分层聚类方法通过将数据分组到聚类树中来工作。分层聚类首先将每个数据点视为一个单独的聚类。然后,它重复执行后续步骤:
- 确定可以最接近的 2 个集群,以及
- 合并 2 个最大的可比较集群。我们需要继续这些步骤,直到所有集群合并在一起。
在分层聚类中,目的是生成嵌套聚类的分层系列。称为树状图的图(树状图是一种树状图,用于统计合并或拆分的序列)以图形方式表示此层次结构,并且是一个倒置的树,用于描述因子合并(自下而上视图)或集群断开的顺序上(自上而下的视图)。
生成层次聚类的基本方法是:
1. 凝聚:
最初将每个数据点视为一个单独的集群,并在每一步合并最近的集群对。 (这是一种自下而上的方法)。首先,每个数据集都被视为单个实体或集群。在每次迭代中,簇与不同的簇合并,直到形成一个簇。
凝聚层次聚类的算法是:
- 计算一个集群与所有其他集群的相似度(计算邻近矩阵)
- 将每个数据点视为一个单独的集群
- 合并高度相似或彼此接近的集群。
- 重新计算每个集群的邻近矩阵
- 重复步骤 3 和 4,直到只剩下一个集群。
让我们使用树状图查看该算法的图形表示。
笔记:
这只是实际算法如何工作的演示,没有在假设集群之间的所有接近度的情况下执行计算。
假设我们有六个数据点A, B, C, D, E, F 。
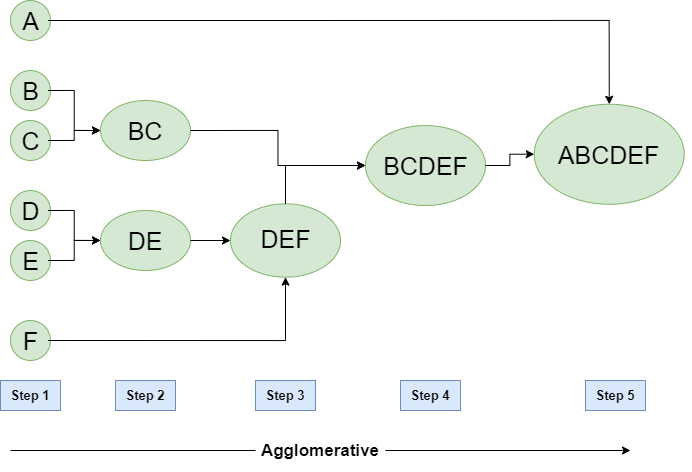
- 步骤1:
将每个字母表视为一个集群,并计算一个集群与所有其他集群的距离。 - 第2步:
在第二步中,可比较的集群合并在一起形成一个集群。假设集群 (B) 和集群 (C) 彼此非常相似,因此我们在第二步中将它们与集群 (D) 和 (E) 类似地合并,最后,我们得到集群
[(A), (BC), (DE), (F)] - 第 3 步:
我们根据算法重新计算接近度,并将最近的两个簇([(DE),(F)])合并在一起形成新的簇为[(A),(BC),(DEF)] - 第四步:
重复同样的过程;集群 DEF 和 BC 具有可比性并合并在一起形成一个新集群。我们现在剩下簇 [(A), (BCDEF)]。 - 第 5 步:
最后,剩下的两个簇合并在一起形成一个簇[(ABCDEF)]。
2.分裂:
我们可以说分裂层次聚类恰好与凝聚层次聚类相反。在 Divisive Hierarchical clustering 中,我们将所有数据点视为一个集群,并且在每次迭代中,我们将数据点与不可比较的集群分开。最后,我们剩下 N 个集群。
