数据挖掘——时间序列、符号和生物序列数据
数据挖掘是指从大量数据中提取或挖掘知识。换句话说,数据挖掘是发现大量复杂数据以发现有用模式的科学、艺术和技术。理论家和实践者一直在寻求改进的技术,以使该过程更高效、更具成本效益和更准确。
本文讨论序列数据。数据评价达到了最大程度,未来仍可细读。为了概括对数据的评估,我们将它们分类为序列数据、图形和网络挖掘,另一种数据。
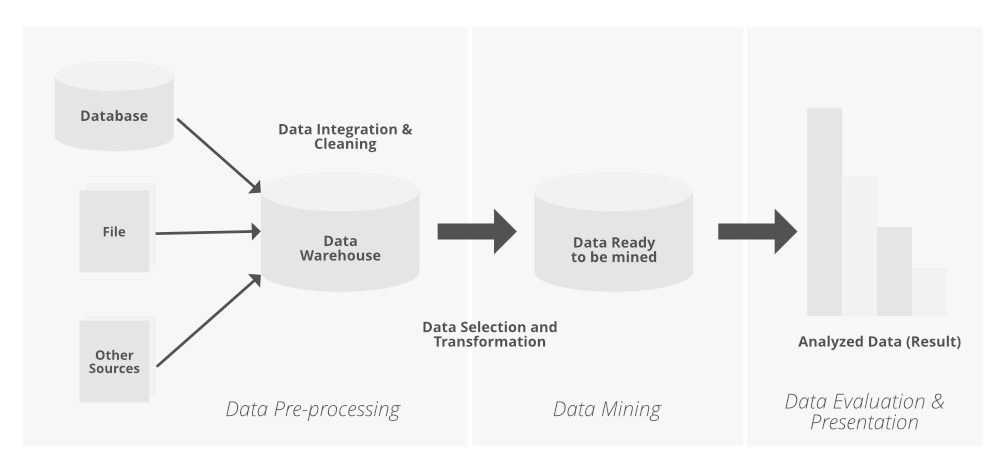
序列是事件的有序列表。序列数据根据特征分类为:
- 时间序列数据(关于时间的数据)
- 符号数据(时间间隔内有圈数的数据)
- 生物数据(与 DNA 和蛋白质相关的数据)
时间序列数据:
在这种类型的序列中,数据是定期记录的数字数据类型。它们是由股票市场分析、医学观察等经济过程产生的。它们对于研究自然现象很有用。
如今,这些时间序列用于分段数据近似以进行进一步分析。在这个时间序列数据中,我们找到了一个与我们搜索的查询匹配的子序列。
- 时间序列预测:预测是一种基于过去和现在的数据进行预测以了解未来会发生什么的方法。趋势分析是一种预测时间序列的方法。它是一种在时间序列中生成历史模式的函数,用于短期和长期预测。我们可以获得时间序列中的各种模式,例如循环运动、趋势运动、季节性运动,正如我们所看到的它们与时间或季节有关的情况。 ARIMA、SARIMA、长记忆时间序列建模是此类分析的一些流行方法
符号数据:
这种类型的有序元素或事件集在有或没有具体时间概念的情况下记录。一些符号序列,例如客户购物序列、网络点击流是符号数据的示例。序列模式挖掘主要用于符号序列
基于约束的模式匹配是与用户定义数据交互的最佳方式之一。 Apriori 是用于此类分析的算法 下面是一个符号日期示例,我们看到客户 c1 和 c2 在不同的时间间隔购买产品Tid Time Cid Event(purchase products) t1 11:45:30 c1 wheat, rice, fruit t2 11:36:50 c2 rice, fruit t1 12:00:01 c1 juice, rice t2 01:00:34 c2 sugar, milk
生物学数据:
它们由 DNA 和蛋白质序列组成。它们很长很复杂,但有一些隐藏的含义。这些类型的数据用于核苷酸或氨基酸的序列。这些分析用于比对、索引、分析生物序列,并在生物信息学和现代生物学中发挥着至关重要的作用。替换树用于查找氨基酸的概率和交叉的概率。 BLAST-Basic Local Alignment Search Tool 是最有效的生物序列分析工具。