome webdriver并复制可执行路径。
方法:
- 从selenium模块导入DesiredCapabilities并启用性能日志记录。
- 使用executable_path和默认的chrome-options启动chrome webdriver或向它添加一些参数 和 修改后的desired_capabilities 。
- 使用driver.get()向网站发送 GET 请求并等待几秒钟以加载页面。
句法:
driver.get(url)
- 使用driver.get_log()获取性能日志并将其存储在变量中。
句法:
driver.get_log(“performance”)
- 迭代每个日志并使用json.loads()对其进行解析以过滤所有与网络相关的日志。
- 通过使用json.dumps()转换为 JSON字符串,将过滤后的日志写入 JSON 文件。
例子:
Python3
# Import the required modules
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
import json
# Main Function
if __name__ == "__main__":
# Enable Performance Logging of Chrome.
desired_capabilities = DesiredCapabilities.CHROME
desired_capabilities["goog:loggingPrefs"] = {"performance": "ALL"}
# Create the webdriver object and pass the arguments
options = webdriver.ChromeOptions()
# Chrome will start in Headless mode
options.add_argument('headless')
# Ignores any certificate errors if there is any
options.add_argument("--ignore-certificate-errors")
# Startup the chrome webdriver with executable path and
# pass the chrome options and desired capabilities as
# parameters.
driver = webdriver.Chrome(executable_path="C:/chromedriver.exe",
chrome_options=options,
desired_capabilities=desired_capabilities)
# Send a request to the website and let it load
driver.get("https://www.geeksforgeeks.org/")
# Sleeps for 10 seconds
time.sleep(10)
# Gets all the logs from performance in Chrome
logs = driver.get_log("performance")
# Opens a writable JSON file and writes the logs in it
with open("network_log.json", "w", encoding="utf-8") as f:
f.write("[")
# Iterates every logs and parses it using JSON
for log in logs:
network_log = json.loads(log["message"])["message"]
# Checks if the current 'method' key has any
# Network related value.
if("Network.response" in network_log["method"]
or "Network.request" in network_log["method"]
or "Network.webSocket" in network_log["method"]):
# Writes the network log to a JSON file by
# converting the dictionary to a JSON string
# using json.dumps().
f.write(json.dumps(network_log)+",")
f.write("{}]")
print("Quitting Selenium WebDriver")
driver.quit()
# Read the JSON File and parse it using
# json.loads() to find the urls containing images.
json_file_path = "network_log.json"
with open(json_file_path, "r", encoding="utf-8") as f:
logs = json.loads(f.read())
# Iterate the logs
for log in logs:
# Except block will be accessed if any of the
# following keys are missing.
try:
# URL is present inside the following keys
url = log["params"]["request"]["url"]
# Checks if the extension is .png or .jpg
if url[len(url)-4:] == ".png" or url[len(url)-4:] == ".jpg":
print(url, end='\n\n')
except Exception as e:
passPython3
# Import the required modules
from selenium import webdriver
from browsermobproxy import Server
import time
import json
# Main Function
if __name__ == "__main__":
# Enter the path of bin folder by
# extracting browsermob-proxy-2.1.4-bin
path_to_browsermobproxy = "C:\\browsermob-proxy-2.1.4\\bin\\"
# Start the server with the path and port 8090
server = Server(path_to_browsermobproxy
+ "browsermob-proxy", options={'port': 8090})
server.start()
# Create the proxy with following parameter as true
proxy = server.create_proxy(params={"trustAllServers": "true"})
# Create the webdriver object and pass the arguments
options = webdriver.ChromeOptions()
# Chrome will start in Headless mode
options.add_argument('headless')
# Ignores any certificate errors if there is any
options.add_argument("--ignore-certificate-errors")
# Setting up Proxy for chrome
options.add_argument("--proxy-server={0}".format(proxy.proxy))
# Startup the chrome webdriver with executable path and
# the chrome options as parameters.
driver = webdriver.Chrome(executable_path="C:/chromedriver.exe",
chrome_options=options)
# Create a new HAR file of the following domain
# using the proxy.
proxy.new_har("geeksforgeeks.org/")
# Send a request to the website and let it load
driver.get("https://www.geeksforgeeks.org/")
# Sleeps for 10 seconds
time.sleep(10)
