- 词性(POS)标记的基础
- 词性(POS)标记的基础(1)
- 自然语言处理 |词性 - 默认标记
- z pos css (1)
- z pos css 代码示例
- PHP | pos()函数(1)
- PHP | pos()函数
- OpenNLP-查找词性(1)
- OpenNLP-查找词性
- 强标记 (1)
- unity 在 x 秒内移动到 pos - C# (1)
- Python中的 turtle.pos() 方法(1)
- Python中的 turtle.pos() 方法
- html中的标记标记(1)
- unity 在 x 秒内移动到 pos - C# 代码示例
- html代码示例中的标记标记
- Sum(POS)的乘积(1)
- Sum(POS)的乘积
- Python|使用 spaCy 的 PoS 标记和词形还原
- Python|使用 spaCy 的 PoS 标记和词形还原(1)
- Python标记化(1)
- Python标记化
- 珀尔 |正则表达式中的 pos()函数(1)
- 珀尔 |正则表达式中的 pos()函数
- 自然语言处理 |词性标签——词库
- 要标记的 C# 数组 - C# (1)
- 转换为 POS 在线计算器 (1)
- 在C++中标记字符串(1)
- 在C++中标记字符串
📅 最后修改于: 2020-11-23 04:42:04 🧑 作者: Mango
标记是一种分类,可以定义为对令牌的描述自动分配。在这里,描述符称为标签,它可以表示词性,语义信息等之一。
现在,如果我们谈论词性(PoS)标记,则可以将其定义为将词性之一分配给给定单词的过程。通常称为POS标记。用简单的话来说,可以说POS标记是用适当的词性标记句子中的每个词的任务。我们已经知道,词性包括名词,动词,副词,形容词,代词,连词及其子类别。
大部分POS标记属于Rule Base POS标记,随机POS标记和基于转换的标记。
基于规则的POS标记
标记的最古老的技术之一是基于规则的POS标记。基于规则的标记者使用字典或词典来获取标记每个单词的可能标记。如果单词有多个可能的标记,则基于规则的标记者将使用手写的规则来识别正确的标记。还可以通过分析单词及其前后单词的语言特征,在基于规则的标记中执行消歧。例如,假设单词的前一个单词是冠词,则单词必须是名词。
顾名思义,基于规则的POS标记中的所有此类信息均以规则的形式编码。这些规则可能是-
-
上下文模式规则
-
或者,正则表达式编译成有限状态自动机时,与词汇模糊的句子表示形式相交。
我们还可以通过其两阶段架构来理解基于规则的POS标记-
-
第一阶段-在第一阶段,它使用字典为每个单词分配潜在的词性列表。
-
第二阶段-在第二阶段,它使用手写的歧义消除规则大列表将列表分类为每个单词的单个词性。
基于规则的POS标记的属性
基于规则的POS标记器具有以下属性-
-
这些标记器是知识驱动的标记器。
-
基于规则的POS标记中的规则是手动构建的。
-
信息以规则的形式编码。
-
我们大约有1000条规则,数量有限。
-
在基于规则的标记器中明确定义了平滑和语言建模。
随机POS标记
标记的另一种技术是随机POS标记。现在,这里出现的问题是哪种模型可以是随机的。包含频率或概率(统计量)的模型可以称为随机模型。解决词性标记问题的许多不同方法都可以称为随机标记器。
最简单的随机标记器将以下方法应用于POS标记-
词频法
在这种方法中,随机标记器根据单词与特定标签一起出现的概率来消除单词歧义。我们也可以说,训练集中的单词最常遇到的标记是分配给该单词歧义实例的标记。这种方法的主要问题是它可能会产生不可接受的标签序列。
标签序列概率
这是随机标记的另一种方法,其中标记器计算给定标记序列出现的概率。也称为n-gram方法。之所以这样称呼,是因为给定单词的最佳标签由n个先前的标签出现的概率决定。
随机POST标记的属性
随机POS标记器具有以下属性-
-
该POS标记基于标记发生的可能性。
-
需要训练语料
-
语料库中不存在的单词将不可能。
-
它使用不同的测试语料库(训练语料库除外)。
-
这是最简单的POS标记,因为它会选择与训练语料库中的单词相关的最频繁的标记。
基于转换的标记
基于转换的标记也称为Brill标记。它是基于转换的学习(TBL)的一个实例,它是用于将POS自动标记到给定文本的基于规则的算法。 TBL允许我们以可读的形式拥有语言知识,通过使用转换规则将一种状态转换为另一种状态。
它从先前解释的标记器(基于规则的和随机的)中汲取了灵感。如果我们看到基于规则的标记器和转换标记器之间的相似性,那么就像基于规则的标记器一样,它也基于指定哪些标记需要分配给哪些单词的规则。另一方面,如果我们看到随机标记和转换标记器之间的相似性,则类似于随机标记,这是机器学习技术,其中从数据自动得出规则。
基于转换的学习(TBL)的工作
为了了解基于转换的标记器的工作原理,我们需要了解基于转换的学习器的工作原理。考虑以下步骤以了解TBL的工作方式-
-
从解决方案开始-TBL通常从某种解决方案开始,并以循环的方式工作。
-
选择最有益的转化-在每个周期中,TBL将选择最有益的转化。
-
