本文是以下三篇文章的续篇:
Ukkonen的后缀树构造–第1部分
Ukkonen的后缀树构造–第2部分
Ukkonen的后缀树构造–第3部分
在阅读当前文章之前,请先阅读第1部分,第2部分和第3部分,在该文章中,我们几乎看不到后缀树的基础知识,高级ukkonen的算法,后缀链接和三个实现技巧,以及activePoint上的一些细节以及示例字符串“ abcabxabcd”,我们经历了构建后缀树的四个阶段。
让我们回顾技巧3,技巧3和activePoint中在第3部分中已经看到的四个阶段。
- activePoint初始化为(root,NULL,0),即activeNode为root,activeEdge为NULL(为便于理解,我们将字符值赋予activeEdge,但在代码实现中,它将为字符的索引),而activeLength为零。
- 全局变量END和剩余的SuffixCount初始化为ZERO
*********************阶段1*************************** ******
在阶段1中,我们从字符串S中读取第一个字符(a)
- 将END设置为1
- 将remainingSuffixCount增加1(此处remainingSuffixCount将为1,即还有1个扩展要执行)
- 如下运行循环剩下的SuffixCount次(即一次):
- 如果activeLength为零,则将activeEdge设置为当前字符(此处activeEdge将为’a’)。这是APCFALZ 。
- 检查activeEdge是否有一条从activeNode(在此阶段1中为根)伸出的边缘。如果没有,请创建叶子边缘。如果有的话,走下去。在我们的示例中,创建了叶边缘(规则2)。
- 执行扩展后,将剩余的SuffixCount减1
- 此时,activePoint为(root,a,0)
在阶段1结束时,剩余的SuffixCount为零(所有后缀都显式添加)。
第3部分中的图20是阶段1之后的结果树。
*********************阶段2*************************** ******
在阶段2中,我们从字符串S读取第二个字符(b)
- 将END设置为2(这将执行扩展1)
- 将remainingSuffixCount增加1(此处remainingSuffixCount将为1,即还有1个扩展要执行)
- 如下运行循环剩下的SuffixCount次(即一次):
- 如果activeLength为零,则将activeEdge设置为当前字符(此处activeEdge将为“ b”)。这是APCFALZ 。
- 检查activeEdge是否有一条从activeNode(在此阶段2中为根)伸出的边缘。如果没有,请创建叶子边缘。如果有的话,走下去。在我们的示例中,创建了叶边缘。
- 执行扩展后,将剩余的SuffixCount减1
- 此时,activePoint为(root,b,0)
在阶段2结束时,剩余的SuffixCount为零(所有后缀都明确添加)。
第3部分中的图22是阶段2之后的结果树。
*********************第3阶段******************************* ******
在阶段3中,我们从字符串S中读取第三个字符(c)
- 将END设置为3(这将执行扩展1和2)
- 将remainingSuffixCount增加1(此处remainingSuffixCount将为1,即还有1个扩展要执行)
- 如下运行循环剩下的SuffixCount次(即一次):
- 如果activeLength为零,则将activeEdge设置为当前字符(此处activeEdge将为’c’)。这是APCFALZ 。
- 检查是否有来自activeNode的边缘(在此阶段3中是根节点)连接到activeEdge。如果没有,请创建叶子边缘。如果有的话,走下去。在我们的示例中,创建了叶边缘。
- 执行扩展后,将剩余的SuffixCount减1
- 此时,activePoint为(root,c,0)
在第3阶段结束时,剩余的SuffixCount为零(所有后缀都明确添加)。
第3部分中的图25是阶段3之后的结果树。
*********************第四阶段******************************* ******
在阶段4中,我们从字符串S读取第4个字符(a)
- 将END设置为4(这将执行扩展1、2和3)
- 将remainingSuffixCount增加1(此处remainingSuffixCount将为1,即还有1个扩展要执行)
