Bootstrap 绘图简介
在进入 Bootstrap plot 之前,让我们首先了解 Bootstrapping(或 Bootstrap 采样)是什么。
Bootstrap Sampling:这是一种我们从数据集中重复抽取样本数据并进行替换以估计总体参数的方法。它用于确定总体的各种参数。
Bootstrap 图:它是一种图形方法,用于测量总体的任何所需统计特征的不确定性。它是置信区间的替代。 (也是一种用于计算统计量的数学方法)。
结构
- x 轴:子样本数。
- y 轴:给定子样本所需统计量的计算值。
需要一个引导图:
通常,我们可以使用置信区间以数学方式计算总体统计量的不确定性。然而,在许多情况下,推导出的不确定性公式在数学上是难以处理的。在这种情况下,我们使用 Bootstrap 图。
假设我们在一个公园里有 5000 人,我们需要找到整个人口的平均体重。测量每个人的体重然后取平均值是不可行的。这就是引导抽样的用武之地。
我们所做的是,我们从人群中随机抽取 5 个人为一组,并找出其均值。我们做同样的过程说 8-10 次。这样,我们可以更有效地很好地估计总体的平均权重。
直觉:
让我们考虑一个示例并了解 Bootstrap 图如何更轻松地从大量人口中获取关键信息。假设我们有 3000 个随机生成的统一数的样本数据。我们取出 30 个数字的子样本并找到它的平均值。我们对另一个随机子样本再次执行此操作,依此类推。
我们绘制了上述获得的信息的引导图,只需查看它,我们就可以轻松地对所有 3000 个数字的均值进行很好的估计。可以从引导图中获得其他各种有用的信息,例如:
- 哪个子样本的方差最低,或
- 哪个子样本创建最窄的置信区间等。
执行:
Python
import pandas as pd
import numpy as np
s = pd.Series(np.random.uniform(size=500))
pd.plotting.bootstrap_plot(s)输出
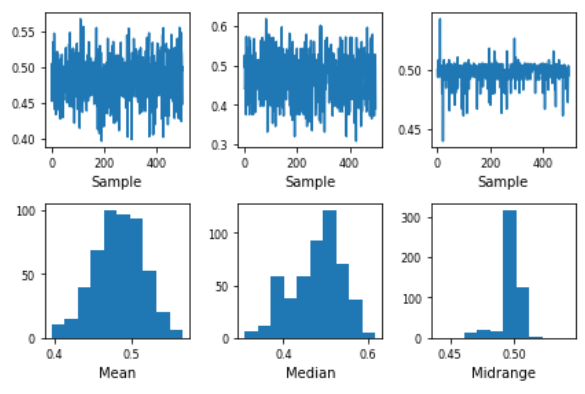
局限性
- 自举图给出了对总体所需信息的估计,而不是精确值。
- 它高度依赖于给定的数据集。当很多子集有重复样本时,它无法给出好的结果。
- 当我们获取高度依赖于尾值的信息时,引导图变得无效。 【如图1所示】