使用广度优先搜索在指定深度进行网络爬行
如今,网页抓取已广泛用于许多工业应用中。无论是在自然语言理解领域还是数据分析领域,从网站上抓取数据是许多此类应用程序的主要方面之一。从网站抓取数据是从一组网站中提取大量上下文文本用于不同用途。该项目还可以扩展以进一步使用,例如基于主题或主题的文本摘要、新闻网站的新闻抓取、用于训练模型的图像抓取等。
使用的库:
首先,让我们讨论一下我们将在这个项目中使用的几个库。
- requests:它是一个非常容易发送 HTTP 1.1 请求的库。使用 requests.get 方法,我们可以提取 URL 的 HTML 内容。
- urlparse:它提供了一个标准接口来将 URL 分解为不同的组件,例如网络位置、寻址方案、路径等。
- urljoin:它允许我们将基本 URL 与相对 URL 连接以形成绝对 URL。
- beautifulsoup:它是一个从 HTML 和 XML 文件中提取数据的Python库。我们可以将 HTML 页面转换为beautifulsoup对象,然后提取 HTML 标签及其内容
安装:
接下来,我们将讨论如何安装这些库。请注意,如果您的系统中安装了pip3 ,则需要使用pip3而不是 pip。
pip install requests
pip install bs4
特征:
接下来,让我们讨论该项目的各个方面和特点。
- 给定一个输入 URL 和爬虫需要爬取的深度,我们将提取所有 URL 并将它们分类为内部和外部 URL。
- 内部 URL 是那些与输入 URL 具有相同域名的 URL。外部 URL 是那些与给定输入 URL 具有不同域名的 URL。
- 我们检查提取的 URL 的有效性。如果 URL 具有有效结构,则仅考虑它。
- 深度为 0 表示仅打印输入 URL。深度为 1 意味着打印输入 URL 中的所有 URL,依此类推。
方法:
- 首先我们导入已安装的库。
- 然后,我们创建两个名为internal_links和external_links的空集,它们将分别存储内部和外部链接并确保它们不包含重复项。
- 然后,我们创建一个名为level_crawler的方法,它接受一个输入 URL 并抓取它并使用以下步骤显示所有内部和外部链接 -
- 定义一个名为url的集合来临时存储 URL。
- 使用urlparse库提取url的域名。
- 使用 HTML 解析器创建一个beautifulsoup对象。
- 从beautifulsoup对象中提取所有锚标签。
- 从锚标签中获取href标签,如果它们为空,则不要包含它们。
- 使用urljoin方法,创建绝对 URL。
- 检查 URL 的有效性。
- 如果url有效且url的域不在href标签中,也不在外部链接集中,则将其包含在外部链接集中。
- 否则,如果它不存在,则将其添加到内部链接集中并打印并将其放入临时url集中。
- 返回包含访问过的内部链接的临时url集。后面会用到这个集合。
- 如果深度为 0,我们将按原样打印url 。如果深度为1,我们调用上面定义的level_crawler方法。
- 否则,我们执行广度优先搜索 (BFS) 遍历,将 URL 页面的形成视为树结构。在第一层,我们有输入 URL。在下一级,我们在输入 URL 中拥有所有 URL,依此类推。
- 我们创建一个队列并将输入url附加到其中。然后我们弹出一个url并将其中的所有url插入到队列中。我们这样做直到特定级别的所有url都没有被解析。我们重复该过程的次数与输入深度相同。
以下是上述方法的完整程序:
Python3
# Import libraries
from urllib.request import urljoin
from bs4 import BeautifulSoup
import requests
from urllib.request import urlparse
# Set for storing urls with same domain
links_intern = set()
input_url = "https://www.geeksforgeeks.org/machine-learning/"
depth = 1
# Set for storing urls with different domain
links_extern = set()
# Method for crawling a url at next level
def level_crawler(input_url):
temp_urls = set()
current_url_domain = urlparse(input_url).netloc
# Creates beautiful soup object to extract html tags
beautiful_soup_object = BeautifulSoup(
requests.get(input_url).content, "lxml")
# Access all anchor tags from input
# url page and divide them into internal
# and external categories
for anchor in beautiful_soup_object.findAll("a"):
href = anchor.attrs.get("href")
if(href != "" or href != None):
href = urljoin(input_url, href)
href_parsed = urlparse(href)
href = href_parsed.scheme
href += "://"
href += href_parsed.netloc
href += href_parsed.path
final_parsed_href = urlparse(href)
is_valid = bool(final_parsed_href.scheme) and bool(
final_parsed_href.netloc)
if is_valid:
if current_url_domain not in href and href not in links_extern:
print("Extern - {}".format(href))
links_extern.add(href)
if current_url_domain in href and href not in links_intern:
print("Intern - {}".format(href))
links_intern.add(href)
temp_urls.add(href)
return temp_urls
if(depth == 0):
print("Intern - {}".format(input_url))
elif(depth == 1):
level_crawler(input_url)
else:
# We have used a BFS approach
# considering the structure as
# a tree. It uses a queue based
# approach to traverse
# links upto a particular depth.
queue = []
queue.append(input_url)
for j in range(depth):
for count in range(len(queue)):
url = queue.pop(0)
urls = level_crawler(url)
for i in urls:
queue.append(i)输入:
url = "https://www.geeksforgeeks.org/machine-learning/"
depth = 1
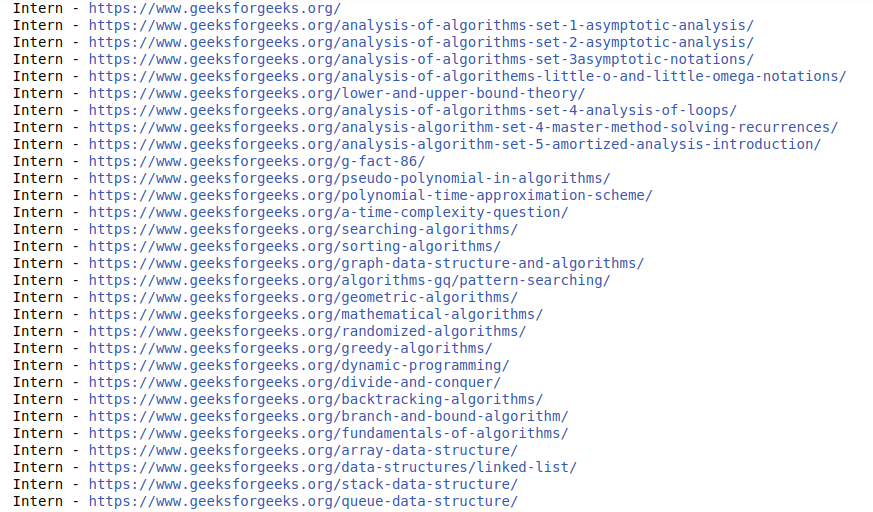
输出: