决策树:决策树是用于分类和预测的最强大,最流行的工具。决策树是类似于树结构的流程图,其中每个内部节点表示对属性的测试,每个分支表示测试的结果,并且每个叶节点(终端节点)都具有类标签。
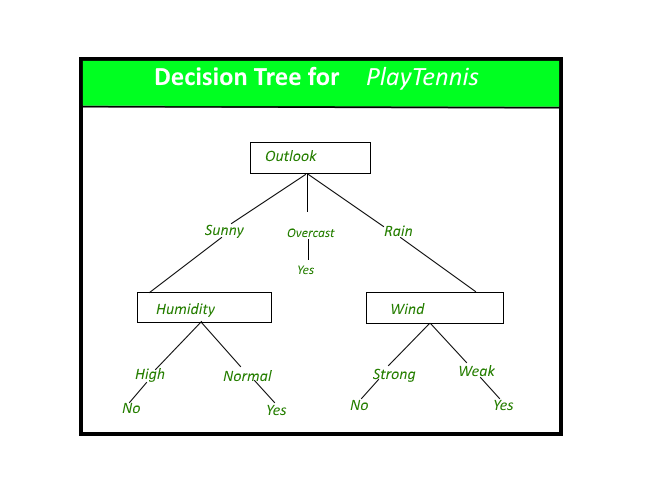
PlayTennis概念的决策树。
决策树的构建:
通过基于属性值测试将源集划分为子集,可以“学习”树。此过程在每个派生子集上以称为递归分区的递归方式重复进行。当节点上的子集都具有相同的目标变量值时,或者拆分不再为预测增加值时,递归完成。决策树分类器的构造不需要任何领域知识或参数设置,因此适合于探索性知识发现。决策树可以处理高维数据。一般而言,决策树分类器具有良好的准确性。决策树归纳是学习分类知识的典型归纳方法。
决策树表示:
决策树通过将实例从树的根部到某个叶节点进行分类来对实例进行分类,从而提供了实例的分类。通过从树的根节点开始对实例进行分类,测试该节点指定的属性,然后向下移动与该属性的值相对应的树枝,如上图所示。然后对子树重复此过程植根于新节点。
上图中的决策树根据是否适合打网球并返回与该特定叶子相关的分类对特定的早晨进行分类(在这种情况下为“是”或“否”)。
例如,实例
(Outlook = Rain, Temperature = Hot, Humidity = High, Wind = Strong )
将在此决策树的最左侧分支下排序,因此将其归类为否定实例。
换句话说,我们可以说决策树代表了对实例属性值的约束的合取的分离。
(Outlook = Sunny ^ Humidity = Normal) v (Outllok = Overcast) v (Outlook = Rain ^ Wind = Weak)
决策树方法的优缺点
决策树方法的优点是:
- 决策树能够生成可理解的规则。
- 决策树无需太多计算即可执行分类。
- 决策树能够处理连续变量和分类变量。
- 决策树清楚地表明了哪些字段对于预测或分类最重要。
决策树方法的缺点:
- 决策树不太适用于目标是预测连续属性值的估计任务。
- 决策树很容易在分类问题中出现错误,因为分类很多,训练示例相对较少。
- 决策树训练起来在计算上可能会很昂贵。增长决策树的过程在计算上是昂贵的。在每个节点上,必须先对每个候选拆分字段进行排序,然后才能找到其最佳拆分。在某些算法中,使用字段组合,必须进行搜索以获取最佳组合权重。修剪算法也可能很昂贵,因为必须形成并比较许多候选子树。
参考 :
机器学习,汤姆·米切尔(Tom Mitchell),麦格劳·希尔(McGraw Hill),1997年。
在下一篇文章中,我们将讨论IDR算法,该算法用于构造JR Quinlan给出的决策树。