# Write it to a HAR file.
with open("network_log1.har", "w", encoding="utf-8") as f:
f.write(json.dumps(proxy.har))
print("Quitting Selenium WebDriver")
driver.quit()
# Read HAR File and parse it using JSON
# to find the urls containing images.
har_file_path = "network_log1.har"
with open(har_file_path, "r", encoding="utf-8") as f:
logs = json.loads(f.read())
# Store the network logs from 'entries' key and
# iterate them
network_logs = logs['log']['entries']
for log in network_logs:
# Except block will be accessed if any of the
# following keys are missing
try:
# URL is present inside the following keys
url = log['request']['url']
# Checks if the extension is .png or .jpg
if url[len(url)-4:] == '.png' or url[len(url)-4:] == '.jpg':
print(url, end="\n\n")
except Exception as e:
# print(e)
pass输出:
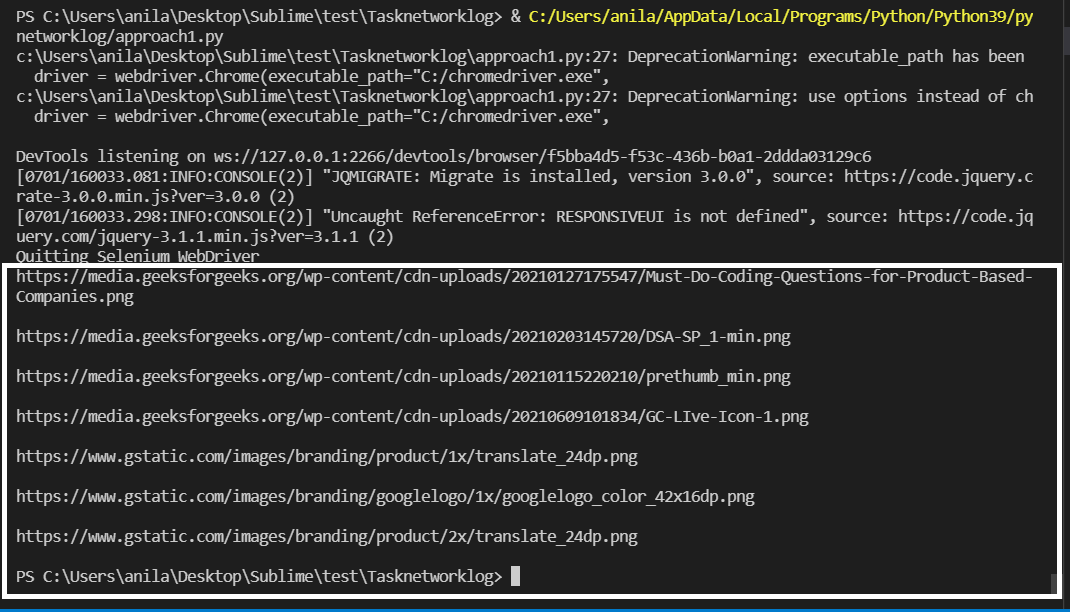
图像 URL 在上面突出显示。
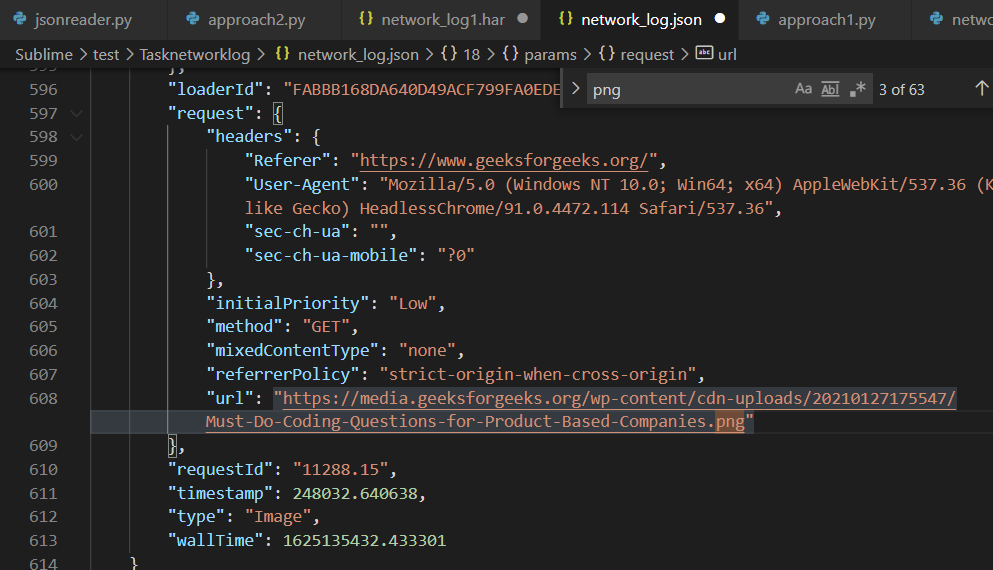
network_log.json 包含图像 URL
方法二:使用browsermobproxy从浏览器的网络标签中抓取HAR文件
为此,需要满足以下要求。
- 从这里下载并安装Java v8
- 从这里下载并解压browsermobproxy并复制 bin 文件夹的路径。
- 使用终端中的命令使用 pip 安装browsermob-proxy :
pip install browsermob-proxy
- 根据您的 chrome 浏览器版本,从这里下载并提取chrome webdriver ,并复制可执行路径。
方法:
- 从browsermobproxy导入 Server 模块,并使用复制的 bin 文件夹路径启动 Server 并将端口设置为8090 。
- 调用create_proxy 从 Server 创建代理对象并将“trustAllServers”参数设置为true 的方法。
- 使用下面代码中讨论的executable_path和chrome-options启动chrome webdriver 。
- 现在,使用带有网站域的代理对象创建一个新的 HAR 文件。
- 使用driver.get()发送 GET 请求并等待几秒钟以正确加载它。
句法:
driver.get(url)
- 通过使用json.dumps()将其转换为 JSON字符串,将来自代理对象的网络流量的 HAR 文件写入 HAR 文件。
