PointNet——深度学习
PointNet 是斯坦福大学的一名研究人员于 2016 年提出的。 本文背后的动机是对图像的 3D 表示进行分类和分割。他们使用一种称为点云的数据结构,它是一组表示 3D 形状或对象的点。由于其不规则性,它仅适用于特定用例。
许多作者将点云转换为其他一些称为体素(体积像素)的表示,然后再将其输入深度神经网络。然而,这种转换导致数据量太大,并且将量化引入 3D 结构也会导致与自然伪影的差异。
在本文中,作者提出了一种直接消费点云并输出图像的相关分类或分割的新方法。
建筑学
作者提出了一种以点云中的点集作为输入的架构。点云由一组 3D 点 P i表示,其中每个点表示为 (x i , y i , z i )。
对于物体分类任务,输入点云直接从形状中采样或从场景点云中预先分割。对于语义分割,输入可以是来自局部区域分割的单个对象或来自对象区域分割的一小部分 3D 场景。
点集的一些属性是:
- Permutation Invariance :由于点云中的点是非结构化的,扫描N个点有N个! d 不同的排列。数据处理必须对点云的不同排列表示保持不变。
- 变换不变性:分类和分割输出不受旋转和平移等不同变换的影响。
- 不同点之间的交互黑白:相邻点之间的连接通常带有有用的信息。因此,不应孤立地对待每一点。这些相互作用在分割中比分类更有用。
点网架构
PointNet 架构非常直观。分类网络使用共享的多层感知器将 n 个点中的每一个从 3 维映射到 64 维。重要的是,n 个点中的每一个都共享一个多层感知器。同样,在下一层,每个n点从64维映射到1024维。现在,我们应用最大池化在 ℝ¹⁰²⁴ 中创建全局特征向量。最后,使用三层全连接网络 (FCN) 将全局特征向量映射到k 个输出分类分数。
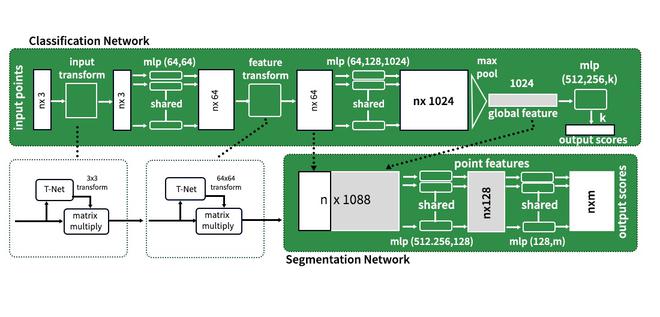
点网架构
对于分割网络,n个输入中的每一个都需要分配m个分割类之一,因为分割依赖于局部和全局特征,将64维空间中的点与全局特征空间连接起来,得到可能的特征n * ℝ¹⁰ 88 的空间。
PointNet 架构具有以下关键模块:最大池化层、局部和全局组合结构,以及两个同时对齐局部和全局网络的联合对齐网络。类似于每点
对称函数
为了使模型从排列中保持不变,存在三种策略:
- 将输入排序为规范顺序。
- 将输入视为训练 RNN 的序列
- 使用简单的对称函数聚合来自每个点的信息。
下面是一个对称函数的例子
在哪里
h 可以是多层感知器,g 是单变量函数和最大池化函数,f 可以是输出层。
本地和全球信息聚合
上述部分的输出形成一个向量 [f 1 , f 2 , ....f n ],即输入集的全局签名。现在,这将正常工作,因为我们可以轻松训练 SVM 以生成分类器输出。但是,对于点分割,我们需要结合局部和全局特征。
为了获得所需的结果,在计算全局特征向量后,作者通过将全局特征与每点特征连接起来将其反馈给点特征(参见上图中的架构)。该方法能够预测依赖于全局语义和局部特征的每点数量
联合对齐网络
点云的语义标记必须是几何变换不变的(即任何旋转、平移等不变)。作者使用迷你网络来预测仿射变换矩阵,并将此变换应用于输入点的坐标。
在 T-net 的最后一步中,T-net 最终全连接层的输入相关特征与全局可训练的权重和偏差相结合,产生一个 3×3 的变换矩阵。
姿势归一化的概念扩展到 64 维嵌入空间。 T-net 与上图类似,除了几乎之外,除了增加了可训练权重和偏差的维数,分别变为 256*4096*4096 返回到 64*64 的变换矩阵中。可训练数量的增加导致过度拟合,这就是作者引入正则化项以鼓励产生的 64*64 转换的原因。

执行
Python3
# code
import os
import datetime
import glob
import trimesh
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
tf.random.set_seed(1)
# Load model
DATA_DIR = tf.keras.utils.get_file(
"modelnet.zip",
"http://3dvision.princeton.edu/projects/2014/3DShapeNets/ModelNet10.zip",
extract=True,
)
DATA_DIR = os.path.join(os.path.dirname(DATA_DIR), "ModelNet10")
mesh = trimesh.load(os.path.join(DATA_DIR, "chair/train/chair_0001.off"))
# sample point from
points = mesh.sample(2048)
fig = plt.figure(figsize=(5, 5))
ax = fig.add_subplot(111, projection="3d")
ax.scatter(points[:, 0], points[:, 1], points[:, 2],color = 'red')
ax.set_axis_off()
plt.show()
# function to parse dataset
def parse_dataset(num_points=2048):
train_points = []
train_labels = []
test_points = []
test_labels = []
class_map = {}
folders = glob.glob(os.path.join(DATA_DIR, "[!README]*"))
for i, folder in enumerate(folders):
print("processing class: {}".format(os.path.basename(folder)))
# store folder name with ID so we can retrieve later
class_map[i] = folder.split("/")[-1]
# gather all files
train_files = glob.glob(os.path.join(folder, "train/*"))
test_files = glob.glob(os.path.join(folder, "test/*"))
for f in train_files:
train_points.append(trimesh.load(f).sample(num_points))
train_labels.append(i)
for f in test_files:
test_points.append(trimesh.load(f).sample(num_points))
test_labels.append(i)
return (
np.array(train_points),
np.array(test_points),
np.array(train_labels),
np.array(test_labels),
class_map,
)
class OrthogonalRegularizer(keras.regularizers.Regularizer):
def __init__(self, num_features, l2reg=0.001):
self.num_features = num_features
self.l2reg = l2reg
self.eye = tf.eye(num_features)
def __call__(self, x):
x = tf.reshape(x, (-1, self.num_features, self.num_features))
xxt = tf.tensordot(x, x, axes=(2, 2))
xxt = tf.reshape(xxt, (-1, self.num_features, self.num_features))
return tf.reduce_sum(self.l2reg * tf.square(xxt - self.eye))
# Create the T-net model
def t_net(inputs, num_features):
# Initialise bias as the indentity matrix
bias = keras.initializers.Constant(np.eye(num_features).flatten())
reg = OrthogonalRegularizer(num_features)
x = conv_bn(inputs, 32)
x = conv_bn(x, 64)
x = conv_bn(x, 512)
x = layers.GlobalMaxPooling1D()(x)
x = dense_bn(x, 256)
x = dense_bn(x, 128)
x = layers.Dense(
num_features * num_features,
kernel_initializer="zeros",
bias_initializer=bias,
activity_regularizer=reg,
)(x)
feat_T = layers.Reshape((num_features, num_features))(x)
# Apply affine transformation to input features
return layers.Dot(axes=(2, 1))([inputs, feat_T])
# the main model
inputs = keras.Input(shape=(NUM_POINTS, 3))
x = t_net(inputs, 3)
x = conv_bn(x, 32)
x = conv_bn(x, 32)
x = t_net(x, 32)
x = conv_bn(x, 32)
x = conv_bn(x, 64)
x = conv_bn(x, 512)
x =layers.GlobalMaxPooling1D()(x)
x = dense_bn(x, 256)
x = layers.Dropout(0.3)(x)
x = dense_bn(x, 128)
x = layers.Dropout(0.3)(x)
outputs = layers.Dense(NUM_CLASSES, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs, name="pointnet")
model.summary()
%load_ext tensorboard
# compile and train the model
model.compile(
loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.Adam(learning_rate=0.001),
metrics=["sparse_categorical_accuracy"],
)
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
print(log_dir)
model.fit(train_dataset, epochs=30, validation_data=test_dataset,
callbacks=[tensorboard_callback])logs/fit/20210309-060624
WARNING:tensorflow:Model failed to serialize as JSON. Ignoring... <__main__.OrthogonalRegularizer object at 0x7fc3ecd25790> does not implement get_config()
Epoch 1/30
125/125 [==============================] - 36s 251ms/step - loss: 3.9923 - sparse_categorical_accuracy: 0.2046 - val_loss: 43220470648012800.0000 - val_sparse_categorical_accuracy: 0.2687
Epoch 2/30
125/125 [==============================] - 30s 239ms/step - loss: 3.1246 - sparse_categorical_accuracy: 0.3611 - val_loss: 12.8184 - val_sparse_categorical_accuracy: 0.2137
