Python - 高斯拟合
什么是正态分布或高斯分布?
当我们绘制一个数据集(例如直方图)时,该图表的形状就是我们所说的分布。最常见的连续值形状是钟形曲线,也称为高斯分布或正态分布。
它以德国数学家卡尔·弗里德里希·高斯的名字命名。遵循高斯分布的一些常见示例数据集包括体温、人的身高、汽车里程、智商分数。
让我们尝试生成理想的正态分布并使用Python绘制它。
如何在Python绘制高斯分布
我们有 Numpy、scipy 和 matplotlib 等库来帮助我们绘制理想的正态曲线。
Python3
import numpy as np
import scipy as sp
from scipy import stats
import matplotlib.pyplot as plt
## generate the data and plot it for an ideal normal curve
## x-axis for the plot
x_data = np.arange(-5, 5, 0.001)
## y-axis as the gaussian
y_data = stats.norm.pdf(x_data, 0, 1)
## plot data
plt.plot(x_data, y_data)Python3
#Define the Gaussian function
def gauss(x, H, A, x0, sigma):
return H + A * np.exp(-(x - x0) ** 2 / (2 * sigma ** 2))Python3
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
xdata = [ -10.0, -9.0, -8.0, -7.0, -6.0, -5.0, -4.0, -3.0, -2.0, -1.0, 0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]
ydata = [1.2, 4.2, 6.7, 8.3, 10.6, 11.7, 13.5, 14.5, 15.7, 16.1, 16.6, 16.0, 15.4, 14.4, 14.2, 12.7, 10.3, 8.6, 6.1, 3.9, 2.1]
# Recast xdata and ydata into numpy arrays so we can use their handy features
xdata = np.asarray(xdata)
ydata = np.asarray(ydata)
plt.plot(xdata, ydata, 'o')
# Define the Gaussian function
def Gauss(x, A, B):
y = A*np.exp(-1*B*x**2)
return y
parameters, covariance = curve_fit(Gauss, xdata, ydata)
fit_A = parameters[0]
fit_B = parameters[1]
fit_y = Gauss(xdata, fit_A, fit_B)
plt.plot(xdata, ydata, 'o', label='data')
plt.plot(xdata, fit_y, '-', label='fit')
plt.legend()Python3
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as mpl
# Let's create a function to model and create data
def func(x, a, x0, sigma):
return a*np.exp(-(x-x0)**2/(2*sigma**2))
# Generating clean data
x = np.linspace(0, 10, 100)
y = func(x, 1, 5, 2)
# Adding noise to the data
yn = y + 0.2 * np.random.normal(size=len(x))
# Plot out the current state of the data and model
fig = mpl.figure()
ax = fig.add_subplot(111)
ax.plot(x, y, c='k', label='Function')
ax.scatter(x, yn)
# Executing curve_fit on noisy data
popt, pcov = curve_fit(func, x, yn)
#popt returns the best fit values for parameters of the given model (func)
print (popt)
ym = func(x, popt[0], popt[1], popt[2])
ax.plot(x, ym, c='r', label='Best fit')
ax.legend()
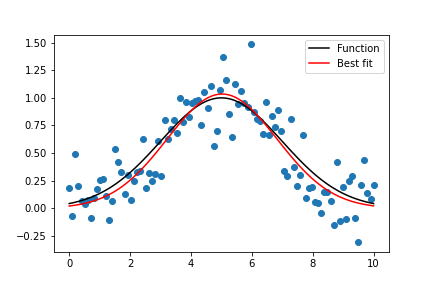
fig.savefig('model_fit.png')输出:
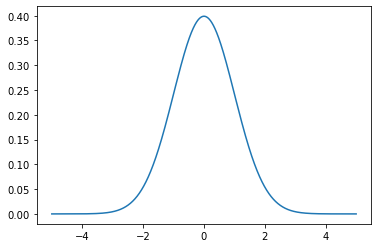
x 轴上的点是观测值,y 轴是每个观测值的可能性。
我们使用np.arange()在 (-5, 5) 范围内生成规则间隔的观察结果。然后我们通过 norm.pdf()函数运行它,平均值为 0.0,标准差为 1,返回该观察的可能性。 0 附近的观察是最常见的,-5.0 和 5.0 附近的观察很少。 pdf()函数的技术术语是概率密度函数。
高斯函数:
首先,让我们将数据拟合到高斯函数。我们的目标是找到最适合我们数据的 A 和 B 的值。首先,我们需要为高斯函数方程编写一个Python函数。该函数应该接受自变量(x 值)和所有构成它的参数。
蟒蛇3
#Define the Gaussian function
def gauss(x, H, A, x0, sigma):
return H + A * np.exp(-(x - x0) ** 2 / (2 * sigma ** 2))
我们将使用函数curve_fit从Python模块scipy.optimize,以适应我们的数据。它使用非线性最小二乘法将数据拟合为函数形式。您可以使用 Jupyter notebook 或scipy 在线文档中的帮助函数了解有关curve_fit的更多信息。
curve_fit函数具有三个必需的输入:您要拟合的函数、x 数据和您拟合的 y 数据。有两个输出。第一个是参数最优值的数组。第二个是参数的估计协方差矩阵,您可以从中计算参数的标准误差。
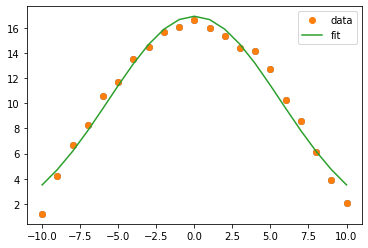
示例 1:
蟒蛇3
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
xdata = [ -10.0, -9.0, -8.0, -7.0, -6.0, -5.0, -4.0, -3.0, -2.0, -1.0, 0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]
ydata = [1.2, 4.2, 6.7, 8.3, 10.6, 11.7, 13.5, 14.5, 15.7, 16.1, 16.6, 16.0, 15.4, 14.4, 14.2, 12.7, 10.3, 8.6, 6.1, 3.9, 2.1]
# Recast xdata and ydata into numpy arrays so we can use their handy features
xdata = np.asarray(xdata)
ydata = np.asarray(ydata)
plt.plot(xdata, ydata, 'o')
# Define the Gaussian function
def Gauss(x, A, B):
y = A*np.exp(-1*B*x**2)
return y
parameters, covariance = curve_fit(Gauss, xdata, ydata)
fit_A = parameters[0]
fit_B = parameters[1]
fit_y = Gauss(xdata, fit_A, fit_B)
plt.plot(xdata, ydata, 'o', label='data')
plt.plot(xdata, fit_y, '-', label='fit')
plt.legend()
示例 2:
蟒蛇3
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as mpl
# Let's create a function to model and create data
def func(x, a, x0, sigma):
return a*np.exp(-(x-x0)**2/(2*sigma**2))
# Generating clean data
x = np.linspace(0, 10, 100)
y = func(x, 1, 5, 2)
# Adding noise to the data
yn = y + 0.2 * np.random.normal(size=len(x))
# Plot out the current state of the data and model
fig = mpl.figure()
ax = fig.add_subplot(111)
ax.plot(x, y, c='k', label='Function')
ax.scatter(x, yn)
# Executing curve_fit on noisy data
popt, pcov = curve_fit(func, x, yn)
#popt returns the best fit values for parameters of the given model (func)
print (popt)
ym = func(x, popt[0], popt[1], popt[2])
ax.plot(x, ym, c='r', label='Best fit')
ax.legend()
fig.savefig('model_fit.png')
输出: