强化学习中的 Epsilon-Greedy 算法
在强化学习中,代理或决策者学习做什么——如何将情况映射到行动——以最大化数字奖励信号。代理没有被明确告知要采取哪些行动,而是必须通过反复试验发现哪个行动产生最大的回报。
多臂强盗问题
多臂老虎机问题用于强化学习,以形式化不确定性下的决策概念。在多臂老虎机问题中,代理(学习者)在k个不同的动作之间进行选择,并根据所选择的动作获得奖励。
多臂老虎机也用于描述强化学习中的基本概念,例如奖励、时间步长和价值。
对于代理选择一个动作,我们假设每个动作都有单独的奖励分配,并且至少有一个动作可以产生最大的数值奖励。因此,每个动作对应的奖励的概率分布是不同的,并且对于代理(决策者)是未知的。因此,代理的目标是确定在给定的一组试验之后选择哪个动作以获得最大奖励。
行动价值和行动价值估计
为了让代理决定哪个动作产生最大奖励,我们必须定义采取每个动作的价值。我们使用概率的概念使用动作值函数来定义这些值。
选择一个动作的价值被定义为从一组所有可能的动作中采取该动作时收到的预期奖励。由于代理不知道选择动作的价值,因此我们使用“样本平均”方法来估计采取行动的价值。

探索与剥削
探索允许智能体改进其对每个动作的当前知识,有望带来长期利益。提高估计动作值的准确性,使代理能够在未来做出更明智的决策。
另一方面, Exploitation通过利用代理当前的动作价值估计来选择贪婪的动作以获得最大的回报。但是由于对行动价值估计的贪婪,实际上可能无法获得最大的回报并导致次优行为。
当代理进行探索时,它会获得更准确的动作值估计。而当它利用时,它可能会得到更多的回报。但是,它不能同时选择两者,这也称为探索-利用困境。
Epsilon-贪心动作选择
Epsilon-Greedy 是一种通过随机选择探索和利用来平衡探索和利用的简单方法。
epsilon-greedy,其中 epsilon 是指选择探索的概率,大多数时间利用探索的机会很小。


代码:Epsilon-Greedy 的Python代码
# Import required libraries
import numpy as np
import matplotlib.pyplot as plt
# Define Action class
class Actions:
def __init__(self, m):
self.m = m
self.mean = 0
self.N = 0
# Choose a random action
def choose(self):
return np.random.randn() + self.m
# Update the action-value estimate
def update(self, x):
self.N += 1
self.mean = (1 - 1.0 / self.N)*self.mean + 1.0 / self.N * x
def run_experiment(m1, m2, m3, eps, N):
actions = [Actions(m1), Actions(m2), Actions(m3)]
data = np.empty(N)
for i in range(N):
# epsilon greedy
p = np.random.random()
if p < eps:
j = np.random.choice(3)
else:
j = np.argmax([a.mean for a in actions])
x = actions[j].choose()
actions[j].update(x)
# for the plot
data[i] = x
cumulative_average = np.cumsum(data) / (np.arange(N) + 1)
# plot moving average ctr
plt.plot(cumulative_average)
plt.plot(np.ones(N)*m1)
plt.plot(np.ones(N)*m2)
plt.plot(np.ones(N)*m3)
plt.xscale('log')
plt.show()
for a in actions:
print(a.mean)
return cumulative_average
if __name__ == '__main__':
c_1 = run_experiment(1.0, 2.0, 3.0, 0.1, 100000)
c_05 = run_experiment(1.0, 2.0, 3.0, 0.05, 100000)
c_01 = run_experiment(1.0, 2.0, 3.0, 0.01, 100000)
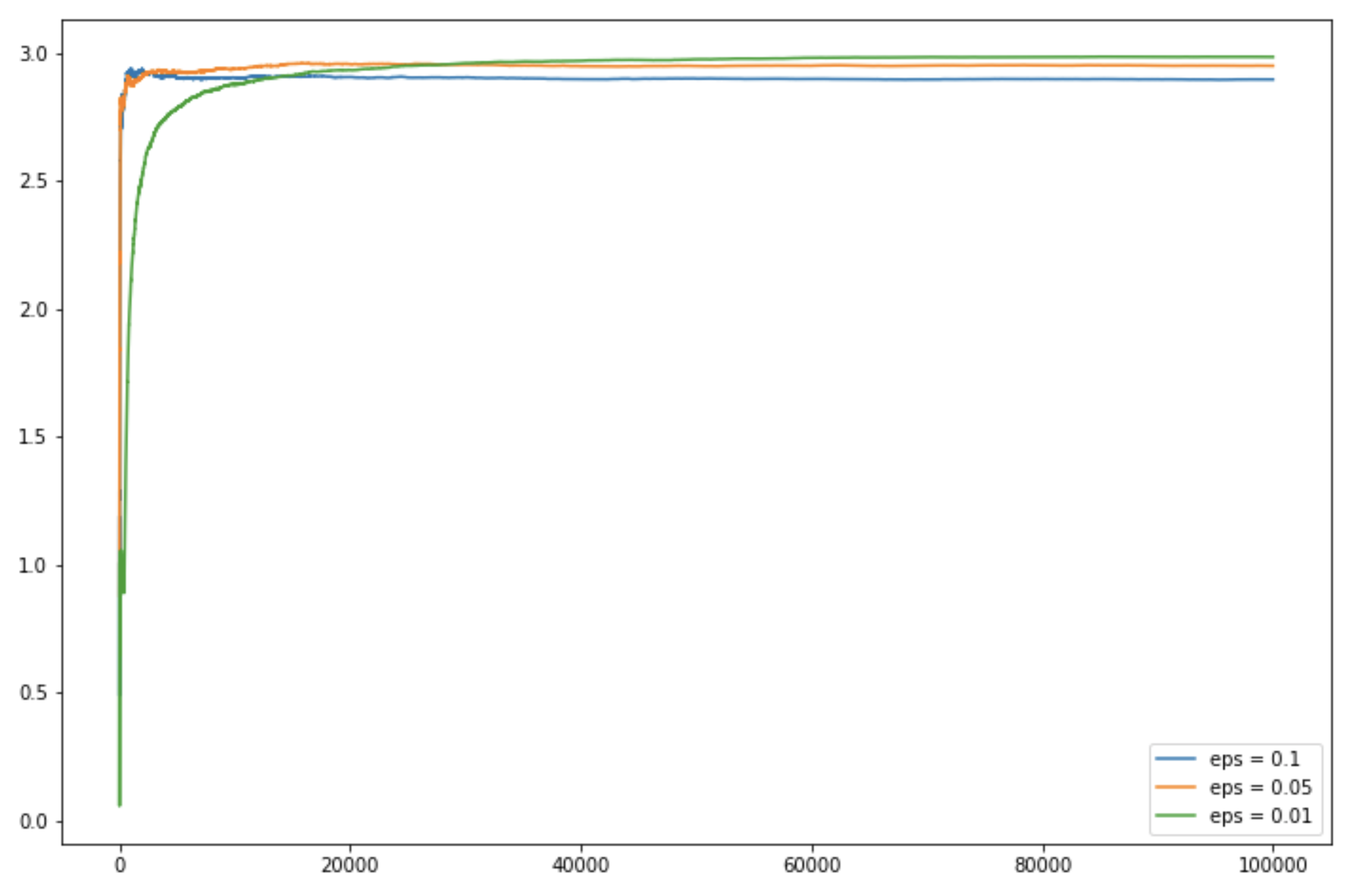
输出:

代码:用于获取日志输出图的Python代码
# log scale plot
plt.plot(c_1, label ='eps = 0.1')
plt.plot(c_05, label ='eps = 0.05')
plt.plot(c_01, label ='eps = 0.01')
plt.legend()
plt.xscale('log')
plt.show()
输出:
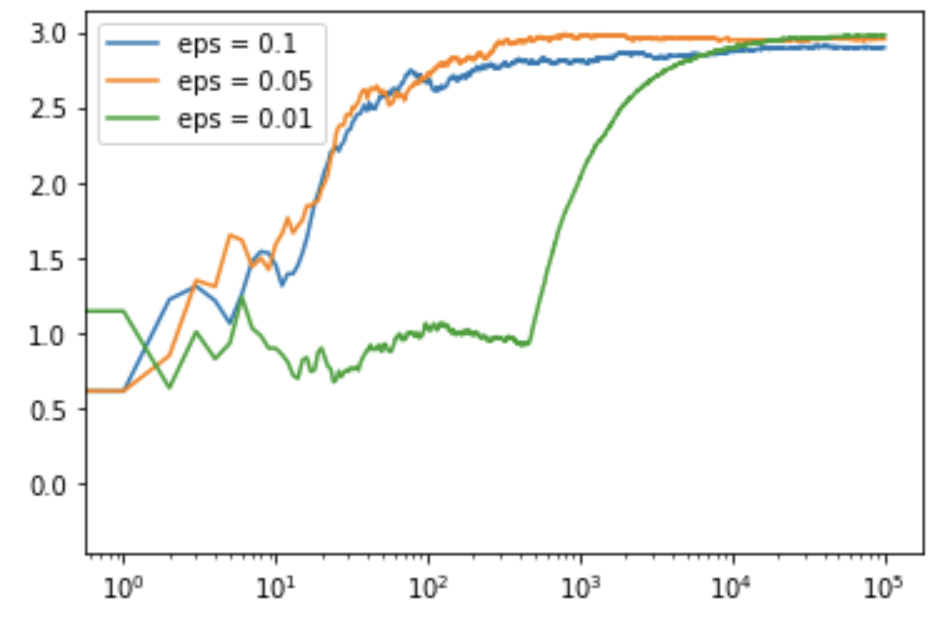
代码:用于获取线性输出图的Python代码
# linear plot
plt.figure(figsize = (12, 8))
plt.plot(c_1, label ='eps = 0.1')
plt.plot(c_05, label ='eps = 0.05')
plt.plot(c_01, label ='eps = 0.01')
plt.legend()
plt.show()
输出: