情感分析中的方面建模
先决条件:情绪分析
在深入了解方面建模的细节之前,让我们首先通过一个现实生活中的例子来简要了解什么是情感分析。
情绪分析(SA):
这是一种根据一个人所写的一段文字来区分一个人对某事或某人的感受的技术。它可以是积极的、消极的或中性的。让我们考虑一个现实生活中的例子。
我们每天都会在 Twitter 上看到数百万条推文。在这里,我们可以建立一个情感分析模型来确定他们对特定主题的态度是快乐、悲伤、愤怒还是中立。这种技术目前的局限性在于检测讽刺。
情感分析中的方面建模(ABSA):
方面建模是一种高级文本分析技术,是指将文本输入分解为方面类别及其方面术语,然后识别整个文本输入中每个方面背后的情感的过程。该模型中的两个关键术语是:
- 情绪:对特定方面的正面或负面评价
- 方面:正在观察的类别、特征或主题。
要求
在商业世界中,总是需要确定观察人们对特定产品或服务的情绪,以确保他们对其业务产品的持续兴趣。 ABSA 通过识别每个方面类别(如食物、位置、氛围等)背后的情绪来实现这一目的。
这有助于企业在其业务的每个领域跟踪客户不断变化的情绪。
ABSA 架构
ABSA 模型包括以下步骤以获得所需的输出。
Step 1 - Consider the input text corpus and pre-process the dataset.
Step 2 - Create Word Embeddings of the text input. (i.e. vectorize the text input
and create tokens.)
Step 3.a - Aspect Terms Extraction -> Aspect Categories Model
Step 3.b - Sentiment Extraction -> Sentiment Model
Step 4 - Combine 3.a and 3.b to create to get Aspect Based Sentiment.(OUTPUT)直觉:
方面:它被定义为意见或情绪所基于的概念。让我们举一个例子来更好地理解。
假设一家公司构建了一个运行缓慢但提供高精度可靠结果的网络应用程序。在这里,我们将这段文字分为两个方面。 “ Web 应用程序运行缓慢”和“准确度高的可靠结果”。通过观察这两个方面类别,您可以很容易地得出结论,它们具有与之相关的不同情绪。 (如图1所示)
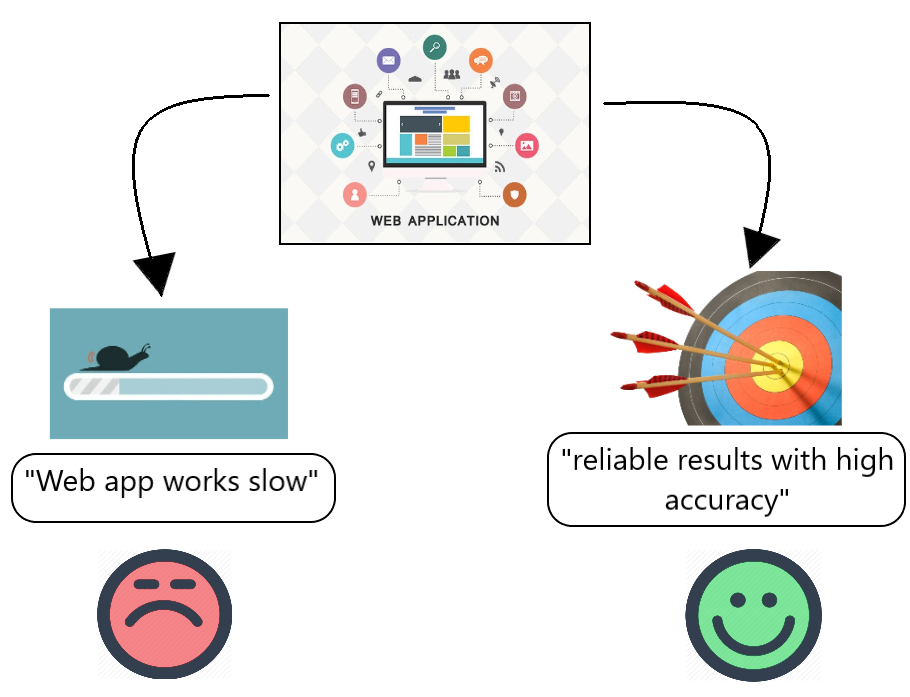
图 1 : 不同方面的不同情绪
代码实现:
以下代码实现执行方面提取过程并将其与特定情绪相关联,使其模型准备好进行训练。
Python3
# Importing the required libraries
import spacy
sp = spacy.load("en_core_web_sm")
from textblob import TextBlob
# Creating a list of positive and negative sentences.
mixed_sen = [
'This chocolate truffle cake is really tasty',
'This party is amazing!',
'My mom is the best!',
'App response is very slow!'
'The trip to India was very enjoyable'
]
# An empty list for obtaining the extracted aspects
# from sentences.
ext_aspects = []
# Performing Aspect Extraction
for sen in mixed_sen:
important = sp(sentence)
descriptive_item = ''
target = ''
for token in important:
if token.dep_ == 'nsubj' and token.pos_ == 'NOUN':
target = token.text
if token.pos_ == 'ADJ':
added_terms = ''
for mini_token in token.children:
if mini_token.pos_ != 'ADV':
continue
added_terms += mini_token.text + ' '
descriptive_item = added_terms + token.text
ext_aspects.append({'aspect': target,
'description': descriptive_item})
print("ASPECT EXTRACTION\n")
print(ext_aspects)
for aspect in ext_aspects:
aspect['sentiment'] = TextBlob(aspect['description']).sentiment
print("\n")
print("SENTIMENT ASSOCIATION\n")
print(ext_aspects)输出:
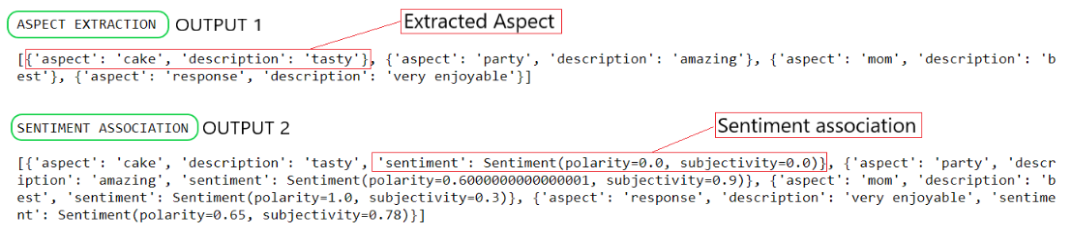
获得的输出