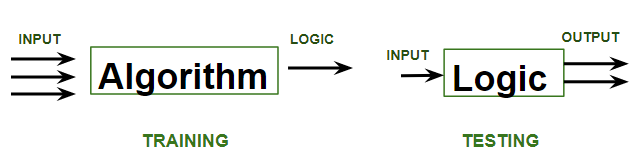
什么是机器学习?
如果某台机器正在通过某类任务从过去的经验(数据输入)中学习,则该机器在给定任务中的性能会随该经验而提高,例如,假设一台机器必须预测客户是否会购买某个产品是否可以在今年说出“防病毒”。机器将通过查看以前的知识/过去的经验来完成此操作,即客户每年购买的产品数据,如果他每年购买防病毒软件,则客户很有可能会购买此产品的防病毒软件。一年也是如此。这就是机器学习在基本概念级别上的工作方式。
监督学习:
监督学习是指对模型进行标记的数据集训练。标记数据集是同时具有输入和输出参数的数据集。在这种类型的学习中,训练和验证数据集均被标记,如下图所示。 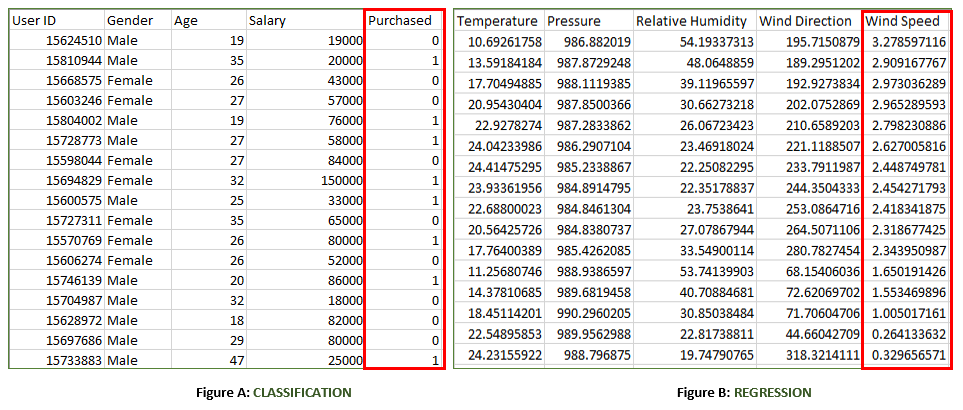
以上两个图均标有数据集–
- 图A:这是购物商店的数据集,可用于根据客户的性别,年龄和薪水来预测客户是否购买考虑中的特定产品。
输入:性别,年龄,工资
输出:已购买,即0或1; 1表示是,客户将购买,0表示客户将不购买。 - 图B:这是一个气象数据集,用于基于不同参数预测风速。
输入:露点,温度,压力,相对湿度,风向
输出:风速
对系统进行雨淋:
在训练模型时,数据通常以80:20的比例分割,即80%作为训练数据,其余作为测试数据。在训练数据中,我们输入和输出80%的数据。该模型仅从训练数据中学习。我们使用不同的机器学习算法(我们将在下一篇文章中详细讨论)来构建模型。通过学习,这意味着模型将建立自己的逻辑。
一旦模型准备就绪,则可以进行测试。在测试时,将从模型从未见过的剩余20%数据中获得输入,模型将预测一些值,我们将其与实际输出进行比较并计算精度。
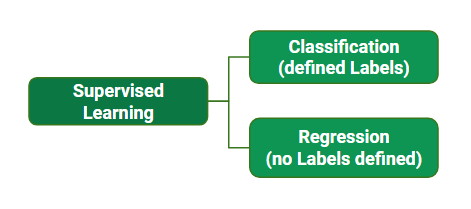
监督学习的类型:
- 分类:这是一项监督学习任务,其中输出具有定义的标签(离散值)。例如,在上图A中,“已购买的输出”已定义标签,即0或1; 1表示客户将购买,0表示客户将不购买。此处的目标是预测属于特定类别的离散值,并根据准确性进行评估。
它可以是二进制分类,也可以是多分类。在二元分类中,模型预测为0或1;是或否,但在多类别分类的情况下,模型预测不止一个类别。
示例: Gmail将邮件分为社交,促销,更新,论坛等多个类别。 - 回归:这是一项监督学习任务,其中输出具有连续值。
上图B中的示例,输出–风速没有任何离散值,但在特定范围内是连续的。这里的目标是预测一个尽可能接近我们模型所能达到的实际输出值的值,然后通过计算误差值来进行评估。误差越小,回归模型的准确性越高。
监督学习算法示例:
- 线性回归
- 最近的邻居
- 瓜西亚天真贝叶斯
- 决策树
- 支持向量机(SVM)
- 随机森林