Epoch 3/30
125/125 [==============================] - 30s 239ms/step - loss: 2.8952 - sparse_categorical_accuracy: 0.4318 - val_loss: 3.3341 - val_sparse_categorical_accuracy: 0.1707
Epoch 4/30
125/125 [==============================] - 30s 239ms/step - loss: 2.6418 - sparse_categorical_accuracy: 0.4795 - val_loss: 268835504128.0000 - val_sparse_categorical_accuracy: 0.4747
Epoch 5/30
125/125 [==============================] - 30s 239ms/step - loss: 2.5744 - sparse_categorical_accuracy: 0.5262 - val_loss: 1399391744.0000 - val_sparse_categorical_accuracy: 0.5165
Epoch 6/30
125/125 [==============================] - 30s 239ms/step - loss: 2.3542 - sparse_categorical_accuracy: 0.6136 - val_loss: 911933.9375 - val_sparse_categorical_accuracy: 0.5936
Epoch 7/30
125/125 [==============================] - 30s 239ms/step - loss: 2.2442 - sparse_categorical_accuracy: 0.6602 - val_loss: 257217894776045568.0000 - val_sparse_categorical_accuracy: 0.6410
Epoch 8/30
125/125 [==============================] - 30s 238ms/step - loss: 2.1114 - sparse_categorical_accuracy: 0.6685 - val_loss: 50140152856576.0000 - val_sparse_categorical_accuracy: 0.6960
Epoch 9/30
125/125 [==============================] - 30s 239ms/step - loss: 2.0264 - sparse_categorical_accuracy: 0.6971 - val_loss: 117848482353512448.0000 - val_sparse_categorical_accuracy: 0.7159
Epoch 10/30
125/125 [==============================] - 30s 239ms/step - loss: 2.0393 - sparse_categorical_accuracy: 0.6928 - val_loss: 2660748754944.0000 - val_sparse_categorical_accuracy: 0.6322
Epoch 11/30
125/125 [==============================] - 30s 239ms/step - loss: 1.9129 - sparse_categorical_accuracy: 0.7376 - val_loss: 20.5381 - val_sparse_categorical_accuracy: 0.7048
Epoch 12/30
125/125 [==============================] - 30s 238ms/step - loss: 1.8221 - sparse_categorical_accuracy: 0.7659 - val_loss: 534893165459537920.0000 - val_sparse_categorical_accuracy: 0.7148
Epoch 13/30
125/125 [==============================] - 30s 239ms/step - loss: 1.7931 - sparse_categorical_accuracy: 0.7741 - val_loss: 14077352313094144.0000 - val_sparse_categorical_accuracy: 0.7192
Epoch 14/30
125/125 [==============================] - 30s 239ms/step - loss: 1.7970 - sparse_categorical_accuracy: 0.7683 - val_loss: 9279.2363 - val_sparse_categorical_accuracy: 0.7808
Epoch 15/30
125/125 [==============================] - 30s 239ms/step - loss: 1.7285 - sparse_categorical_accuracy: 0.7924 - val_loss: 8201817088.0000 - val_sparse_categorical_accuracy: 0.8304
Epoch 16/30
125/125 [==============================] - 30s 238ms/step - loss: 1.7426 - sparse_categorical_accuracy: 0.7912 - val_loss: 1834421736964096.0000 - val_sparse_categorical_accuracy: 0.7555
Epoch 17/30
