查询中的并行性允许我们通过将多个查询分解为并行工作的部分来并行执行多个查询。这可以通过无共享架构来实现。随着越来越多的资源(如处理器和磁盘)的提供,并行性也用于加快查询执行的过程。我们可以通过以下方法在查询中实现并行性:
- I/O 并行性
- 查询内并行性
- 查询间并行性
- 操作内并行性
- 操作间并行性
1. I/O 并行性:
它是一种并行形式,其中关系在多个磁盘上进行分区,目的是减少从磁盘中检索关系的时间。在内部,输入的数据被分区,然后与每个分区并行处理。处理完所有分区数据后合并结果。它也称为数据分区。散列分区的优势在于它提供了跨磁盘的数据均匀分布,并且它也最适合那些基于分区属性的点查询。需要注意的是,分区对于放置在 ‘ n ‘ 个磁盘上的整个表的顺序扫描很有用,并且扫描关系所花费的时间大约是扫描单个磁盘上表所需时间的1/n 。系统。我们在 I/O 并行性中有四种类型的分区:
- 哈希分区——
正如我们已经知道的,哈希函数是一个快速的数学函数。原始关系的每一行都根据分区属性进行散列。例如,假设有n 个磁盘disk1、disk2、disk3和disk4,通过这些磁盘对数据进行分区。现在,如果函数返回 3,则该行被放置在disc3 上。 - 范围分区——
在范围分区中,它向每个磁盘发出连续的属性值范围。例如,我们在范围分区中有3个编号为0、1和2的磁盘,并且可以将小于5的值分配给disk0,将5-40之间的值分配给disk1,将大于40的值分配给disk2 .它有一些优点,比如它涉及将包含落在磁盘上特定范围内的属性值的 shuffle。见图1: 下面给出范围分区:

- 循环分区——
在循环分区中,关系以任何顺序进行研究。第 i 个元组被发送到磁盘号 (di % n)。因此,磁盘轮流接收新的数据行。这种技术确保元组在磁盘上的均匀分布,非常适合希望为每个查询顺序读取整个关系的应用程序。 - 模式分区 –
在模式分区中,数据库中的不同表放置在不同的磁盘上。见下图2:
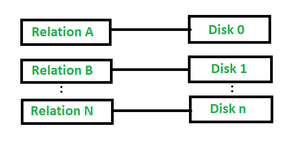
图 – 2
2. 查询内并行:
查询内并行是指使用无共享并行架构技术在不同 CPU 上的并行进程中执行单个查询。这使用两种类型的方法:
- 第一种方法——
在这种方法中,每个 CPU 都可以针对某个数据部分执行重复任务。 - 第二种方法——
在这种方法中,任务可以分为不同的扇区,每个 CPU 执行一个不同的子任务。
3. 查询间并行性:
在查询间并行性中,每个 CPU 执行多个事务。它被称为并行事务处理。 DBMS 使用事务调度来承载查询间并行性。我们还可以使用一些不同的方法,比如高效的锁管理。在这种方法中,每个查询都是顺序运行的,这会导致长查询的运行速度变慢。在这种情况下,DBMS 必须了解运行在不同进程上的不同事务持有的锁。当并行执行的事务不接受相同的数据时,共享磁盘架构上的查询间并行性能最佳。此外,它是 DBMS 中最简单的并行形式,并且增加了事务吞吐量。
4. 操作内并行性:
操作内并行性是一种并行性,在这种并行性中,我们将任务的每个单独操作(如排序、连接、投影等)的执行并行化。操作内并行度中的并行度级别非常高。这种类型的并行性在数据库系统中很自然。让我们以 SQL 查询为例:
SELECT * FROM Vehicles ORDER BY Model_Number;
在上面的查询中,关系操作是排序,由于一个关系中可以有大量的记录,因此可以在多个处理器中对关系的不同子集进行操作,从而减少了对数据进行排序所需的时间。
5. 操作间并行性:
当查询表达式中的不同操作并行执行时,称为操作间并行性。它们有两种类型——
- 流水线并行——
在流水线并行中,一个操作的输出行甚至在第一个操作在其输出中生成整个行集之前就被第二个操作消耗。此外,可以在不同的 CPU 上同时运行这两个操作,以便一个操作与另一个操作并行消耗元组,从而减少它们。它对于少量 CPU 很有用,并避免将中间结果写入磁盘。 - 独立并行——
在这种并行性中,查询表达式中不相互依赖的操作可以并行执行。这种并行性在并行度较低的情况下非常有用。