自然语言处理 | IOB 标签
什么是块?
块由词组成,词的种类是使用词性标签定义的。人们甚至可以定义不能成为chuck 一部分的模式或单词,这些单词被称为chinks。
什么是 IOB 标签?
它是块的一种格式。这些标签类似于词性标签,但可以表示块的内部、外部和开头。这里不仅允许名词短语,还允许多种不同的块短语类型。
示例:它是conll2000 语料库的摘录。每个单词都有一个词性标签,后跟一个 IOB 标签在自己的行上:
Mr. NNP B-NP
Meador NNP I-NP
had VBD B-VP
been VBN I-VP
executive JJ B-NP
vice NN I-NP
president NN I-NP
of IN B-PP
Balcor NNP B-NP这是什么意思 ?
B-NP :名词短语的开头
I-NP :描述单词在当前名词短语的内部。
O :句末。
B-VP 和 I-VP :动词短语的开头和内部。
代码 #1:它是如何工作的——用 IOB 标签分块单词。
Python3
# Loading the libraries
from nltk.corpus.reader import ConllChunkCorpusReader
# Initializing
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_words()
reader.iob_words()Python3
# Loading the libraries
from nltk.corpus.reader import ConllChunkCorpusReader
# Initializing
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_sents()
reader.iob_sents()Python3
# Loading the libraries
from nltk.corpus.reader import ConllChunkCorpusReader
# Initializing
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_words()[0].leaves()
reader.chunked_sents()[0].leaves()
reader.chunked_paras()[0][0].leaves()输出 :
[Tree('NP', [('Mr.', 'NNP'), ('Meador', 'NNP')]), Tree('VP', [('had', 'VBD'),
('been', 'VBN')]), ...]
[('Mr.', 'NNP', 'B-NP'), ('Meador', 'NNP', 'I-NP'), ...]代码#2:它是如何工作的——用 IOB 标签分块句子。
Python3
# Loading the libraries
from nltk.corpus.reader import ConllChunkCorpusReader
# Initializing
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_sents()
reader.iob_sents()
输出 :
[Tree('S', [Tree('NP', [('Mr.', 'NNP'), ('Meador', 'NNP')]),
Tree('VP', [('had', 'VBD'), ('been', 'VBN')]),
Tree('NP', [('executive', 'JJ'), ('vice', 'NN'), ('president', 'NN')]),
Tree('PP', [('of', 'IN')]), Tree('NP', [('Balcor', 'NNP')]), ('.', '.')])]
[[('Mr.', 'NNP', 'B-NP'), ('Meador', 'NNP', 'I-NP'), ('had', 'VBD', 'B-VP'),
('been', 'VBN', 'I-VP'), ('executive', 'JJ', 'B-NP'), ('vice', 'NN', 'I-NP'),
('president', 'NN', 'I-NP'), ('of', 'IN', 'B-PP'), ('Balcor', 'NNP', 'B-NP'),
('.', '.', 'O')]]让我们理解上面的代码:
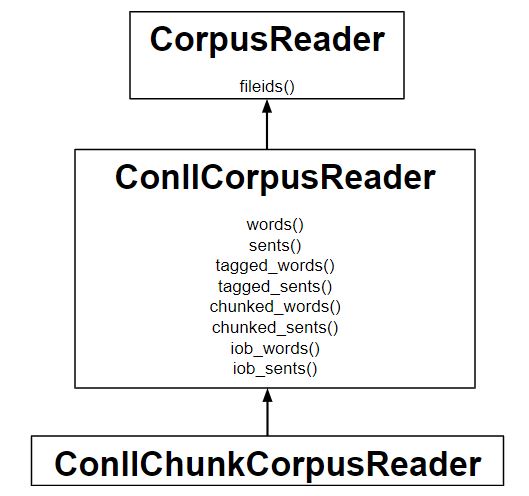
- 为了读取 IOB 格式的语料库,使用了 ConllChunkCorpusReader 类。
- 没有段落分隔,每个句子都用空行分隔,因此 para_* 方法不可用。
- 指定文件中块类型的元组或列表,如 ('NP', 'VP', 'PP') 作为 ConllChunkCorpusReader 的第三个参数。
- iob_words() 和 iob_sents() 方法返回 (word, pos, iob) 的三个元组的列表
代码#3:树叶——即标记的令牌
Python3
# Loading the libraries
from nltk.corpus.reader import ConllChunkCorpusReader
# Initializing
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_words()[0].leaves()
reader.chunked_sents()[0].leaves()
reader.chunked_paras()[0][0].leaves()
输出 :
[('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]
[('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS'),
('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'), ('300', 'CD'),
('jobs', 'NNS'), (', ', ', '), ('the', 'DT'), ('spokesman', 'NN'),
('said', 'VBD'), ('.', '.')]
[('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS'),
('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'), ('300', 'CD'),
('jobs', 'NNS'), (', ', ', '), ('the', 'DT'), ('spokesman', 'NN'),
('said', 'VBD'), ('.', '.')]