例子:
蟒蛇3
# Import the required modules
from selenium import webdriver
from browsermobproxy import Server
import time
import json
# Main Function
if __name__ == "__main__":
# Enter the path of bin folder by
# extracting browsermob-proxy-2.1.4-bin
path_to_browsermobproxy = "C:\\browsermob-proxy-2.1.4\\bin\\"
# Start the server with the path and port 8090
server = Server(path_to_browsermobproxy
+ "browsermob-proxy", options={'port': 8090})
server.start()
# Create the proxy with following parameter as true
proxy = server.create_proxy(params={"trustAllServers": "true"})
# Create the webdriver object and pass the arguments
options = webdriver.ChromeOptions()
# Chrome will start in Headless mode
options.add_argument('headless')
# Ignores any certificate errors if there is any
options.add_argument("--ignore-certificate-errors")
# Setting up Proxy for chrome
options.add_argument("--proxy-server={0}".format(proxy.proxy))
# Startup the chrome webdriver with executable path and
# the chrome options as parameters.
driver = webdriver.Chrome(executable_path="C:/chromedriver.exe",
chrome_options=options)
# Create a new HAR file of the following domain
# using the proxy.
proxy.new_har("geeksforgeeks.org/")
# Send a request to the website and let it load
driver.get("https://www.geeksforgeeks.org/")
# Sleeps for 10 seconds
time.sleep(10)
# Write it to a HAR file.
with open("network_log1.har", "w", encoding="utf-8") as f:
f.write(json.dumps(proxy.har))
print("Quitting Selenium WebDriver")
driver.quit()
