YOLO v2 – 物体检测
在速度方面,YOLO 是物体识别中最好的模型之一,能够以高达150 FPS的速率识别物体并处理帧,适用于小型网络。然而,就精度 mAP 而言,YOLO 不是最先进的模型,但在 PASCAL VOC2007 和 PASCAL VOC 2012 上训练时具有相当不错的63%平均精度(mAP)。然而,Fast R-CNN 是状态当时艺术的 mAP 为71% 。
YOLO v2 和 YOLO 9000 是由 J. Redmon 和 A. Farhadi 于 2016 年在题为YOLO 9000: Better, Faster, Stronger 的论文中提出的。在67 FPS 时,YOLOv2 的 mAP 为 76.8%,而在67 FPS 时,它在 VOC 2007 数据集上提供了78.6%的 mAP,优于Faster R-CNN和SSD 等模型。 YOLO 9000 使用 YOLO v2 架构,但能够检测 9000 多个类。然而,YOLO 9000 的 mAP 为19.7% 。
让我们看一下 YOLO v2 的架构和工作方式:
与 YOLOv1 的架构变化:
与 Fast R-CNN 等最先进的方法相比,之前的 YOLO 架构存在很多问题。它犯了很多定位错误,召回率很低。所以,本文的目标不仅是改善YOLO的这些缺点,还要保持架构的速度。在基本 YOLO 中进行了一些增量改进。让我们在下面讨论这些变化:

Darknet-19 简化版
- 批量标准化:
通过在架构中添加批量归一化,我们可以增加模型的收敛性,从而加快训练速度。这也消除了在不过度拟合的情况下应用其他类型归一化(例如 Dropout)的需要。还观察到,与基本 YOLO 相比,单独添加批量标准化会导致 mAP 增加2% 。 - 高分辨率分类器:
之前的YOLO版本在训练时使用224*224作为输入尺寸,但是在检测时,它需要一个尺寸为448*448的图像。这会导致模型调整到新的分辨率,从而导致 mAP 降低。
YOLOv2 版本在 ImageNet 数据上以更高分辨率(448 * 448)训练10 个时期。这使网络有时间调整过滤器以获得更高的分辨率。通过对 448*448 图像大小的训练,mAP 增加了4% 。 - 使用锚框作为边界框:
YOLO 使用全连接层来预测边界框,而不是像 Fast R-CNN、Faster R-CNN 那样直接从卷积网络预测坐标。
在这个版本中,我们移除了全连接层,而是添加了锚框来预测边界框。我们对架构进行了以下更改:
具有超过 1 个锚点的边界框(将提供更准确的定位)
- 我们移除了负责预测边界框的全连接层,并将其替换为锚框预测。

去除层的 YOLOv1(填充红色)
- 我们将输入的大小从448 * 448更改为416 * 416 。当我们对它进行 32 倍下采样时,这会创建一个大小为13 * 13的特征图。这背后的想法是物体很有可能位于特征图的中心。
- 去掉一层池化层得到13*13的空间网络而不是7*7
随着这些变化,模型的 mAP 略有下降(从69.5% 到 69.2 %),但召回率从81% 增加到 88% 。

每个对象提议的输出
- 我们移除了负责预测边界框的全连接层,并将其替换为锚框预测。
- 维度集群:
我们需要确定生成的锚点(先验)的数量,以便它们提供最佳结果。现在我们把它当作 K。我们的任务是为具有最大精度的图像识别 top-K 边界框。为此,我们使用 K-means 聚类算法。但是,我们不需要最小化欧几里德距离,而是最大化 IOU 作为该算法的目标。
YOLO v2 使用 K=5 来更好地权衡算法。我们可以从下图中得出结论,当我们增加 K=5 的值时,准确率不会发生显着变化。
K = 5上基于 IOU 的聚类给出了61% 的mAP。
维度集群(每个锚点的维度数)vs mAP
- 直接定位问题:
先前版本的 YOLO 对位置预测没有限制,这使得它在早期迭代中不稳定。 YOLOv2预测5个参数(T X,T Y,T W,T H,T O(对象性得分)),并应用所述Σ函数约束在0和1之间的其值下降。

