编译器设计中的深度优先排序
图的第一次深度搜索访问图中的所有节点一次,从入口点开始,尽可能快地访问尽可能远的节点。深度搜索的搜索路径创建第一个可扩展树 (DFST)。在访问任何当地儿童之前先访问该网站,他们也从左到右反复访问。此外,在访问站点本身之前,后序遍历访问节点子节点,从左到右依次重复。流图分析中有一个重要的不同顺序:第一个深度的顺序是后序遍历的后退。也就是说,在第一个深度,我们访问该节点,然后将其子节点切到右边、左边等等。但是,在构建流图树之前,我们需要决定哪个节点跟随者成为树中的右孩子,哪个节点成为左孩子,等等。
深度优先排序:
使用数据流解决方案策略的数据流分析的复杂性已显示为一系列节点。在这种情况下,定义了一个称为流程图深度的值,以确定所需的最大重复次数。这需要以特定顺序而不是随机顺序来考虑基本块。首先,给流程图节点一个编号,称为第一深度编号。图节点的第一个数字 (dfu) 的深度是对我们上次访问图的前序块中每个节点的方式的扭曲。
特性:
深度优先排序具有以下属性:
- Vi € dominators(j), dfn(i)
- Vforward 边 (i, j), dfn(i) < dfn(j) 和
- Vbackward 边缘 (i, j), dfn(j) < dfn(i)。
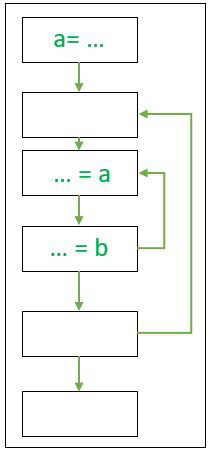
流程图
系统流图的 d 深度是其中任何非循环路径上的最大后边数。可能需要注意的是,它与嵌套的深度不同。例如,在上面的流程图中,嵌套深度为 2,但深度 d 等于 1。
反复分析最重要的结果如下:
对于前向数据流问题,当以深度序列的方式访问图时,重复 d + 1 次足以达到固定点。对于数据回传问题,节点的访问深度应与一阶相同。可以通过以下观察来证明这一点:
- 对于数据转发问题,我们按照初始数字的深度递增顺序访问节点。如果系统中没有环路,即d-0,那么计算机在第一次复制时输入的数据流信息可能是数据流统计的一个固定点。
- 如果系统中存在一个回路,则 d-1。现在,对于新的循环释放值,第一个副本中列出的节点会影响循环入口节点的属性。这只能在随后的重复中实现。因此,需要重复两次。
DFS的算法表示:

DFS的算法表示
后边缘和可还原性:
后边缘是边缘a -> b,其中它的头部 b 支配尾部 a。在 Flow Graph 中,整个后边缘是反转的,但并非所有后边缘都是反转的。如果流图在任何深度拉伸树上的所有斜靠端都是后边缘,则称该流图是不可逆的。但是,如果图不能最小化,则所有后端都是任何 DFST 的斜边,但每个 DFST 可能具有除后端之外的其他斜边。这些可伸缩的边缘可能因一个 DFST 而异。
因此,如果我们删除了流动图的所有后边,而剩下的图是圆形的,则该图不能减少,反之亦然。性能中出现的流程图几乎总是减少。系统化流控制语句的特殊使用,例如 then、while-doing、continuous 和 break 语句会产生流图不断反转的系统。即使是使用 goto 语句编写的程序也经常看起来是可简化的,因为编辑器在逻辑上会考虑陷阱和分支。
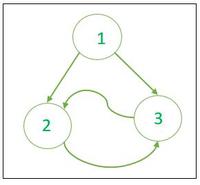
不可约流图
对于上面初始节点为 1 的 Flow 图,节点 1 支配节点 2 和 3,但 2 不统治 3,反之亦然。因此,该流程图没有后边,因为它没有控制其尾部的边的头部。有两棵树可以是第一个深度,这取决于我们选择从 search (l) 中首先调用 search (2) 还是 search (3)。在第一种情况下,边 3 -> 2 是斜边,但不是后边;在第二种情况下,2 -> 3 是一个倾斜的边缘——但不向后。可以理解,这个流程图没有减少的原因是循环 2-3 可以安装在两个不同的位置,节点 2 和 3。