当输入字符串(源代码或某种语言的程序)被提供给编译器时,编译器会分几个阶段处理它,从词法分析(扫描输入并将其划分为标记)到目标代码生成。
语法分析或解析是第二阶段,即词法分析之后。它检查给定输入的句法结构,即给定输入的语法是否正确(输入的语言)。它通过构建称为解析树或语法树的数据结构来实现。解析树是通过使用语言的预定义语法和输入字符串构建的。如果在语法树的帮助下(在推导过程中)可以生成给定的输入字符串,则发现输入字符串具有正确的语法。如果不是,则语法分析器会报告错误。
语言的语法由产生式规则组成。
例子:
假设一种语言的语法的产生式规则是:
S -> cAd
A -> bc|a
And the input string is “cad”.现在解析器尝试根据给定的输入字符串从该语法构造语法树。它使用给定的生产规则并根据需要应用这些规则来生成字符串。要生成字符串“cad”,它使用给定图表中所示的规则: 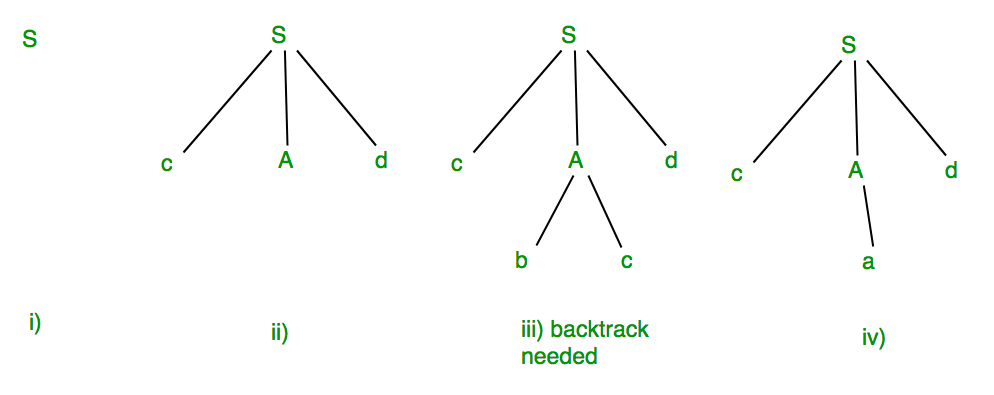
在上面的步骤 iii 中,产生式规则 A->bc 不适合应用(因为产生的字符串是“cbcd”而不是“cad”),这里解析器需要回溯,并应用下一个可用的产生式规则步骤iv中所示的A,产生字符串“cad”。
因此,给定的输入可以由给定的语法产生,因此输入在语法上是正确的。
但是需要回溯以获得正确的语法树,这确实是一个复杂的实现过程。
可以有一个更简单的方法来解决这个问题,我们将在下一篇文章“编译器设计中的 FIRST 和 FOLLOW 集的概念”中看到。
语法分析测验