数据挖掘中的高维数据聚类
聚类基本上是一种无监督学习方法。无监督学习方法是一种方法,其中我们从由没有标记响应的输入数据组成的数据集中提取参考。
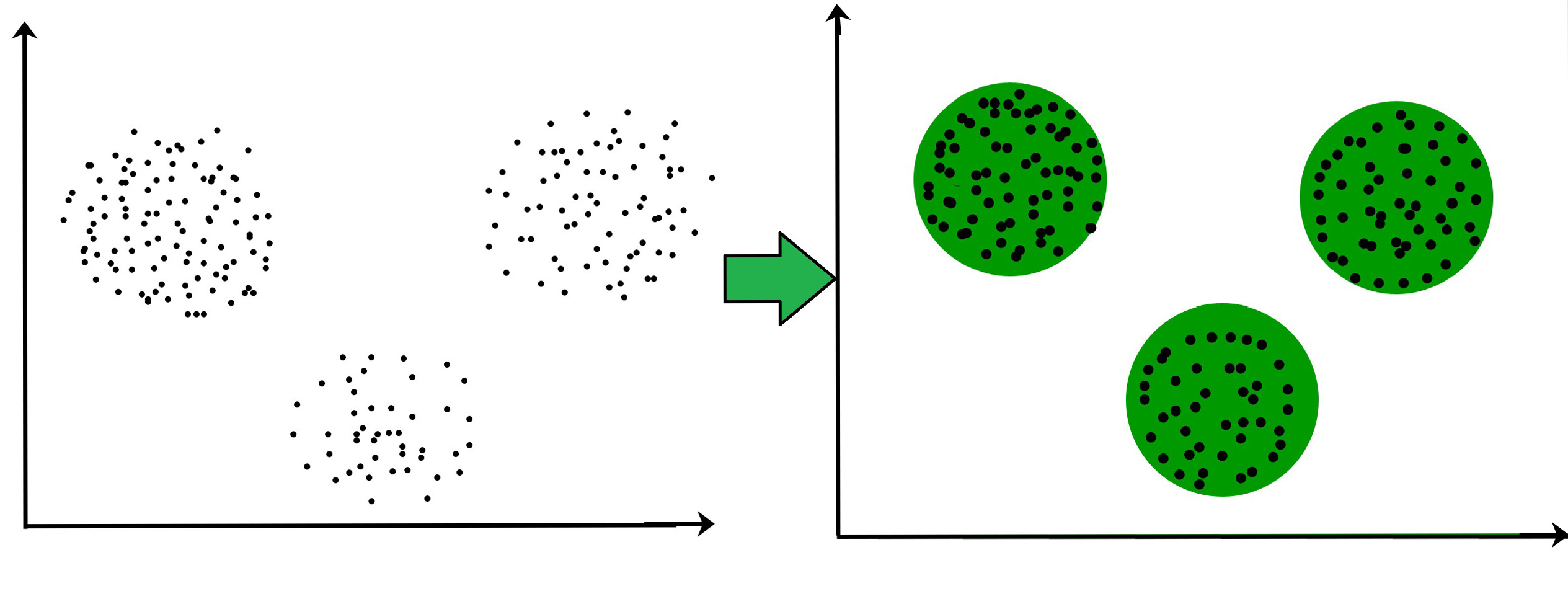
聚类是将总体或数据点划分为多个组的任务,以使同一组中的数据点与同一组中的其他数据点更相似,而与其他组中的数据点不相似。
聚类高维数据的挑战:
高维数据的聚类返回作为聚类的对象组。高维数据的聚类分析需要将相似类型的对象组合在一起进行聚类分析,但高维数据空间巨大,数据类型和属性复杂。一个主要挑战是我们需要找出每个集群中存在的属性集。基于集群中存在的属性定义和表征集群。聚类高维数据我们需要搜索聚类并找出现有聚类的空间。
将高维数据简化为低维数据,使聚类和搜索聚类变得简单。一些应用需要合适的集群模型,尤其是高维数据。高维数据中的簇非常小。传统的距离措施可能无效。相反,为了在高维数据中找到隐藏的集群,我们需要应用复杂的技术来模拟子空间中对象之间的相关性。
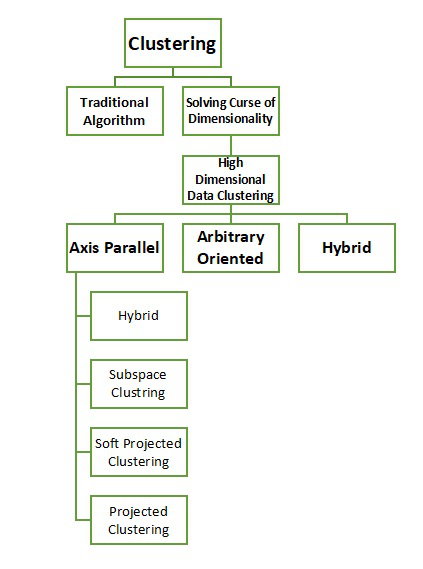
子空间聚类方法:
有 3 种子空间聚类方法:
- 子空间搜索方法
- 基于相关的聚类方法
- 双聚类方法
子空间聚类方法用于搜索存在于给定高维数据空间的子空间中的聚类,其中子空间是使用完整空间中的属性子集定义的。
1.子空间搜索方法:子空间搜索方法在子空间中搜索簇。这里,簇是子空间中一组相似类型的对象。聚类之间的相似性是通过使用距离或密度特征来衡量的。 CLIQUE 算法是一种子空间聚类方法。子空间搜索方法搜索一系列子空间。子空间搜索方法有两种方法: 自下而上的方法从低维子空间开始搜索。如果在低维子空间中找不到隐藏的簇,则它在高维子空间中搜索。自上而下的方法从高维子空间开始搜索,然后在低维子空间的子集中搜索。如果集群的子空间可以由本地邻域子空间集群定义,则自上而下的方法是有效的。
2. 基于相关的聚类:基于相关的方法通过开发高级相关模型来发现隐藏的集群。如果无法使用子空间搜索方法对对象进行聚类,则首选基于相关的模型。基于相关的聚类包括用于相关聚类分析的高级挖掘技术。双聚类方法是基于相关的聚类方法,其中对象和属性都被聚类。
3. 双聚类方法:
双聚类意味着基于两个因素对数据进行聚类。在某些应用程序中,我们可以同时聚类对象和属性。生成的集群是双集群。要执行双聚类,有四个要求:
- 只有一小部分对象参与集群。
- 一个集群只涉及少量的属性。
- 数据对象可以参与多个集群,或者对象也可以包含在任何集群中。
- 一个属性可能涉及多个集群。
对象和属性的处理方式不同。对象根据其属性值进行聚类。我们在双聚类分析中将对象和属性视为不同。