BeautifulSoup是Python最常见的库之一,用于导航、搜索和从 HTML 或 XML 网页中提取数据。用于在网页上查找任何内容的最常用方法是find()和find_all() 。但是,这两者之间存在细微差别,让我们详细讨论它们。
find() 方法
find 方法用于找出具有指定名称或 id 的第一个标签,并返回一个 bs4 类型的对象。
Syntax: find_syntax=soup.find(“#Widget Name”, {“id”:”#Id name of widget in which you want to edit”}).get_text()
例子:
例如,考虑这个具有不同段落标签的简单 HTML 网页。
HTML
Geeks For Geeks
King
Prince
Queen
Princess
Python
# Find example
# Import the libraries BeautifulSoup
# and os
from bs4 import BeautifulSoup as bs
import os
# Remove the last segment of the path
base=os.path.dirname(os.path.abspath(__file__))
# Open the HTML in which you want to
# make changes
html=open(os.path.join(base, 'gfg.html'))
# Parse HTML file in Beautiful Soup
soup=bs(html, 'html.parser')
# Obtain the text from the widget after
# finding it
find_example=soup.find("p", {"id":"vinayak"}).get_text()
# Printing the text obtained received
# in previous step
print(find_example)HTML
Geeks For Geeks
King
Prince
Queen
Princess
Python
# find_all example
# Import the libraries BeautifulSoup
# and os
from bs4 import BeautifulSoup as bs
import os
# Remove the last segment of the path
base=os.path.dirname(os.path.abspath(__file__))
# Open the HTML in which you want to
# make changes
html=open(os.path.join(base, 'gfg.html'))
# Parse HTML file in Beautiful Soup
soup=bs(html, 'html.parser')
# Construct a loop to find all the
# p tags
for word in soup.find_all('p'):
# Obtain the text from the received
# tags
find_all_example=word.get_text()
# Print the text obtained received
# in previous step
print(find_all_example)为了获取文本 King,我们使用 find 方法。
Python
# Find example
# Import the libraries BeautifulSoup
# and os
from bs4 import BeautifulSoup as bs
import os
# Remove the last segment of the path
base=os.path.dirname(os.path.abspath(__file__))
# Open the HTML in which you want to
# make changes
html=open(os.path.join(base, 'gfg.html'))
# Parse HTML file in Beautiful Soup
soup=bs(html, 'html.parser')
# Obtain the text from the widget after
# finding it
find_example=soup.find("p", {"id":"vinayak"}).get_text()
# Printing the text obtained received
# in previous step
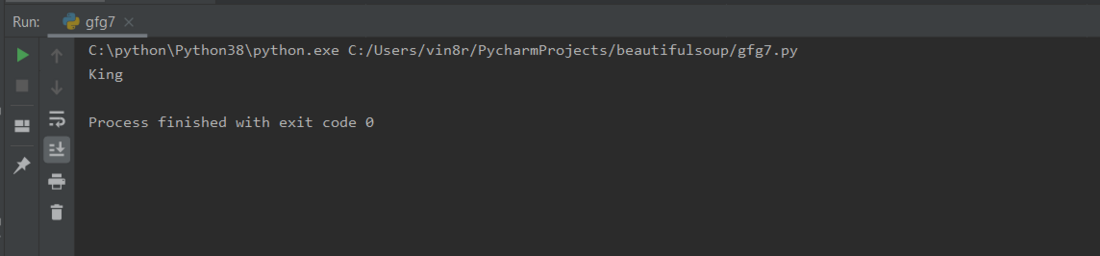
print(find_example)
输出:
find_all() 方法
find_all 方法用于查找具有指定标签名称或 id 的所有标签,并将它们作为类型 bs4 的列表返回。
Syntax:
for word in soup.find_all(‘id’):
find_all_syntax=word.get_text()
print(find_all_syntax)
例子:
例如,考虑这个具有不同段落标签的简单 HTML 网页。
HTML
Geeks For Geeks
King
Prince
Queen
Princess
为了获取所有文本,即King、Prince、Queen、Princess,我们使用find_all 方法。
Python
# find_all example
# Import the libraries BeautifulSoup
# and os
from bs4 import BeautifulSoup as bs
import os
# Remove the last segment of the path
base=os.path.dirname(os.path.abspath(__file__))
# Open the HTML in which you want to
# make changes
html=open(os.path.join(base, 'gfg.html'))
# Parse HTML file in Beautiful Soup
soup=bs(html, 'html.parser')
# Construct a loop to find all the
# p tags
for word in soup.find_all('p'):
# Obtain the text from the received
# tags
find_all_example=word.get_text()
# Print the text obtained received
# in previous step
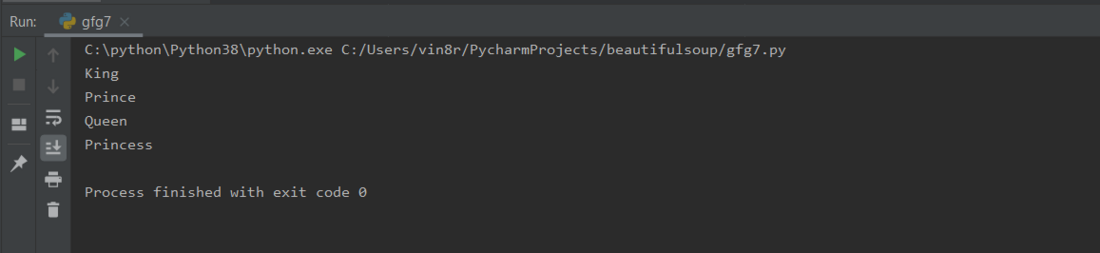
print(find_all_example)
输出:
find 和 find_all 之间的区别表
S.No. |
find |
find_all |
|---|---|---|
|
1 |
find is used for returning the result when the searched element is found on the page. |
find_all is used for returning all the matches after scanning the entire document. |
|
2 |
It is used for getting merely the first tag of the incoming HTML object for which condition is satisfied. |
It is used for getting all the incoming HTML objects for which condition is satisfied. |
|
3 |
The return type of find is |
The return type of find_all is |
|
4 |
We can print only the first search as an output. |
We can print any search, I.e., second, third, last, etc. or all the searches as an output. |
|
5 |
Prototype: find(tag, attributes, recursive, text, keywords) |
Prototype: findAll(tag, attributes, recursive, text, limit, keywords) |