Python|使用 Spacy 执行句子分割
在 NLP 中决定句子实际从哪里开始或结束的过程,或者我们可以简单地说,这里我们是根据句子划分段落。这个过程被称为句子分割。在Python中,我们使用spacy库来实现这部分 NLP。
Spacy 用于Python中的自然语言处理。
要在我们的Python程序中使用这个库,我们首先需要安装它。
安装此库的命令:
pip install spacy
python -m spacy download en_core_web_sm
Here en_core_web_sm means core English Language available online of small size.例子:
we have the following paragraph:
"I Love Coding. Geeks for Geeks helped me in this regard very much. I Love Geeks for Geeks."
here there are 3 sentences.
1. I Love Coding.
2. Geeks for Geeks helped me in this regard very much.
3. I Love Geeks for Geeks在Python中, .sents用于在 spacy 中存在的句子分割。输出由.sents给出,它是一个生成器,如果我们想随机打印它们,我们需要使用列表。
代码:
#import spacy library
import spacy
#load core english library
nlp = spacy.load("en_core_web_sm")
#take unicode string
#here u stands for unicode
doc = nlp(u"I Love Coding. Geeks for Geeks helped me in this regard very much. I Love Geeks for Geeks.")
#to print sentences
for sent in doc.sents:
print(sent)
输出: 
现在如果我们尝试随机使用 doc.sents 会发生什么: 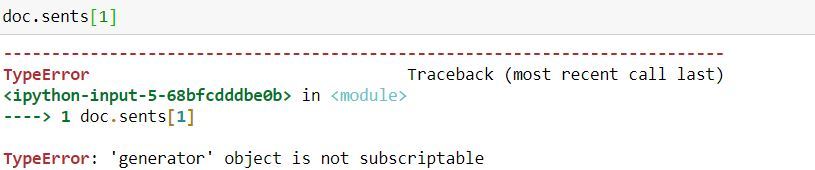
代码:为了克服这个错误,我们首先需要使用列表函数将此生成器转换为列表。
#converting the generator object result in to list
doc1 = list(doc.sents)
#Now we can use it randomly as
doc1[1]
输出: 