神经网络中的架构和学习过程
为了了解反向传播,我们首先必须了解神经网络的架构,然后了解 ANN 中的学习过程。那么,让我们开始了解 ANN 的各种架构:
神经网络架构:
ANN 是一个计算系统,由许多相互连接的单元组成,称为人工神经元。人工神经元之间的连接可以将信号从一个神经元传输到另一个神经元。因此,连接神经元有多种可能性,我们将根据这些神经元采用特定的解决方案。一些排列组合如下:
- 网络中可能只有两层神经元——输入层和输出层。
- 一个神经元可以有一个或多个中间“隐藏”层。
- 神经元可能与下一层的所有神经元相连,依此类推......
那么让我们开始讨论各种可能的架构:
A. 单层前馈网络:
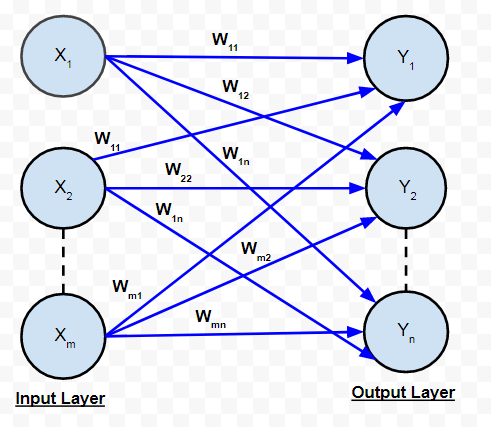
它是ANN的最简单和最基本的架构。它只包含两层——输入层和输出层。输入层由连接到每个“n”个输出神经元的“m”个输入神经元组成。连接的权重为 w 11 ,依此类推。神经元的输入层不进行任何处理——它们将 i/p 信号传递给 o/p 神经元。计算在输出层中执行。因此,虽然它有 2 层神经元,但只有一层在执行计算。这就是网络被称为单层的原因。此外,信号总是从输入层流向输出层。因此,该网络被称为 FEED FORWARD。
输入到输出神经元的净信号由下式给出:
每个输出神经元的信号输出将取决于所使用的激活函数。
B. 多层前馈网络:
