Hive可用于管理 Hadoop 之上的结构化数据。数据以表格的形式存储在数据库中。在Hive,允许用户创建内部和外部表来管理和存储数据库中的数据。在本文中,我们将通过适当的实际实现来讨论Hive内部表和外部表之间的区别。内部表和外部表都有自己的用例,可以根据需要使用。例如,当我们想使用与 Hadoop 上的其他工具(如 apache pig)共享的数据时,外部表优先于内部表。
内表
通常,每当我们在Hive的数据库中创建表时,默认情况下它是一个内部表,也称为托管表。管理内部表的原因是因为Hive本身管理表内可用的元数据和数据。在Hive中创建的所有数据库内部表默认存储在我们的 HDFS 上的/user/hive/warehouse目录中。我们可以在hive.metastore.warehouse.dir属性中检查或覆盖 hive 的默认存储中心。当内部表(托管表)被删除时,它们的所有元数据和表数据都会从我们的 HDFS 中永久删除并且无法恢复。当需要使用Hive之外的可用数据并且也被我们 HDFS(Hadoop 分布式文件系统)上的其他一些 Hadoop 实用程序使用时,托管表没有任何用处,并且外部表出现了。
关于内部表要记住的要点:
- Hive将我们加载到表中的数据文件放到我们仓库内的/database-name/table-name
- 内部表支持TRUNCATE命令
- 内部表也有 ACID 支持
- 内部表也支持查询结果缓存,可以存储已经执行过的hive查询的结果,供后续查询使用
- 删除表后,元数据和表数据都将被删除
下面我们通过一个小demo来理解Hive中内部表的概念。
要执行以下操作,请确保您的配置单元正在运行。以下是在本地系统上启动配置单元的步骤。
第 1 步:启动所有 Hadoop 守护进程
start-dfs.sh # this will start namenode, datanode and secondary namenode
start-yarn.sh # this will start node manager and resource manager
jps # To check running daemons
第 2 步:从终端启动 hive
hive
现在,我们都准备好执行快速演示了。
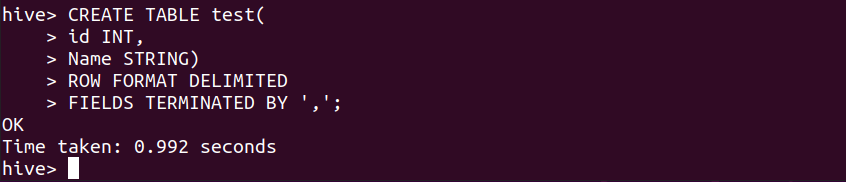
步骤1:创建名称为test的表(如果没有在任何其他数据库中提及,该表将在hive的默认数据库中创建)。
CREATE TABLE test(
id INT,
Name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';默认情况下,我们在 hive 中创建的表是内部表或托管表。通过上面的命令,内表就创建成功了。
第 2 步:使用以下命令将数据加载到此表测试。
LOAD DATA LOCAL INPATH '/home/dikshant/Desktop/data.csv' INTO TABLE test;
数据已成功加载。每当我们将任何文件数据加载到 hive 表时, Hive都会将该文件带到仓库目录中的/database-name/table-name 。您可以在下图中看到这一点(因为我在默认数据库中创建了表test ,所以数据库名称在路径中不可用)。