适用于问题-在最后一步中选择的变换将适用于问题。
当在步骤2中选择的转换不会增加更多的值或没有更多的转换要选择时,算法将停止。这种学习最适合分类任务。
变革型学习(TBL)的优势
TBL的优点如下-
-
我们学习了一小组简单的规则,这些规则足以进行标记。
-
在TBL中,开发和调试非常容易,因为学习的规则很容易理解。
-
标记的复杂性降低了,因为在TBL中,机器学习的规则和人工生成的规则相互交织。
-
基于转换的标记器比Markov模型标记器快得多。
基于转换的学习(TBL)的缺点
TBL的缺点如下-
-
基于转换的学习(TBL)不提供标签概率。
-
在TBL中,培训时间非常长,尤其是在大型语料库上。
隐马尔可夫模型(HMM)POS标记
在深入研究HMM POS标记之前,我们必须了解隐马尔可夫模型(HMM)的概念。
隐马尔可夫模型
HMM模型可以定义为双嵌入随机模型,其中隐藏了潜在的随机过程。这种隐藏的随机过程只能通过产生观察序列的另一组随机过程来观察。
例
例如,完成了一系列隐藏的抛硬币实验,我们只看到由头和尾组成的观察序列。该过程的实际细节-使用了多少枚硬币,选择硬币的顺序-对我们而言是隐藏的。通过观察头和尾的顺序,我们可以构建几个HMM来解释该顺序。以下是此问题的隐马尔可夫模型的一种形式-
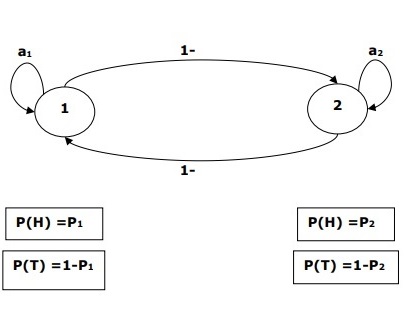
我们假设HMM中有两个状态,每个状态对应于不同偏向硬币的选择。以下矩阵给出状态转移概率-
$$ A = \ begin {bmatrix} a11&a12 \\ a21&a22 \ end {bmatrix} $$
这里,
-
a ij =从i到j从一种状态转换到另一种状态的概率。
-
a 11 + a 12 = 1和a 21 + a 22 = 1
-
P 1 =第一个硬币的正面概率,即第一个硬币的偏差。
-
P 2 =第二枚硬币正面的概率,即第二枚硬币的偏差。
我们还可以创建HMM模型,假设存在3个或更多的硬币。
这样,我们可以通过以下元素来表征HMM-
-
N,即模型中的状态数(在上面的示例中,N = 2,只有两个状态)。
-
M,在上述示例中,每种状态可以出现的不同观测值的数量M = 2,即H或T)。
-
A,状态转移概率分布-上例中的矩阵A。
-
P,每种状态下可观察符号的概率分布(在我们的示例P1和P2中)。
-
一,初始状态分布。
使用HMM进行POS标记
POS标记过程是查找最有可能产生给定单词序列的标记序列的过程。我们可以通过使用隐马尔可夫模型(HMM)对此POS过程进行建模,其中标记是产生可观察到的输出(即单词)的隐藏状态。
从数学上讲,在POS标记中,我们始终对找到最大化-
P(C | W)
哪里,
C = C 1 ,C 2 ,C 3 … C T
W = W 1 ,W 2 ,W 3 ,W T
另一方面,事实是我们需要大量的统计数据才能合理地估计此类序列。但是,为简化问题,我们可以应用一些数学变换以及一些假设。
使用HMM进行POS标记是贝叶斯干扰的一种特殊情况。因此,我们将开始使用贝叶斯规则重新陈述问题,该规则表示上述条件概率等于-
(PROB(C 1 ,…,WT)* PROB(W 1 ,…,WT | C 1 ,…,CT))/ PROB(W 1 ,…,WT)
在所有这些情况下,我们都可以消除分母,因为我们有兴趣寻找使上述值最大化的序列C。这不会影响我们的答案。现在,我们的问题减少到找到最大化-
PROB(C 1 ,…,CT)* PROB(W 1 ,…,WT | C 1 ,…,CT) (1)
即使在减少了上面表达式中的问题之后,也将需要大量数据。我们可以对上述表达式中的两个概率做出合理的独立性假设,以解决该问题。
第一次假设
标签的概率取决于前一个标签(二元模型)或前两个标签(三元模型)或前n个标签(n元模型),在数学上可以解释如下-
PROB(C 1 ,…,C T )= i i = 1..T PROB(C i | C i-n + 1 …C i-1 ) (n-gram模型)
PROB(C 1 ,…,CT)= i i = 1..T PROB(C i | C i-1 ) (二元模型)
可以通过假设每个标签的初始概率来说明句子的开头。
PROB(C 1 | C 0 )= PROB初始值(C 1 )
二次假设
可以通过假设一个单词出现在与先前或后续类别中的单词无关的类别中来近似计算上述等式(1)中的第二个概率,可以用以下数学解释-
PROB(W 1 ,…,W T | C 1 ,…,C T )= i i = 1..T PROB(W i | C i )
现在,基于以上两个假设,我们的目标减少到找到一个最大化
i i = 1 … T PROB(C i | C i-1 )* PROB(W i | C i )
现在这里出现的问题是将问题转换成上述形式确实对我们有所帮助。答案是-是的。如果我们有一个较大的标记语料库,那么上式中的两个概率可以计算为-
PROB(C i = VERB | C i-1 = NOUN )=(动词跟随名词的实例数量)/(出现名词的实例数量)(2)
PROB(W i | C i )=(W i在C i中出现的实例数)/(在C i中出现的实例数)(3)