使用 FastAPI 将 ML 模型部署为 API
部署通常是任何数据科学项目管道的最后一步,能够将您的 ML/DL 模型集成到 Web 应用程序是一项非常重要的任务。有许多流行的框架可用于执行此任务,例如 Flask 和 Django。 Django 通常用于大型应用程序,需要花费相当多的时间进行设置,而 Flask 通常是您在 Web 应用程序上快速部署模型的首选。除了上面提到的两个之外,还有另一个非常流行的框架,以至于像 Netflix 和 Uber 这样的公司都在使用它,这个框架就是 FastAPI。因此,让我们了解是什么让 FastAPI 如此受欢迎,以及如何使用它来将 ML 模型部署为使用它的 API。
FastAPI 与 Flask:
- FastAPI 比 Flask 快得多,不仅因为它还是目前最快的Python模块之一。
- 与 Flask 不同,FastAPI 为数据验证提供了更简单的实现,以定义您发送的数据的特定数据类型。
- 自动文档来调用和测试您的 API(Swagger UI 和 Redoc)。
- FastAPI 内置了对 Asyncio、GraphQL 和 Websockets 的支持。
安装 FastAPI:
安装 FastAPI 与任何其他Python模块相同,但与 FastAPI 一起,您还需要安装uvicorn以用作服务器。您可以使用以下命令安装它们:-
pip install fastapi uvicorn使用 FastAPI 创建基本 API:
在创建我们的 ML 模型之前,让我们先创建一个基本的 API,它将返回一个简单的消息。
Python3
# Importing Necessary modules
from fastapi import FastAPI
import uvicorn
# Declaring our FastAPI instance
app = FastAPI()
# Defining path operation for root endpoint
@app.get('/')
def main():
return {'message': 'Welcome to GeeksforGeeks!'}
# Defining path operation for /name endpoint
@app.get('/{name}')
def hello_name(name : str):
# Defining a function that takes only string as input and output the
# following message.
return {'message': f'Welcome to GeeksforGeeks!, {name}'}Python3
from fastapi import FastAPI
import uvicorn
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB
from pydantic import BaseModel
# Creating FastAPI instance
app = FastAPI()
# Creating class to define the request body
# and the type hints of each attribute
class request_body(BaseModel):
sepal_length : float
sepal_width : float
petal_length : float
petal_width : float
# Loading Iris Dataset
iris = load_iris()
# Getting our Features and Targets
X = iris.data
Y = iris.target
# Creating and Fitting our Model
clf = GaussianNB()
clf.fit(X,Y)
# Creating an Endpoint to recieve the data
# to make prediction on.
@app.post('/predict')
def predict(data : request_body):
# Making the data in a form suitable for prediction
test_data = [[
data.sepal_length,
data.sepal_width,
data.petal_length,
data.petal_width
]]
# Predicting the Class
class_idx = clf.predict(test_data)[0]
# Return the Result
return { 'class' : iris.target_names[class_idx]}测试我们的 API:
上面的代码定义了我们将命名为basic-app.py的文件中的所有路径操作。现在要运行这个文件,我们将在我们的目录中打开终端并编写以下命令:-
uvicorn basic-app:app --reload现在上面的命令遵循以下格式:-
- basic-app指的是我们在其中创建 API 的文件的名称。
- app指的是我们在文件中声明的 FastAPI 实例。
- –reload 告诉我们每次重新加载时重新启动服务器。
现在,在您运行此命令并转到http://127.0.0.1:8000/ 后,您将在浏览器中看到以下内容。
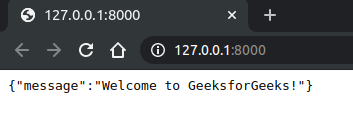
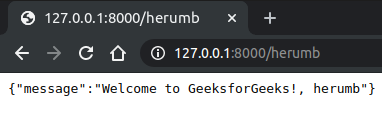
您看到此消息是因为您告诉 FastAPI 在调用根路径时将此作为响应返回。需要注意的一件事是我们的消息是一个Python字典,但它会自动转换为 JSON。现在,除此之外,您还有另一个端点,您可以在其中获取要显示在消息中的自定义字符串,要调用该字符串,请转到http://127.0.0.1:8000/herumb ,这里将在浏览器中显示以下消息.