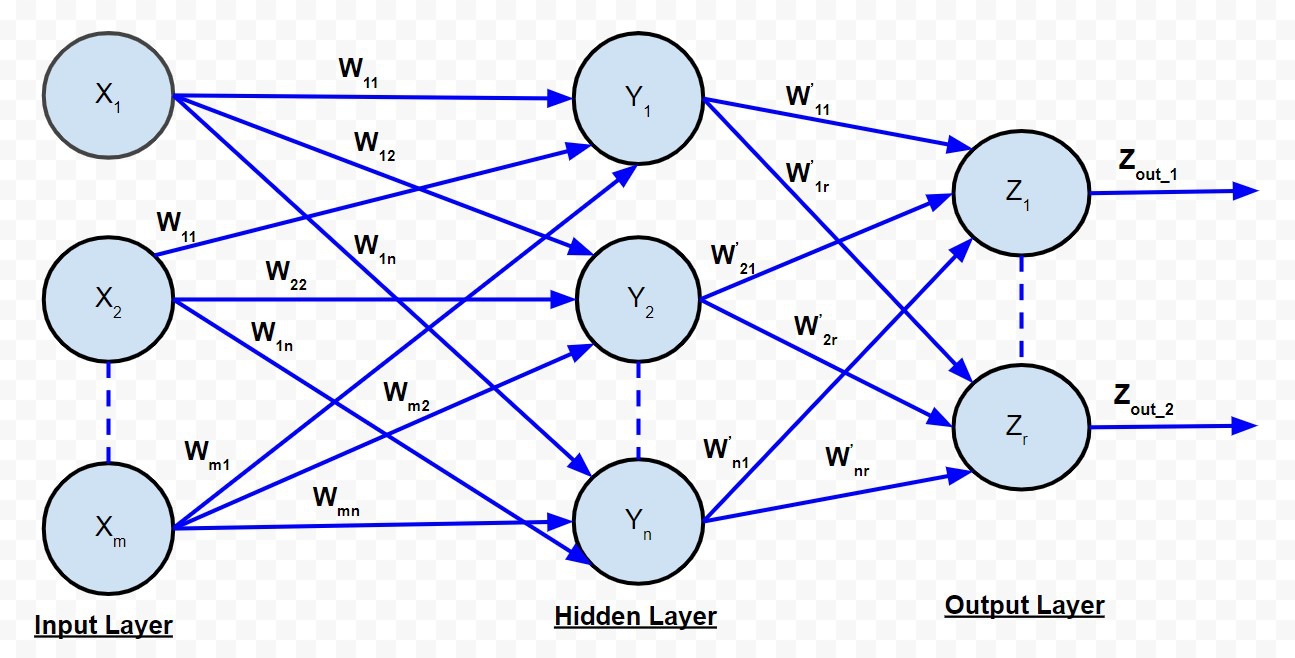
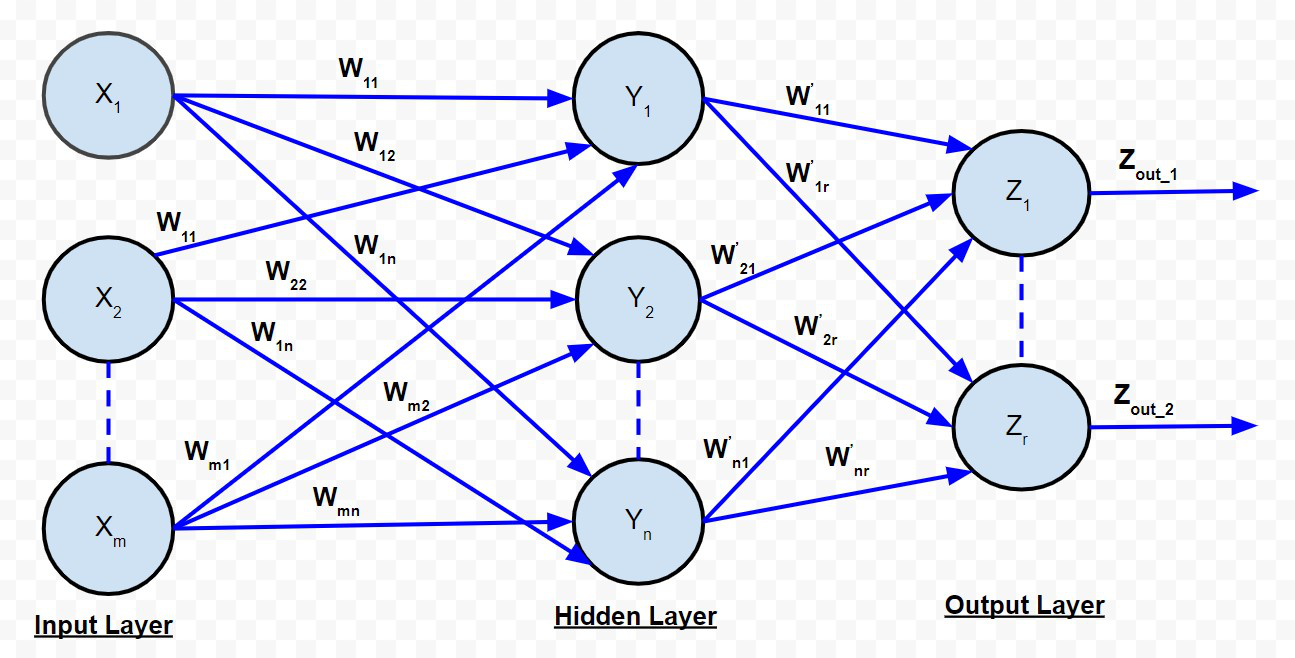
多层前馈网络
多层前馈网络与单层前馈网络非常相似,只是在输入层和输出层之间存在一个或多个中间层神经元。因此,网络被称为多层。每一层可能有不同数量的神经元。例如,上图所示的输入层有“m”个神经元,输出层有“r”个神经元,只有一个隐藏层有“n”个神经元。
对于第 k 个隐藏层神经元。输入到输出层神经元的净信号由下式给出:
C. 竞争网络:
在结构上与单层前馈网络相同。唯一的区别是输出神经元相互连接(部分或完全) 。下面是此类网络的示意图。
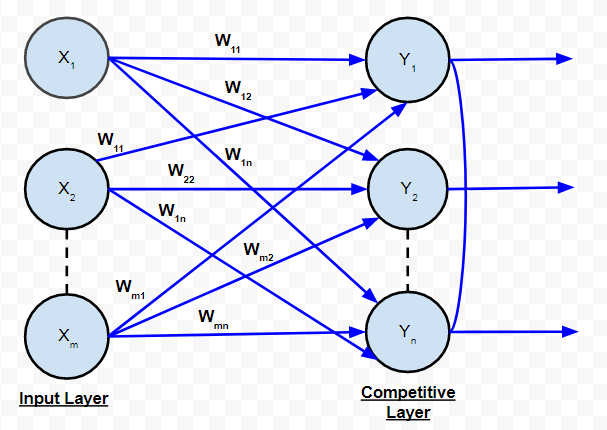
竞争网络
根据该图,很明显,很少有输出神经元相互连接。对于给定的输入,输出神经元相互竞争以表示输入。它代表了 ANN 中的一种无监督学习算法,适用于在数据集中找到集群。
D. 循环网络:
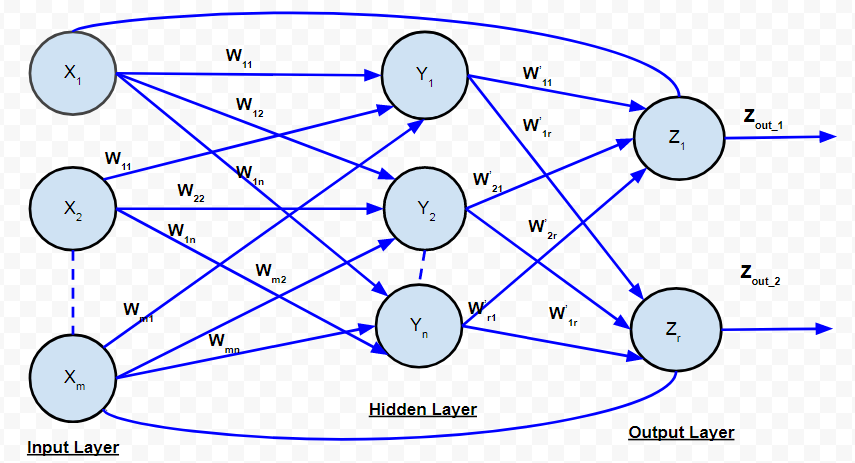
循环网络
在前馈网络中,信号总是从输入层流向输出层(仅在一个方向上)。在循环神经网络的情况下,有一个反馈回路(从输出层的神经元到输入层的神经元)。也可以有自循环。
ANN中的学习过程:
ANN中的学习过程主要取决于四个因素,它们是:
- 网络中的层数(单层或多层)
- 信号流方向(前馈或循环)
- 层中的节点数:输入层中的节点数等于输入数据集的特征数。输出节点的数量将取决于可能的结果,即在监督学习的情况下类的数量。但隐藏层的层数由用户选择。隐藏层中的节点数量越多,性能越高,但节点过多可能会导致过度拟合以及计算开销增加。
- 互连节点的权重:确定每个神经元之间的每个互连所附加的权重值,以便正确解决特定的学习问题,这本身就是一个相当困难的问题。举个例子来理解问题。以多层前馈网络为例,我们必须使用一些数据来训练一个人工神经网络模型,以便它可以对一个新的数据集进行分类,比如说 p_5(3,-2)。假设我们已经推断出 p_1=(5,2) 和 p_2 = (-1,12) 属于 C1 类,而 p_3=(3,-5) 和 p_4 = (-2,-1) 属于 C2 类。我们假设突触权重 w_0、w_1、w_2 的值分别为 -2、1/2 和 1/4。但是我们不会为每个学习问题获得这些权重值。为了解决 ANN 的学习问题,我们可以从一组突触权重值开始,并在多次迭代中不断改变这些值。停止标准可能是误分类率 < 1% 或最大迭代次数应小于 25(阈值)。可能还有另一个问题,错误分类率可能不会逐渐降低。
因此,我们可以将 ANN 中的学习过程总结为:决定隐藏层的数量、每个隐藏层中的节点数量、信号流的方向、决定连接权重。
多层馈电网络是一种常用的架构。已经观察到,即使只有一个隐藏层的神经网络也可以用来合理地逼近任何连续函数。用于训练多层前馈网络的学习方法是反向传播。
反向传播:
在上一节中,我们了解到训练 ANN 最关键的活动是分配神经元间的连接权重。 1986 年,引入了一种训练 ANN 的有效方法。在这种方法中,输出层的输出值与期望值的差值从输出层传播回前面的层。因此,实现此方法的算法称为反向传播,即将错误传播回前面的层。
反向传播算法适用于多层前馈网络。它是一种监督学习算法,它不断调整连接神经元的权重,以减少输出信号与目标输出的偏差。该算法由多次迭代组成,称为 epochs。每个时期包括两个阶段:
- 前向阶段:信号从输入层的神经元通过隐藏层流向输出层的神经元。在流程中使用互连和激活函数的权重。在输出层,产生输出信号。
- 后向相位:将信号与预期值进行比较。计算的误差从输出向后传播到前一层。反向传播的误差用于调整层之间的互连权重。
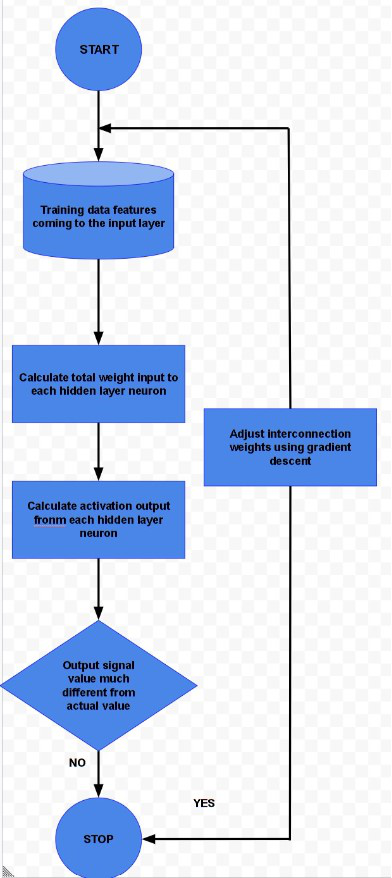
反向传播
上图描述了反向传播算法的合理简化版本。
该算法的一个主要部分是调整互连权重。这是使用称为梯度下降的技术完成的。简而言之,该算法通过每个互连权重计算激活函数的偏导数,以确定最小化成本函数所需的权重的“梯度”或变化程度。
为了详细了解反向传播算法,让我们考虑多层前馈网络。
输入到隐藏层神经元的净信号由下式给出:

如果是隐藏层的激活函数,那么
输入到输出层神经元的净信号由下式给出:
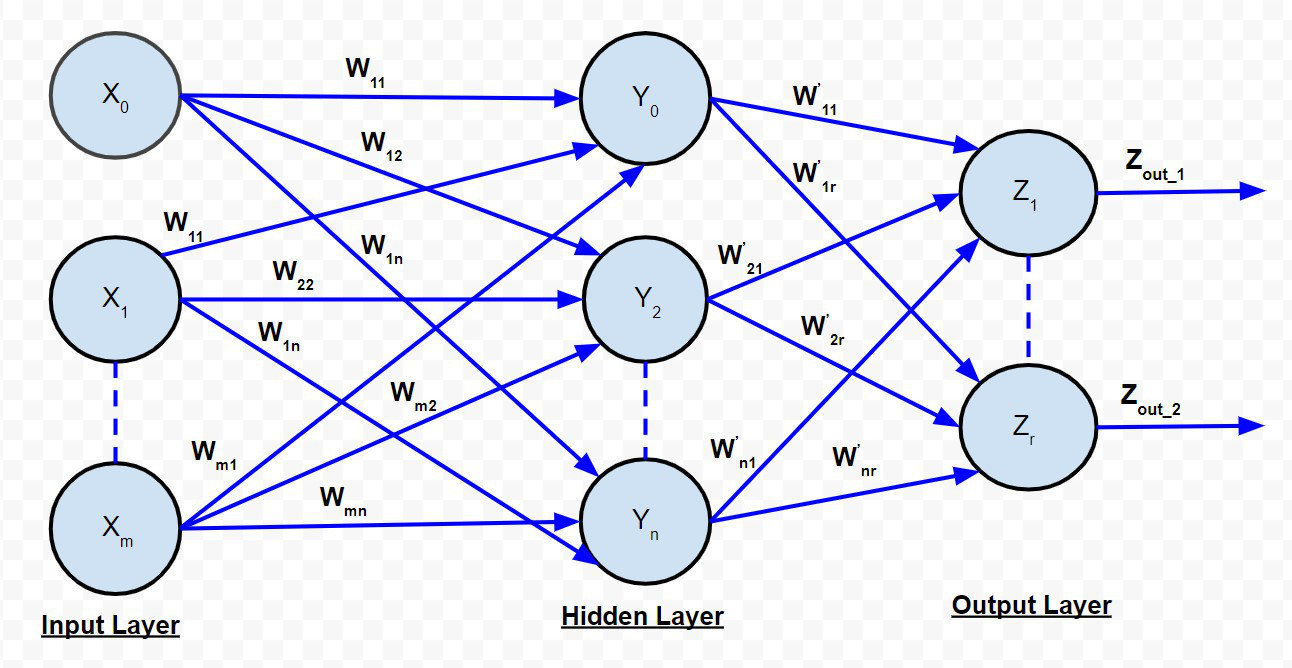
反向传播网络
请注意,信号 和
和 假定为 1。如果
假定为 1。如果 是隐藏层的激活函数,那么
是隐藏层的激活函数,那么
如果 是第 k 个输出神经元的目标,则定义为输出层的平方误差的成本函数由下式给出:
根据下降算法,成本函数E 的偏导数必须对互连权重进行。在数学上它可以表示为:

{上面的表达式是隐藏层中第 j 个神经元和输出层中第 k 个神经元之间的互连权重。}这个表达式可以简化为

在哪里, 要么
如果我们假设 作为重量所需的重量调整的一个组成部分
作为重量所需的重量调整的一个组成部分对应于第 k 个输出神经元,则 :
在此基础上,需要更新权重和偏差如下:
- 对于权重:
- 因此,
- 对于偏见:

- 因此,

在上述表达式中,alpha 是神经网络的学习率。 学习率是一个用户参数,它减少或增加调整神经网络的互连权重的速度。如果学习率太高,作为梯度下降过程的一部分进行的调整可能会使数据集发散而不是收敛。另一方面,如果学习率太低,优化可能会消耗更多时间,因为向最小值迈进了小步。
{以上所有计算都是针对隐藏层神经元和输出层神经元之间的互连权重}
像上面的表达式一样,我们可以推导出“输入层和隐藏层之间的互连权重”的表达式:
- 对于权重:
- 因此,

- 对于偏见:
- 因此,
因此,通过这种方式,我们可以使用反向传播算法来解决各种人工神经网络。