Pandas 中的数据透视表
在本文中,我们将看到 Pandas 中的数据透视表。让我们讨论一些概念:
Pandas : Pandas 是一个建立在 NumPy 库之上的开源库。它是一个Python包,提供用于处理数值数据和时间序列的各种数据结构和操作。它主要用于更容易地导入和分析数据。 Pandas 速度快,为用户提供高性能和生产力。
数据透视表:数据透视表是汇总更广泛表(例如来自数据库、电子表格或商业智能程序)的数据的统计表。此摘要可能包括总和、平均值或其他统计数据,数据透视表以有意义的方式将它们组合在一起。
需要的步骤
- 导入库(熊猫)
- 导入/加载/创建数据。
- 使用具有不同变体的 Pandas.pivot_table() 方法。
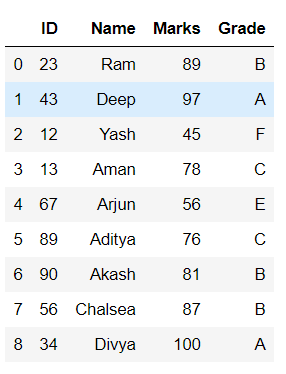
在这里,我们将在如下所示的数据帧上讨论数据透视表的一些变体:
Python3
# import packages
import pandas as pd
# create data
df = pd.DataFrame({'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep', 2: 'Yash',
3: 'Aman', 4: 'Arjun', 5: 'Aditya',
6: 'Akash', 7: 'Chalsea',
8: 'Divya'},
'Marks': {0: 89, 1: 97, 2: 45,
3: 78, 4: 56, 5: 76,
6: 81, 7: 87, 8: 100},
'Grade': {0: 'B', 1: 'A', 2: 'F',
3: 'C', 4: 'E', 5: 'C',
6: 'B', 7: 'B', 8: 'A'}})
# view data
display(df)Python3
# import packages
import pandas as pd
# create data
df = pd.DataFrame({'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep', 2: 'Yash',
3: 'Aman', 4: 'Arjun', 5: 'Aditya',
6: 'Akash', 7: 'Chalsea',
8: 'Divya'},
'Marks': {0: 89, 1: 97, 2: 45,
3: 78, 4: 56, 5: 76,
6: 81, 7: 87, 8: 100},
'Grade': {0: 'B', 1: 'A', 2: 'F',
3: 'C', 4: 'E', 5: 'C',
6: 'B', 7: 'B', 8: 'A'}})
# simple use pivot_table() method
print(pd.pivot_table(df, index = ["ID"]))Python3
# import packages
import pandas as pd
# create data
df = pd.DataFrame({'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep', 2: 'Yash',
3: 'Aman', 4: 'Arjun', 5: 'Aditya',
6: 'Akash', 7: 'Chalsea',
8: 'Divya'},
'Marks': {0: 89, 1: 97, 2: 45,
3: 78, 4: 56, 5: 76,
6: 81, 7: 87, 8: 100},
'Grade': {0: 'B', 1: 'A', 2: 'F',
3: 'C', 4: 'E', 5: 'C',
6: 'B', 7: 'B', 8: 'A'}})
# multiple columns with
# pivot_table() method
display(pd.pivot_table(df,
index = ["ID", "Name"]))Python3
# import packages
import pandas as pd
import numpy as np
# create data
df = pd.DataFrame({'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep',
2: 'Yash', 3: 'Aman',
4: 'Arjun', 5: 'Aditya',
6: 'Akash',7: 'Chalsea',
8: 'Divya'},
'Marks': {0: 89, 1: 97, 2: 45,
3: 78, 4: 56, 5: 76,
6: 81, 7: 87, 8: 100},
'Grade': {0: 'B', 1: 'A', 2: 'F', 3: 'C',
4: 'E', 5: 'C', 6: 'B', 7: 'B',
8: 'A'}})
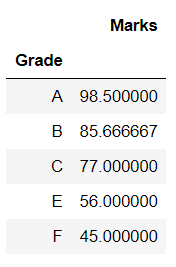
# Pivot Table with mean
# aggregate function on marks
display(pd.pivot_table(df,
index = ["Grade"],
values = ["Marks"],
aggfunc = np.mean))输出:
示例 1:pivot_table() 方法的简单使用。
蟒蛇3
# import packages
import pandas as pd
# create data
df = pd.DataFrame({'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep', 2: 'Yash',
3: 'Aman', 4: 'Arjun', 5: 'Aditya',
6: 'Akash', 7: 'Chalsea',
8: 'Divya'},
'Marks': {0: 89, 1: 97, 2: 45,
3: 78, 4: 56, 5: 76,
6: 81, 7: 87, 8: 100},
'Grade': {0: 'B', 1: 'A', 2: 'F',
3: 'C', 4: 'E', 5: 'C',
6: 'B', 7: 'B', 8: 'A'}})
# simple use pivot_table() method
print(pd.pivot_table(df, index = ["ID"]))
输出 :

示例 2:具有多列索引的数据透视表。
蟒蛇3
# import packages
import pandas as pd
# create data
df = pd.DataFrame({'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep', 2: 'Yash',
3: 'Aman', 4: 'Arjun', 5: 'Aditya',
6: 'Akash', 7: 'Chalsea',
8: 'Divya'},
'Marks': {0: 89, 1: 97, 2: 45,
3: 78, 4: 56, 5: 76,
6: 81, 7: 87, 8: 100},
'Grade': {0: 'B', 1: 'A', 2: 'F',
3: 'C', 4: 'E', 5: 'C',
6: 'B', 7: 'B', 8: 'A'}})
# multiple columns with
# pivot_table() method
display(pd.pivot_table(df,
index = ["ID", "Name"]))
输出 :

示例 3:具有聚合函数的数据透视表。
蟒蛇3
# import packages
import pandas as pd
import numpy as np
# create data
df = pd.DataFrame({'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep',
2: 'Yash', 3: 'Aman',
4: 'Arjun', 5: 'Aditya',
6: 'Akash',7: 'Chalsea',
8: 'Divya'},
'Marks': {0: 89, 1: 97, 2: 45,
3: 78, 4: 56, 5: 76,
6: 81, 7: 87, 8: 100},
'Grade': {0: 'B', 1: 'A', 2: 'F', 3: 'C',
4: 'E', 5: 'C', 6: 'B', 7: 'B',
8: 'A'}})
# Pivot Table with mean
# aggregate function on marks
display(pd.pivot_table(df,
index = ["Grade"],
values = ["Marks"],
aggfunc = np.mean))
输出 :