# Read HAR File and parse it using JSON
# to find the urls containing images.
har_file_path = "network_log1.har"
with open(har_file_path, "r", encoding="utf-8") as f:
logs = json.loads(f.read())
# Store the network logs from 'entries' key and
# iterate them
network_logs = logs['log']['entries']
for log in network_logs:
# Except block will be accessed if any of the
# following keys are missing
try:
# URL is present inside the following keys
url = log['request']['url']
# Checks if the extension is .png or .jpg
if url[len(url)-4:] == '.png' or url[len(url)-4:] == '.jpg':
print(url, end="\n\n")
except Exception as e:
# print(e)
pass
输出:
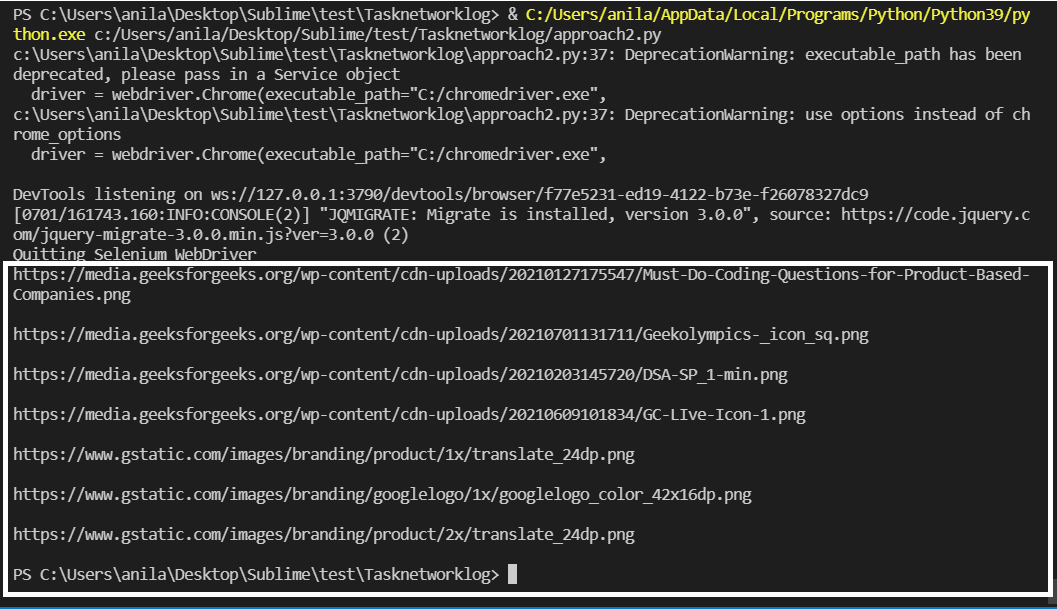
图像 URL 在上面突出显示。
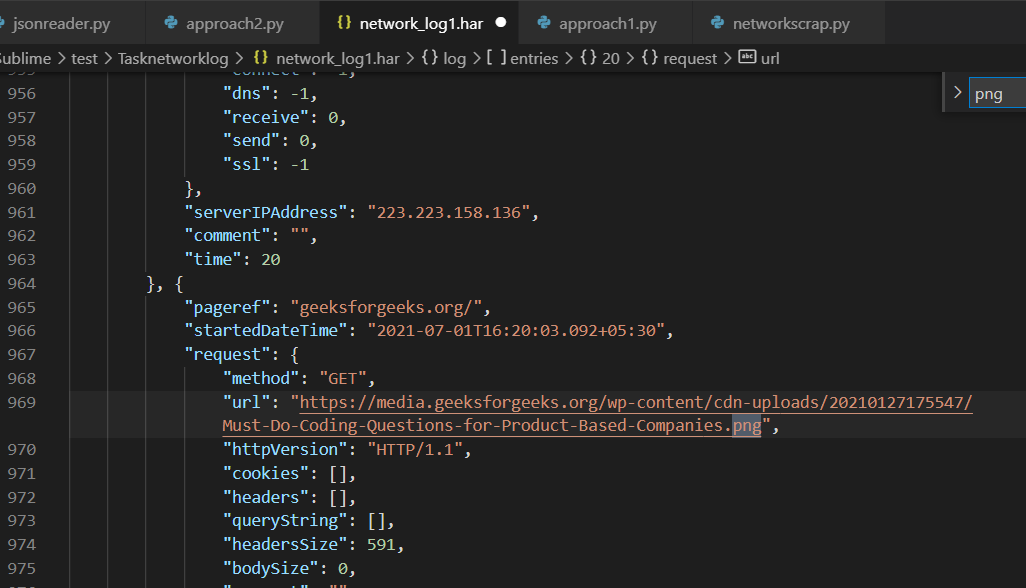
network_log1.har 包含图像 URL