珀尔 |贪婪和非贪婪匹配
正则表达式(Regex/RE)是用于模式匹配的字符序列。或者我们可以说它是一种描述一组字符串的方式,而不必列出程序中的所有字符串。我们可以通过使用模式绑定运算符=~和!~来应用正则表达式。正则表达式运算符=~用于测试正则表达式匹配。
示例:让我们将/geeks/视为正则表达式。它会匹配
Geeksforgeeks
Computergeeks但不是
Ge12eksg22eeks
Geeksg*eks而!~确定正则表达式应用于哪个变量,并否定匹配结果;如果匹配成功则返回 false,如果失败则返回 true。考虑上面的例子,我们得到的表达式为真将被视为假,假正则表达式为真。它提供了使用=~时获得的结果的否定。模式匹配:它是一种在给定字符串中找出特定字符序列或模式的方法。在 Perl 中,我们有三个正则表达式运算符。他们是:
Match Regular Expression - m//
Substitute Regular Expression - s///
Transliterate Regular Expression - tr///示例 1:使用匹配运算符
#!usr/bin/perl
# Perl program to search the substring "or"
# in the word GeeksForGeeks
# String to find pattern from
$a = "GeeksForGeeks";
# Using m operator to find substring
if($a = ~m/or/)
{
print "Found 'or' in the string ";
}

在上面的示例中,模式匹配是使用匹配运算符' m// '在字符串中搜索特定子字符串完成的。如果在字符串中找到该模式,它将返回 true。
示例 2:使用替换运算符
#!/usr/bin/perl
# Perl program to replace the substring "For"
# in the word GeeksForGeeks
# String to perform substitution on
$a = "GeeksForGeeks";
# Using substitution operator to replace
$a = ~s/For/And/;
print "$a";

这里,替换运算符' s/// '用于用给定文本替换字符串中的模式。如果模式存在,那么它将被替换,否则它将返回 false。
示例 3:使用音译运算符
#!/usr/bin/perl
# Perl program to replace all occurrences
# of a pattern in the string
# String to be used
$string = 'GeeksForGeeks';
# Replace 'G' with 'S' using
# transliterator operator
$string =~ tr/G/S/;
# Printing the final string
print "$string\n";

在这里,搜索字符串以查找所有出现的字符“G”,并使用音译运算符“ tr/// ”将其替换为另一个字符“S”。即使没有进行替换,它也永远不会返回 false。
贪心匹配和非贪心匹配
在 RE 中匹配的常用规则有时称为“最左最长”:当一个模式可以在一个字符串中的多个位置匹配时,选择的匹配将是从字符串中最早可能位置开始的字符串,然后尽可能地延伸。通常 Perl 模式匹配是贪婪的。贪婪是指解析器尝试尽可能多地匹配。例如,在字符串abcbcbcde中,模式
贪心和非贪心匹配/(bc)+/可以有六种不同的匹配方式,如图所示:

在上图中,这些匹配模式中的第三个是“最左边最长的”,也称为贪婪模式。然而,在某些情况下,可能需要获得“最左边最短”或最小匹配。我们可以使用 ' 将贪婪匹配变成非贪婪匹配。 ' 在 RE 的末尾即 ' *? ' 匹配允许整体匹配成功的前面子表达式的最小实例数。同样,' +? ' 匹配至少一个实例,但不超过使整个匹配成功所必需的,并且 ' ?? ' 匹配零个或一个实例,偏好为零。 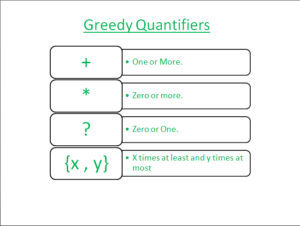
示例:贪心模式匹配
#!/usr/bin/perl
# Perl program to show greedy matching
$var = "Geeks For Geeks";
# Matching pattern from k to s
$var =~ /(k.*s)(.*)$/;
# Printing the resultant string
print($1, "\n");

在这里我们可以看到,代码将从 k 开始匹配到 s,并且尽可能匹配。
示例:非贪婪模式匹配
#!/usr/bin/perl
# Perl program to show non-greedy matching
my $str = "Geeks For Geeks";
# Matching pattern from k to s
$str =~ /.*?\s(.*)/;
# Printing Resultant string
print($1);

与非贪婪运算符比较时,它将匹配最少的代码。