125/125 [==============================] - 30s 238ms/step - loss: 1.6427 - sparse_categorical_accuracy: 0.8237 - val_loss: 309827239936.0000 - val_sparse_categorical_accuracy: 0.7610
Epoch 18/30
125/125 [==============================] - 30s 238ms/step - loss: 1.6883 - sparse_categorical_accuracy: 0.8182 - val_loss: 12362231232444401451008.0000 - val_sparse_categorical_accuracy: 0.6740
Epoch 19/30
125/125 [==============================] - 30s 238ms/step - loss: 1.6198 - sparse_categorical_accuracy: 0.8378 - val_loss: 168301294885625921536.0000 - val_sparse_categorical_accuracy: 0.7048
Epoch 20/30
125/125 [==============================] - 30s 238ms/step - loss: 1.6321 - sparse_categorical_accuracy: 0.8265 - val_loss: 34155740306341888.0000 - val_sparse_categorical_accuracy: 0.7963
Epoch 21/30
125/125 [==============================] - 30s 238ms/step - loss: 1.6206 - sparse_categorical_accuracy: 0.8237 - val_loss: 73268587348667400192.0000 - val_sparse_categorical_accuracy: 0.7874
Epoch 22/30
125/125 [==============================] - 30s 238ms/step - loss: 1.5612 - sparse_categorical_accuracy: 0.8497 - val_loss: 1441606803694551040.0000 - val_sparse_categorical_accuracy: 0.8007
Epoch 23/30
125/125 [==============================] - 30s 238ms/step - loss: 1.6024 - sparse_categorical_accuracy: 0.8288 - val_loss: 672064995328.0000 - val_sparse_categorical_accuracy: 0.8249
Epoch 24/30
125/125 [==============================] - 30s 238ms/step - loss: 1.5145 - sparse_categorical_accuracy: 0.8572 - val_loss: 416892130609315446784.0000 - val_sparse_categorical_accuracy: 0.8040
Epoch 25/30
125/125 [==============================] - 30s 239ms/step - loss: 1.5235 - sparse_categorical_accuracy: 0.8531 - val_loss: 13480175.0000 - val_sparse_categorical_accuracy: 0.8403
Epoch 26/30
125/125 [==============================] - 30s 238ms/step - loss: 1.5077 - sparse_categorical_accuracy: 0.8588 - val_loss: 8007.9917 - val_sparse_categorical_accuracy: 0.6123
Epoch 27/30
125/125 [==============================] - 30s 239ms/step - loss: 1.5592 - sparse_categorical_accuracy: 0.8402 - val_loss: 2.1578 - val_sparse_categorical_accuracy: 0.6564
Epoch 28/30
125/125 [==============================] - 30s 238ms/step - loss: 1.5293 - sparse_categorical_accuracy: 0.8555 - val_loss: 12311261760978944.0000 - val_sparse_categorical_accuracy: 0.8337
Epoch 29/30
125/125 [==============================] - 30s 238ms/step - loss: 1.5008 - sparse_categorical_accuracy: 0.8716 - val_loss: 302755749388353536.0000 - val_sparse_categorical_accuracy: 0.7907
Epoch 30/30
125/125 [==============================] - 30s 238ms/step - loss: 1.4952 - sparse_categorical_accuracy: 0.8661 - val_loss: 10193839104.0000 - val_sparse_categorical_accuracy: 0.8767
3D-Mesh(由于尺寸限制,此处无法可视化)

点云

TensorFlow 图

分类结果
参考:
- 点网