这种直接位置约束使 mAP 增加了5%。 - 细粒度特征:
生成13 * 13 的YOLOv2 足以检测大型物体。然而,如果我们想检测更精细的对象,我们可以修改架构,使前一层26 * 26 * 512的输出变为13 * 13 * 2048并与原始13 * 13 * 1024输出层连接,使我们的输出层大小. - 多尺度训练:
YOLO v2 已经在320 * 320到608 * 608 的不同输入尺寸上进行了训练,步长为32 。这种架构每10 个批次随机选择图像尺寸。可以在精度和图像大小之间建立权衡。例如,图像大小为288 * 288 的YOLOv2 在90 FPS 下提供的 mAP 与 Fast R-CNN 一样多。
建筑学:
YOLO v2 在 VGG-16 和 GoogleNet 等不同架构上进行了训练。该论文还提出了一种名为 Darknet-19 的架构。选择 Darknet 架构的原因是它的处理要求低于其他架构5.58 FLOPS (相比之下,VGG-16 上的224 * 224图像大小为30.69 FLOPS ,定制 GoogleNet 中为8.52 FLOPS )。 Darknet-19的结构如下:
出于检测目的,我们替换了该架构的最后一个卷积层,而是每1024 个过滤器添加三个3 * 3卷积层,然后使用我们需要检测的输出数量进行1 * 1卷积。
对于 VOC,我们预测了 5 个具有 5 个坐标(t x 、 t y 、 t w 、 t h 、 t o (目标分数))的框,每个框有20 个类别。所以过滤器的总数是 125。
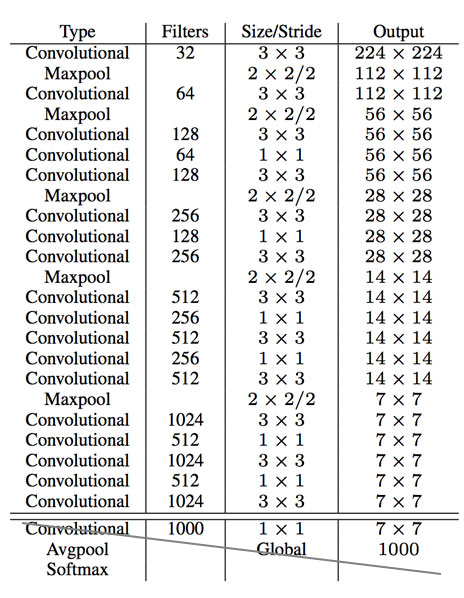
Darknet-19 架构
训练:
YOLOv2 的训练有两个目的:
- 对于分类任务,模型在 ImageNet-1000 分类任务上训练160 个时期,起始学习率为 0.1 ,权重衰减为 0.0005 ,动量为 0.9,使用 Darknet-19 架构。有一些标准的数据增强技术应用于此训练。
- 为了检测,我们在上面讨论的 Darknet-19 架构中进行了一些修改。该模型在起始学习率 10 -3 、权重衰减 0.0005和动量 0.9上训练了 160 个时期。用于在 COCO 和 VOC 上训练模型的相同策略。
结果和结论:

不同对象检测框架的结果
YOLOv2 在 PASCAL VOC 和 COCO 上提供了最先进的检测精度。它可以在不同的大小上运行,提供速度和准确性之间的权衡。在 67 FPS 时,YOLOv2 可以提供 76.8 的 mAP,而在 40 FPS 时,检测器的准确度为 78.6 mAP,优于模型状态(例如 Faster R-CNN 和 SSD),同时运行速度明显快于这些模型。

不同物体检测的速度与准确度曲线
该模型也是 YOLO9000 模型的基础,该模型能够实时检测 9000 多个类别。
参考:
- YOLO9000:更好、更快、更强