交互式 API 文档:
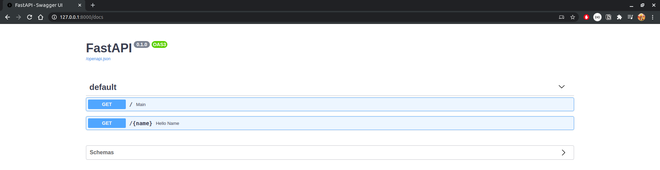
现在要获得上述结果,我们必须手动调用每个端点,但 FastAPI 附带交互式 API 文档,可以通过在您的路径中添加/docs来访问。要访问我们 API 的文档,我们将转到http://127.0.0.1:8000/docs。在这里,您将获得以下页面,您可以通过查看 API 的端点为相应输入(如果有)提供的输出来测试 API 的端点。您应该会看到我们 API 的以下页面。
部署我们的机器学习模型:
构建我们的模型:
在本教程中,我们将使用 GuassianNB 作为我们的模型和 iris 数据集来训练我们的模型。为了构建和训练我们的模型,我们使用以下代码:
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB
# Loading Iris Dataset
iris = load_iris()
# Getting features and targets from the dataset
X = iris.data
Y = iris.target
# Fitting our Model on the dataset
clf = GaussianNB()
clf.fit(X,Y)现在我们已经准备好了模型,我们需要定义我们将提供给模型以进行预测的数据格式。这一步很重要,因为我们的模型处理数值数据,我们不想将任何其他类型的数据提供给我们的模型,为了做到这一点,我们需要验证我们收到的数据是否符合该规范。
请求主体:
从客户端发送到 API 的数据称为请求正文。从 API 发送到客户端的数据称为响应正文。
为了定义我们的请求主体,我们将在pydantic模块中使用 BaseModel ,并定义我们将发送到 API 的数据格式。为了定义我们的请求主体,我们将创建一个继承 BaseModel 的类,并将特性定义为该类的属性及其类型提示。 pydantic 所做的是在运行时定义这些类型提示,并在数据无效时产生错误。所以让我们创建我们的 request_body 类:-
from pydantic import BaseModel
class request_body(BaseModel):
sepal_length : float
sepal_width : float
petal_length : float
petal_width : float终点:
现在我们有了一个请求正文,剩下要做的就是添加一个端点,该端点将预测该类并将其作为响应返回:
@app.post('/predict')
def predict(data : request_body):
test_data = [[
data.sepal_length,
data.sepal_width,
data.petal_length,
data.petal_width
]]
class_idx = clf.predict(test_data)[0]
return { 'class' : iris.target_names[class_idx]}然后我们将 ML 模型部署为 API。现在剩下要做的就是测试它。
测试我们的 API:
为了测试我们的 API,我们现在将使用 Swagger UI 来访问它,您只需要在路径的末尾添加/docs 。所以去http://127.0.0.1:8000/docs 。您应该会看到以下输出:
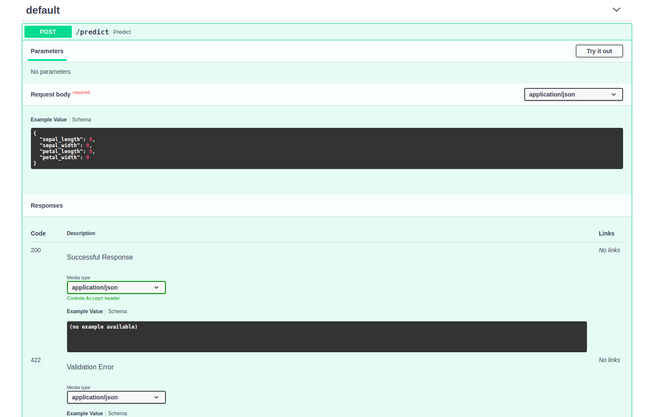
现在点击Try it Out按钮并输入您想要预测的数据:
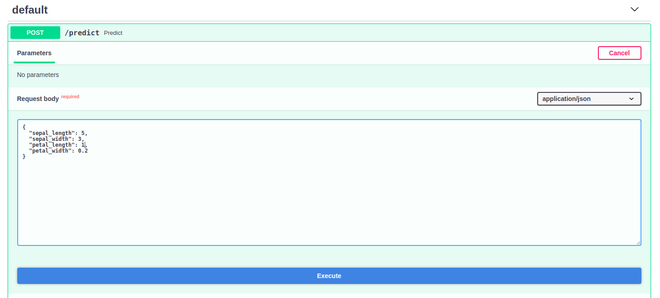
输入所有值后,单击“执行”,然后您可以在“响应”部分下看到您的输出:
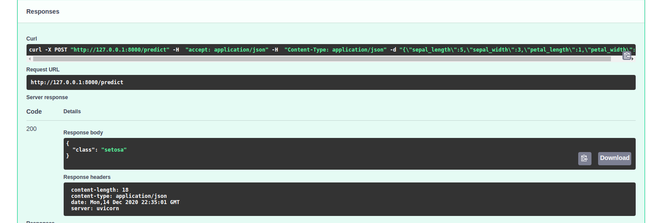
正如你所看到的,我们得到了我们的类作为响应。有了这个,我们已经成功地使用 FastAPI 将我们的 ML 模型部署为 API。
蟒蛇3
from fastapi import FastAPI
import uvicorn
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB
from pydantic import BaseModel
# Creating FastAPI instance
app = FastAPI()
# Creating class to define the request body
# and the type hints of each attribute
class request_body(BaseModel):
sepal_length : float
sepal_width : float
petal_length : float
petal_width : float
# Loading Iris Dataset
iris = load_iris()
# Getting our Features and Targets
X = iris.data
Y = iris.target
# Creating and Fitting our Model
clf = GaussianNB()
clf.fit(X,Y)
# Creating an Endpoint to recieve the data
# to make prediction on.
@app.post('/predict')
def predict(data : request_body):
# Making the data in a form suitable for prediction
test_data = [[
data.sepal_length,
data.sepal_width,
data.petal_length,
data.petal_width
]]
# Predicting the Class
class_idx = clf.predict(test_data)[0]
# Return the Result
return { 'class' : iris.target_names[class_idx]}