使用 CountVectorizer 从文本中提取特征
CountVectorizer是Python中 scikit-learn 库提供的一个很棒的工具。它用于根据每个单词在整个文本中出现的频率(计数)将给定文本转换为向量。当我们有多个这样的文本时,这很有帮助,并且我们希望将每个文本中的每个单词转换为向量(用于进一步的文本分析)。
让我们考虑一些来自文档的示例文本(每个都作为列表元素):
document = [ “One Geek helps Two Geeks”, “Two Geeks help Four Geeks”, “Each Geek helps many other Geeks at GeeksforGeeks.”]
CountVectorizer 创建一个矩阵,其中每个唯一单词由矩阵的一列表示,文档中的每个文本样本都是矩阵中的一行。每个单元格的值只不过是该特定文本样本中单词的计数。
这可以形象化如下——

主要意见:
- 文档中有 12 个唯一词,表示为表格的列。
- 文档中有 3 个文本样本,每个都表示为表格的行。
- 每个单元格都包含一个数字,表示该特定文本中单词的计数。
- 所有单词都已转换为小写。
- 列中的单词按字母顺序排列。
在 CountVectorizer 中,这些单词不存储为字符串。相反,它们被赋予特定的索引值。在这种情况下,“at”的索引为 0,“each”的索引为 1,“four”的索引为 2,依此类推。实际表现如下表所示——
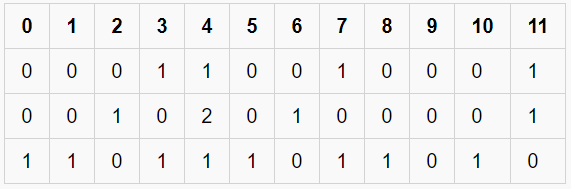
稀疏矩阵
这种表示方式称为稀疏矩阵。
代码:CountVectorizer 的Python实现
from sklearn.feature_extraction.text import CountVectorizer
document = ["One Geek helps Two Geeks",
"Two Geeks help Four Geeks",
"Each Geek helps many other Geeks at GeeksforGeeks"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
vectorizer.fit(document)
# Printing the identified Unique words along with their indices
print("Vocabulary: ", vectorizer.vocabulary_)
# Encode the Document
vector = vectorizer.transform(document)
# Summarizing the Encoded Texts
print("Encoded Document is:")
print(vector.toarray())
输出:
Vocabulary: {'one': 9, 'geek': 3, 'helps': 7, 'two': 11, 'geeks': 4, 'help': 6, 'four': 2, 'each': 1, 'many': 8, 'other': 10, 'at': 0, 'geeksforgeeks': 5}
Encoded Document is:
[ [0 0 0 1 1 0 0 1 0 1 0 1]
[0 0 1 0 2 0 1 0 0 0 0 1]
[1 1 0 1 1 1 0 1 1 0 1 0] ]