- 如下运行循环剩下的SuffixCount次(即一次):
- 如果activeLength为零,则将activeEdge设置为当前字符(此处activeEdge将为’a’)。这是APCFALZ 。
- 检查是否有来自activeNode的边缘(在此阶段3中是根节点)连接到activeEdge。如果没有,请创建叶子边缘。如果有的话,走下去(技巧1 –跳过/计数)。在我们的示例中,边缘“ a”存在于activeNode(即根)之外。由于activeLength
- 此时,activePoint为(根,a,1),而remainingSuffixCount仍设置为1(此处无变化)
在阶段4结束时,remainingSuffixCount为1(一个后缀’a’,最后一个,未在树中显式添加,但在树中隐式存在)。
第3部分中的图28是阶段4之后的结果树。重温完成了1个四个阶段,我们将继续构建树,看看怎么回事。
*********************第5阶段******************************* ******
在阶段5中,我们从字符串S读取了第5个字符(b)
- 将END设置为5(这将执行扩展1、2和3)。请参见下面的图29。
- 将剩余的SuffixCount增加1(这里的remainingSuffixCount将为2,即还有2个扩展要执行,分别是扩展4和5。扩展4应该添加后缀“ ab”,扩展5应该添加后缀“ b”)。树)
- 如下运行循环剩下的SuffixCount次(即两次):
- 检查是否有来自activeNode的边缘(在此阶段3中是根节点)连接到activeEdge。如果没有,请创建叶子边缘。如果有的话,走下去。在我们的示例中,边缘“ a”存在于activeNode(即根)之外。
- 如有必要,请步行(技巧1 –跳过/计数)。在当前阶段5中,由于activeLength
- 检查activePoint之后是否已经存在字符串S的当前字符(即“ b”)。如果是,则不再进行处理(规则3)。在我们的示例中也是如此,因此我们将activeLength从1增加到2( APCFER3 ),然后在此处停止(规则3)。
- 此时,activePoint为(根,a,2),而remainingSuffixCount仍设置为2(remainingSuffixCount不变)
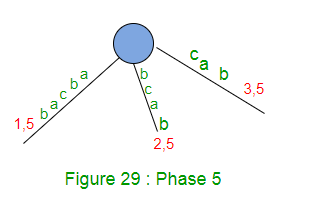
在阶段5结束时,剩余的SuffixCount为2(两个后缀’ab’和’b’,后两个未在树中显式添加,但在树中隐式添加)。
*********************第六阶段******************************* ******
在阶段6中,我们从字符串S读取第6个字符(x)
- 将END设置为6(这将执行扩展1、2和3)
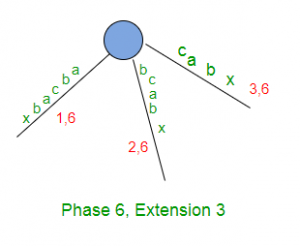
- 将剩余的SuffixCount增加1(此处remainingSuffixCount将为3,即还有3个扩展要执行,分别是后缀“ abx”,“ bx”和“ x”的扩展4、5和6)
- 如下运行循环剩下的SuffixCount次(即3次):
- 在扩展名4中,activePoint是(root,a,2),它在以’a’开头的边上指向’b’。
- 在扩展名4中,字符串S中的当前字符’x’与activePoint之后的边缘上的下一个字符不匹配,因此是扩展规则2的情况。因此,此处使用边缘标签x创建了叶边缘。同样,这里的遍历在边的中间结束,因此在activePoint的末尾也会创建一个新的内部节点。
- 在树中添加后缀“ abx”时,将剩余的SuffixCount减1(从3到2)。
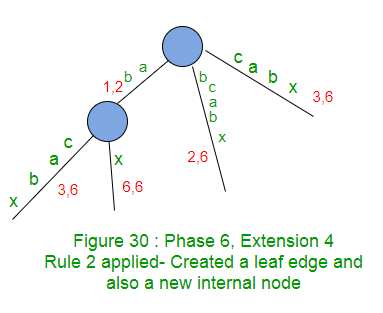 现在,activePoint将在应用规则2后发生更改。在第3部分中已经讨论了其他三种情况( APCFER3 , APCFWD和APCFALZ ),其中activePoint发生了更改。
现在,activePoint将在应用规则2后发生更改。在第3部分中已经讨论了其他三种情况( APCFER3 , APCFWD和APCFALZ ),其中activePoint发生了更改。
扩展规则2(APCFER2)的activePoint更改:
情况1(APCFER2C1):如果activeNode为root且activeLength大于ZERO ,则将activeLength减1,activeEdge将设置为“ S [i –剩下的后缀计数+ 1]”,其中i为当前相数。您能看到为什么ActivePoint发生这种变化吗?再看一下我们刚才在阶段6(i = 6)中讨论的当前扩展,在其中我们添加了后缀“ abx”。其中activeLength为2,activeEdge为’a’。现在在下一个扩展中,我们需要在树中添加后缀“ bx”,即下一个扩展中的路径标签应以“ b”开头。因此,“ b”(字符串S中的第5个字符)应为下一个扩展的有效边,并且b的索引将为“ i –剩下的后缀计数+ 1”(6 – 2 + 1 = 5)。 activeLength递减1,因为每次扩展后activePoint都以长度1接近根。
如果activeNode为root且activeLength为0,将会发生什么? APCFALZ已经处理了这种情况。
情况2(APCFER2C2):如果activeNode不是root ,则按照当前activeNode的后缀链接进行操作。后缀链接所指向的新节点(可以是根节点或另一个内部节点)将是下一个扩展的activeNode。 activeLength和activeEdge保持不变。您能看到为什么ActivePoint发生这种变化吗?这是因为:如果两个节点通过后缀链接连接,则从这两个节点向下的所有路径上以相同字符开始的标签将完全相同,因此对于这些路径上两个对应的类似点,activeEdge和activeLength将相同,两个节点将是activeNode。看一下第2部分中的图18。假设在阶段i和扩展名j中,在树中添加了后缀’xAabcdedg’。在这一点上,假设activePoint为(Node-V,a,7),即点“ g”。因此,对于下一个扩展名j + 1,我们将添加后缀’Aabcdefg’,为此我们需要遍历图18中所示的第二条路径。这可以通过遵循当前activeNode v的后缀链接来完成。后缀链接将我们带到该路径遍历[Node s(v)]之间的某个位置,在该位置下方的路径与先前的activeNode v下方的路径完全相同。如前所述,“每次扩展后,activePoint都以长度1靠近根”长度将在节点s(v)之上但在s(v)之下,完全没有变化。因此,当activeNode不是当前扩展的根节点时,则对于下一个扩展,仅activeNode会更改(activeEdge和activeLength中没有更改)。
- 在扩展4的这一点上,当前activePoint是(root,a,2),基于APCFER2C1 ,下一个扩展5的新activePoint将是(root,b,1)。
- 下一个要添加的后缀是“ bx”(剩余的后缀计数为2)。
- 字符串S中的当前字符’x’与activePoint之后的边缘上的下一个字符不匹配,因此是扩展规则2的情况。因此,此处使用边缘标签x创建了叶边缘。同样,这里的遍历在边的中间结束,因此在activePoint的末尾也会创建一个新的内部节点。
后缀链接也从先前的内部节点(扩展4的内部节点)创建到在当前扩展5中创建的新的内部节点。 - 在树中添加后缀“ bx”时,将剩余的SuffixCount减1(从2到1)。
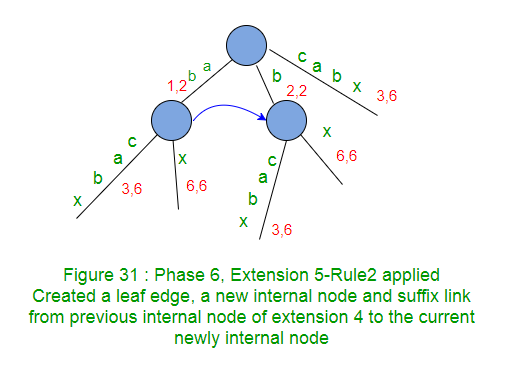
- 在延伸部5这一点上,电流activePoint是(根,B,1),以及基于新APCFER2C1为activePoint下延6将(根中,x,0)
- 下一个要添加的后缀是“ x”(剩余的后缀计数为1)。
- 在下一个扩展6中,字符x不会与根上的任何现有边匹配,因此将从根节点创建带有标签x的新边。来自先前扩展的内部节点的后缀链接也将转到根(因为当前扩展6中未创建新的内部节点)。
- 在树中添加后缀“ x”时,将剩余的SuffixCount减1(从1到0)

这样就完成了阶段6。
请注意,阶段6已完成其所有6个扩展(为什么?因为到目前为止,当前字符c尚未在字符串看到,所以规则3停止了进一步的扩展,因此从未有机会在阶段6中得到应用),因此在阶段6是到目前为止已读取的字符’abcabx’的真实后缀树(即不是隐式树),并且在树中显式包含所有后缀。
在上面构建树时,注意到以下事实:
- 在扩展名i中新创建的内部节点通过后缀链接在扩展名i + 1的末尾指向另一个内部节点或根(如果activeNode在扩展名i + 1中是根)(每个内部节点必须有一个指向另一个的后缀链接)内部节点或根)
- 后缀链接在搜索下一个后缀的路径标签结尾时提供捷径
- 通过正确跟踪扩展/阶段之间的activePoint,可以避免从根目录不必要的中断。
我们将在第5部分中的其余阶段(7到11)中完成整个树的构建,然后,在第6部分中将看到该算法的代码。
参考文献:
http://web.stanford.edu/~mjkay/gusfield.pdf
普通英语的Ukkonen后缀树算法