使用数据模式模块识别数据帧中的模式
先决条件: Pandas 模块、Pandas 数据框
Pandas是一个建立在NumPy库之上的开源库。它是一个Python包,提供用于处理数值数据和时间序列的各种数据结构和操作。它主要用于更容易地导入和分析数据。 Pandas速度快,并且为用户提供高性能和生产力。
Data Frame是二维大小可变的、潜在的异构表格数据结构,在Pandas中带有标记的轴(行和列)。数据框是一种二维数据结构,即数据在行和列中以表格方式对齐。 Pandas数据框由三个主要组件组成,数据、行和列。
数据模式模块,为了在数据框中找到简单的数据模式,我们将使用Python中的data-patterns模块,该模块用于生成和评估结构化数据集中的模式并导出到 Excel 和 JSON 并将生成的模式转换为熊猫代码。
安装:
pip install data-patterns循序渐进的方法:
导入所需的模块。
分配数据框。
使用数据框作为构造函数参数创建模式混合器对象。
调用模式混合器对象的find()方法来识别数据框中的各种模式。
执行:
以下是基于上述方法的一些程序:
Python3
# importing the data_patterns module
import data_patterns
# importing the pandas module
import pandas as pd
# creating a pandas dataframe
df = pd.DataFrame(columns=['Name', 'Grade', 'value1',
'Value2', 'Value3', 'Value4', 'value5'],
data=[['Alpha', 'A', 1000, 800, 0, 200, 200],
['Beta', 'B', 4000, 0, 3200, 800, 800],
['Gama', 'A', 800, 0, 700, 100, 100],
['Theta', 'B', 2500, 1800, 0, 700, 700],
['Ceta', 'C', 2100, 0, 2200, 200, 200],
['Saiyan', 'C', 9000, 8800, 0, 200, 200],
['SSai', 'A', 9000, 0, 8800, 200, 200],
['SSay', 'A', 9000, 8800, 0, 200, 200],
['Geeks', 'A', 9000, 0, 8800, 200, 200],
['SsBlue', 'B', 9000, 0, 8800, 200, 19]])
# setting datag=frame index
df.set_index('Name', inplace=True)
# creating a pattern mixer object
miner = data_patterns.PatternMiner(df)
# finding the pattern in the dataframe
# name is optional
# other patterns which can be used ‘>’, ‘<’, ‘<=’, ‘>=’, ‘!=’, ‘sum’
df_patterns = miner.find({'name': 'equal values',
'pattern': '=',
'parameters': {"min_confidence": 0.5,
"min_support": 2,
"decimal": 8}})
# printing the dataframe pattern
print(df_patterns)Python3
# importing the data_patterns module
import data_patterns
# importing the pandas module
import pandas as pd
# creating a pandas dataframe
df = pd.DataFrame(columns=['Name', 'Grade', 'value1',
'Value2', 'Value3', 'Value4', 'value5'],
data=[['Alpha', 'A', 1000, 800, 0, 200, 200],
['Beta', 'B', 4000, 0, 3200, 800, 800],
['Gama', 'A', 800, 0, 700, 100, 100],
['Theta', 'B', 2500, 1800, 0, 700, 700],
['Ceta', 'C', 2100, 0, 2200, 200, 200],
['Saiyan', 'C', 9000, 8800, 0, 200, 200],
['SSai', 'A', 9000, 0, 8800, 200, 200],
['SSay', 'A', 9000, 8800, 0, 200, 200],
['Geeks', 'A', 9000, 0, 8800, 200, 200],
['SsBlue', 'B', 9000, 0, 8800, 200, 19]])
# setting datag=frame index
df.set_index('Name', inplace=True)
# creating a pattern mixer object
miner = data_patterns.PatternMiner(df)
# finding the pattern in the dataframe
# name is optional
# other patterns which can be used ‘>’, ‘<’, ‘<=’, ‘>=’, ‘!=’, ‘sum’
df_patterns = miner.find({'name': 'equal values',
'pattern': '=',
'parameters': {"min_confidence": 0.5,
"min_support": 2,
"decimal": 8}})
# getting the analyzed dataframe
df_results = miner.analyze(df)
# printing the analyzed results
print(df_results)输出:

数据项value4和value5具有相同的模式,支持9和1异常。
此外,这些数据可以在analyze()方法的帮助下以适当的格式进行分析,以下是改进后的程序:
蟒蛇3
# importing the data_patterns module
import data_patterns
# importing the pandas module
import pandas as pd
# creating a pandas dataframe
df = pd.DataFrame(columns=['Name', 'Grade', 'value1',
'Value2', 'Value3', 'Value4', 'value5'],
data=[['Alpha', 'A', 1000, 800, 0, 200, 200],
['Beta', 'B', 4000, 0, 3200, 800, 800],
['Gama', 'A', 800, 0, 700, 100, 100],
['Theta', 'B', 2500, 1800, 0, 700, 700],
['Ceta', 'C', 2100, 0, 2200, 200, 200],
['Saiyan', 'C', 9000, 8800, 0, 200, 200],
['SSai', 'A', 9000, 0, 8800, 200, 200],
['SSay', 'A', 9000, 8800, 0, 200, 200],
['Geeks', 'A', 9000, 0, 8800, 200, 200],
['SsBlue', 'B', 9000, 0, 8800, 200, 19]])
# setting datag=frame index
df.set_index('Name', inplace=True)
# creating a pattern mixer object
miner = data_patterns.PatternMiner(df)
# finding the pattern in the dataframe
# name is optional
# other patterns which can be used ‘>’, ‘<’, ‘<=’, ‘>=’, ‘!=’, ‘sum’
df_patterns = miner.find({'name': 'equal values',
'pattern': '=',
'parameters': {"min_confidence": 0.5,
"min_support": 2,
"decimal": 8}})
# getting the analyzed dataframe
df_results = miner.analyze(df)
# printing the analyzed results
print(df_results)
输出:
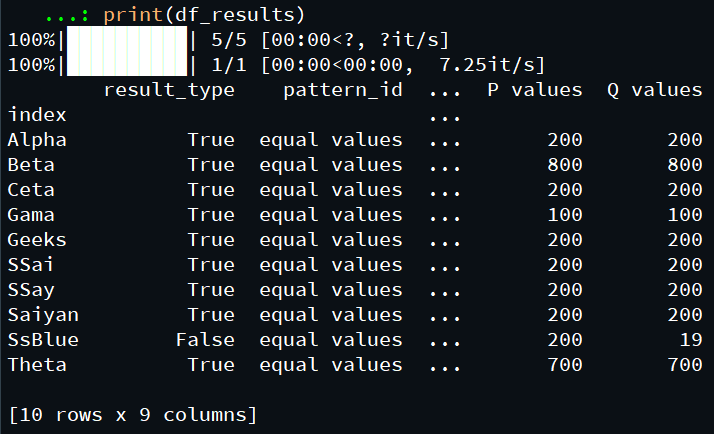
正如我们在这里看到的,在数据框中存在的不同数据项之间识别了各种模式。