第三步:看数据是否加载到表中
select * from test;
第 4 步:我们可以描述表格以查看它是内部还是外部
describe extended test;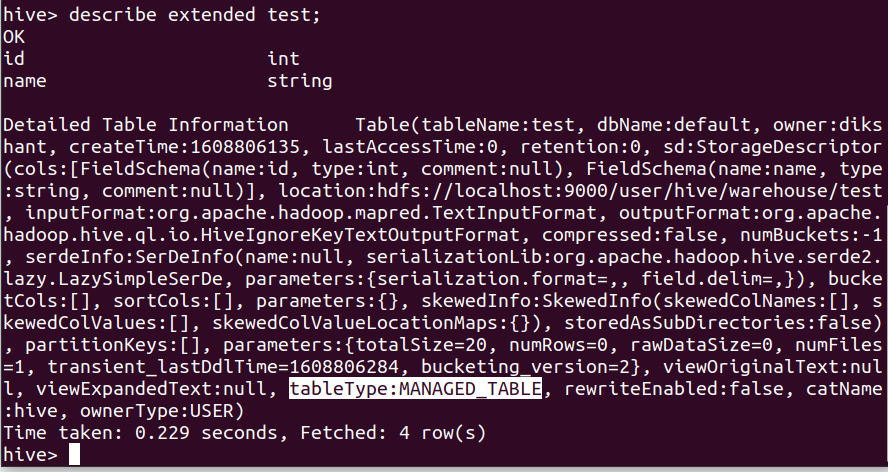
在上图中,我们可以看到表的所有元数据。表格类型显示在突出显示的部分。
第 5 步:我们可以使用 TRUNCATE 删除测试表数据,因为它在内部Hive表中受支持。
truncate table test;
现在,一旦测试表被截断,所有表数据都将从我们的仓库中删除,因为 hive 拥有内部表的所有权。由于我们已经截断了表格,因此我们可以看到如下所示的表格结构。
show tables;
第六步:删除表测试(现在元数据也将被删除)
drop table test;
外部表
外部表是管理Hive上数据的绝佳方式,因为Hive不拥有存储在外部表中的数据的所有权。万一,如果用户删除外部表,那么只会删除表的元数据并且数据是安全的。 CREATE TABLE 语句中的EXTERNAL关键字用于在Hive创建外部表。我们还必须提到我们的 HDFS 从中获取数据的位置。在 HDFS 上提供可共享数据以便Hive和其他 Hadoop 组件(如 Pig)也可以使用相同数据的所有用例都需要外部表。外部表的元数据由Hive管理,但这些表从我们 HDFS 上的其他位置获取数据。
关于外部表要记住的要点
- Hive不会将数据带到我们的仓库
- 外部表不支持 TRUNCATE 命令
- 不支持 ACID 事务属性
- 不支持查询结果缓存
- 删除外部表时,只会删除元数据
下面我们通过一个小demo来理解Hive中外部表的概念。
第一步:在HDFS中创建一个名为/TableData的目录
hdfs dfs -mkdir /TableData

第 2 步:现在将要与 hive 外部表一起使用的数据文件复制到此目录(在我的情况下为 data.csv)
hdfs dfs -put /home/dikshant/Desktop/data.csv /TableData

步骤3:现在使用EXTERNAL关键字创建一个外部表测试,如下所示(如果没有在任何其他数据库中提及,该表将在hive的默认数据库中创建)
CREATE EXTERNAL TABLE test(
id INT,
Name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION '/TableData';使用 EXTERNAL 关键字创建的表测试现在将从我们在 LOCATION 属性中提到的目录中获取数据。

第4步:让我们对我们创建的外部表test执行select查询
select * from test;
现在在上图中,我们可以清楚地看到该文件有一些数据,但我们还没有上传任何内容,所以这是可能的。这是可能的,因为 EXTERNAL 表的设计方式是从上述位置获取数据。在我们的例子中,位置是/TableData ,我们在里面有一个 data.csv 文件,所以Hive外部表会自动从这个位置获取数据。
第 5 步:由于数据在我们的仓库之外可用,而Hive不拥有它的所有权,因此无法对外部表进行TRUNCATE 。
truncate table test;
第 6 步:此外,如果我们删除这个外部表,那么只会删除表元数据,而不是存储在 HDFS 上/TableData的实际数据。
drop table test;
在下图中,我们可以看到 /TableData 是安全的并且没有被删除。

这就是Hive的Internal 和 External 表。