使用 Facebook Prophet 进行时间序列分析
Prophet 是 Facebook 的一个开源工具,用于预测时间序列数据,帮助企业了解并可能预测市场。它基于可分解的加法模型,其中非线性趋势与季节性相匹配,它还考虑了假期的影响。在我们直接开始编码之前,让我们学习理解这一点所需的某些术语。
趋势:
趋势显示了数据在很长一段时间内增加或减少的趋势,并过滤掉了季节性变化。
季节性:
季节性是在短时间内发生的变化,并不足以称为“趋势”。
了解先知模型
该模型的总体思想类似于广义加法模型。如上所述,“先知方程”适合趋势、季节性和假期。这是由,
在哪里,
- g(t) 指趋势(长期变化)
- s(t) 是指季节性(周期性或短期变化)
- h(t) 指假期对预测的影响
- e(t) 是指特定于企业或个人或环境的无条件更改。它也被称为误差项。
- y(t) 是预测值。
这似乎很容易,那么为什么我们需要像 Prophet 这样的工具来帮助我们进行预测呢?
我们需要它是因为,虽然基本的可分解加法模型看起来很简单,但其中的项的计算是非常数学化的,如果您不知道自己在做什么,可能会导致做出错误的预测,这可能会在现实世界中产生严重的影响.所以为了自动化这个过程,我们将使用 Prophet。
但是,要了解此过程背后的数学原理以及 Prophet 的实际工作原理,让我们看看它如何预测数据。
Prophet 为我们提供了两种模型(不过,可以根据具体要求编写或扩展较新的模型)。一种是逻辑增长模型,另一种是分段线性模型。默认情况下,Prophet 使用分段线性模型,但可以通过指定模型进行更改。选择模型是很微妙的,因为它取决于公司规模、增长率、商业模式等多种因素,如果要预测的数据具有饱和和非线性数据(非线性增长并且达到饱和点,几乎没有增长或收缩,仅表现出一些季节性变化),那么逻辑增长模型是最佳选择。然而,如果数据显示线性特性并且过去有增长或收缩趋势,那么分段线性模型是更好的选择。
使用以下统计方程拟合逻辑增长模型,
(1) 
在哪里,
- C是承载能力
- k 是增长率
- m 是偏移参数
分段线性模型使用以下统计方程拟合,
(2) 
其中 c 是趋势变化点(它定义了趋势的变化)。 ?是趋势参数,可以根据预测的需要进行调整。
下载数据集:
现在让我们用一个真实的例子来使用这些知识。考虑航空乘客数据集(请打开下面的链接并保存 .csv 文件)
https://raw.githubusercontent.com/rahulhegde99/Time-Series-Analysis-and-Forecasting-of-Air-Passengers/master/airpassengers.csv
上述数据集包含 1949 年 1 月至 1960 年 12 月美国航空旅客人数。数据的频率为 1 个月。现在让我们尝试构建一个模型,该模型将使用时间序列分析来预测未来五年的乘客数量。
安装
为数据操作和数据帧数据结构安装 Pandas。
pip install pandas
安装 Prophet 进行时间序列分析和预测。
pip install fbprophet
注意:如果您不想在本地安装模块,请使用 Jupyter Notebooks 或 Google Colab。
执行:
代码:导入所有需要的模块
import pandas as pd
from fbprophet import Prophet
from fbprophet.plot import add_changepoints_to_plot
代码:读取之前下载的 .csv 文件并显示。
data = pd.read_csv('https://raw.githubusercontent.com/rahulhegde99/Time-Series-Analysis-and-Forecasting-of-Air-Passengers/master/airpassengers.csv')
data.head()
输出:

Facebook Prophet 仅在数据采用某种格式时才能预测数据。包含数据的数据框应将列保存为时间序列数据的ds和要预测的数据的y 。在这里,时间序列是Month列,要预测的数据是#Passengers列。所以让我们用新的列名和相同的数据创建一个新的数据框。此外, ds应该是日期时间格式。
代码:
df = pd.DataFrame()
df['ds'] = pd.to_datetime(data['Month'])
df['y'] = data['#Passengers']
df.head()

代码:初始化一个模型并将我们的数据框df拟合到它。
m = Prophet()
m.fit(df)
我们希望我们的模型预测未来 5 年,即到 1965 年。我们的数据频率是 1 个月,因此 5 年是 12*5=60 个月。因此,我们需要向数据框中添加 60 到更多行的月度数据。
代码:
future = m.make_future_dataframe(periods=12 * 5, freq='M')
现在在未来的数据帧中,我们只有ds值,我们应该预测y值。
代码:
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper', 'trend', 'trend_lower', 'trend_upper']].tail()
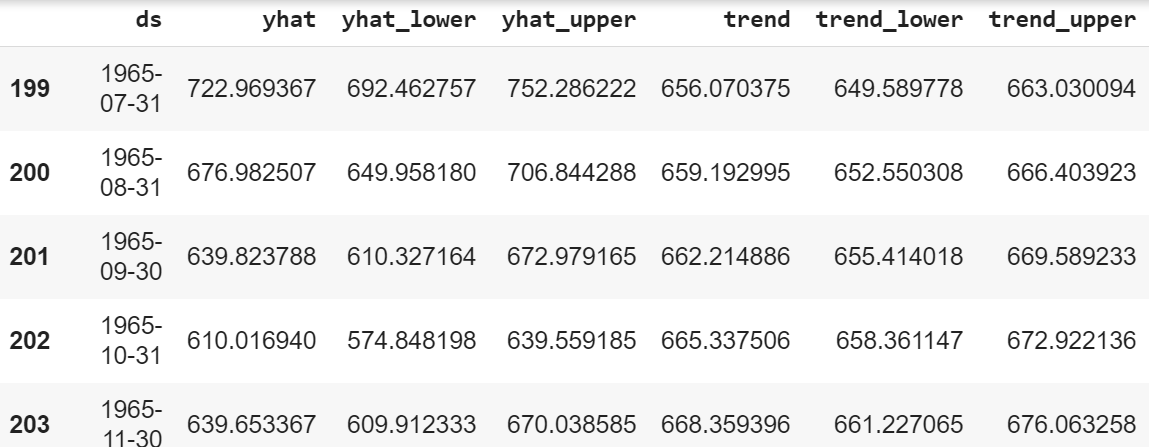
我们知道,在表ds中,是时间序列数据。 yhat是预测, yhat_lower和yhat_upper是不确定性级别(它基本上意味着预测值和实际值可以在不确定性级别的范围内变化)。接下来是趋势,显示数据的长期增长、收缩或停滞, trend_lower和trend_upper是不确定性水平。
代码:绘制预测数据。
fig1 = m.plot(forecast)
下图显示了基本预测。浅蓝色是不确定性水平( yhat_upper和yhat_lower ),深蓝色是预测( yhat ),黑点是原始数据。我们可以看到预测数据与实际数据非常接近。在过去的五年中,没有“实际”数据,但看看我们的模型在有数据的年份的表现,可以肯定地说预测接近准确。

fig2 = m.plot_components(forecast)
下图显示了时间序列数据的趋势和季节性(一年)。我们可以看到有增加的趋势,这意味着航空乘客的数量随着时间的推移而增加。如果我们查看季节性图表,我们可以看到 6 月和 7 月是特定年份乘客最多的时间。
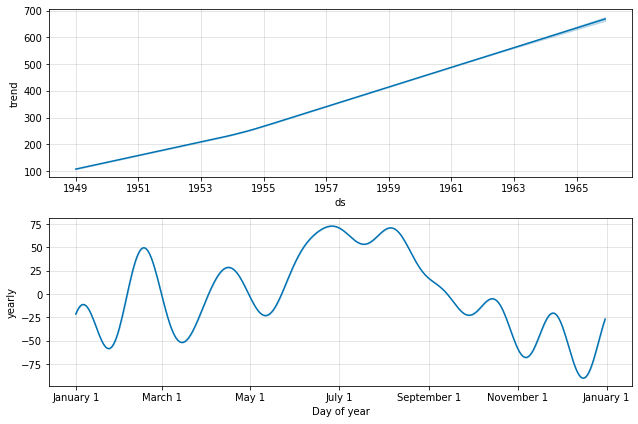
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
添加变化点以指示快速趋势增长的时间。虚线红线表示乘客趋势发生快速变化的时间。

脚注:
因此,我们已经看到了如何使用 Facebook Prophet 设计一个预测模型,只需要几行代码,单独使用传统的机器学习算法和数学和统计概念很难实现。