在 Pandas DataFrame 上创建视图 |套装 – 2
先决条件:在 Pandas DataFrame 上创建视图 |套装 – 1
很多时候,在进行数据分析时,我们处理的大型数据集具有很多属性。所有属性不一定同等重要。因此,我们只想使用数据框中的一组列。为此,让我们看看我们如何在 Dataframe 上创建视图并仅选择我们需要的那些列并保留其余列。
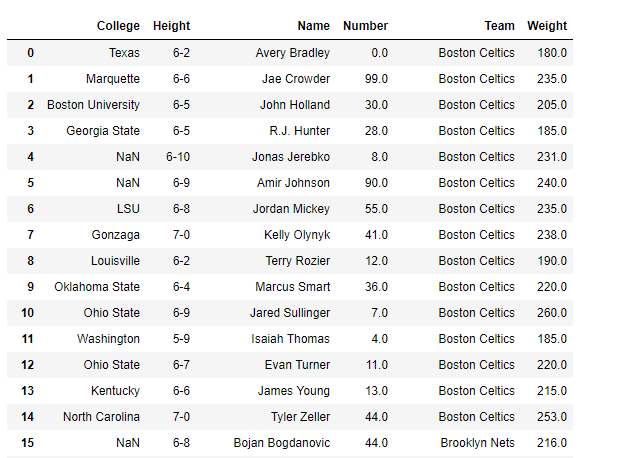
给定一个包含nba数据的 Dataframe,在其上创建视图,以便只包含所需的列。
注意:有关代码中使用的 CSV 文件的链接,请单击此处
解决方案#1:在将 csv 文件中的数据读入Python时,我们可以选择所有要读入 DataFrame 的列。
# importing pandas as pd
import pandas as pd
# list of columns that we want to
# read into the DataFrame
use_cols =['Name', 'Number', 'College']
# Reading the csv file
df = pd.read_csv('nba.csv', usecols = lambda x : x in use_cols,
index_col = False)
# Print the dataframe
print(df)
输出 : 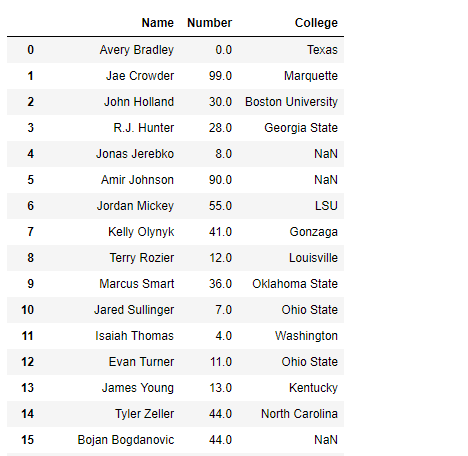
解决方案#2:在将 csv 文件中的数据读入Python时,我们可以列出所有不想读入 DataFrame 的列。这就像删除那些列。
# importing pandas as pd
import pandas as pd
# list of columns that we do not want
# to read into the DataFrame
skip_cols =['Name', 'Number', 'College']
# Reading the csv file
df = pd.read_csv('nba.csv', usecols = lambda x : x not in skip_cols,
index_col = False)
# Print the dataframe
print(df)
输出 : 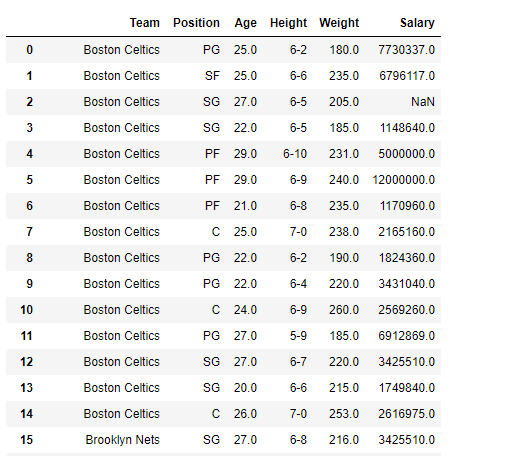
解决方案#3:我们可以使用difference()方法删除我们不需要的列。
# importing pandas as pd
import pandas as pd
# Reading the csv file
df = pd.read_csv("nba.csv")
# Print the dataframe
print(df)
输出 : 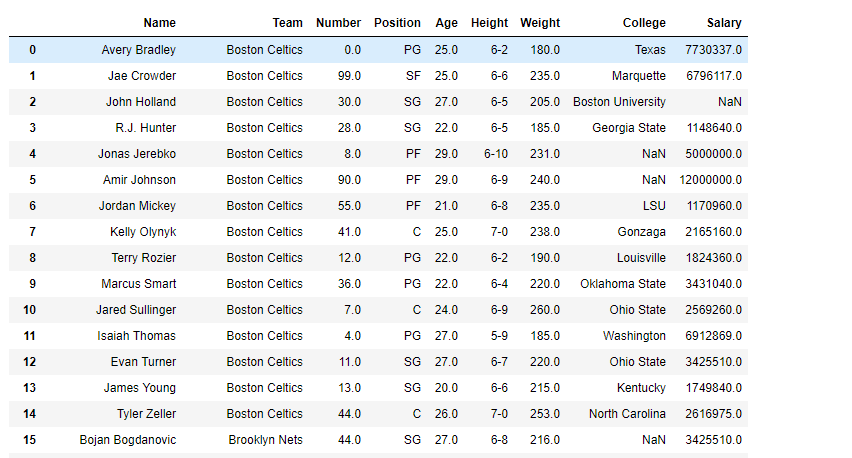
现在我们将使用difference()方法删除那些我们不需要的列。
# Drop the listed columns
df_view = df[df.columns.difference(['Position', 'Age', 'Salary'])]
# Print the new DataFrame
print(df_view)
输出 :