📌 相关文章
- 机器学习中的混淆矩阵
- 混淆矩阵python(1)
- 混淆矩阵python代码示例
- r 混淆矩阵 - R 编程语言(1)
- 机器学习中的 P 值(1)
- C++中的机器学习(1)
- 机器学习 (1)
- 机器学习中的 P 值
- C++中的机器学习
- r 混淆矩阵 - R 编程语言代码示例
- 如何在python中获取混淆矩阵(1)
- 混淆矩阵python代码 - Python(1)
- 机器学习 python (1)
- 如何在python代码示例中获取混淆矩阵
- 如何在 r 中制作混淆矩阵 (1)
- 使用 python 计算混淆矩阵(1)
- 绘制混淆矩阵 - Python (1)
- 使用 python 代码示例计算混淆矩阵
- 混淆矩阵python代码 - Python代码示例
- 机器学习 python 代码示例
- 绘制混淆矩阵 - Python 代码示例
- 机器学习 - 任何代码示例
- 混淆矩阵 seaborn - Python (1)
- 在混淆矩阵上打印标签 - Python (1)
- 什么是机器学习?
- 机器学习-什么是P值(1)
- 机器学习-什么是P值
- 什么是机器学习?(1)
- 在机器学习中什么是“i” (1)
📜 机器学习中的混淆矩阵
📅 最后修改于: 2020-09-29 03:21:19 🧑 作者: Mango
机器学习中的混淆矩阵
混淆矩阵是用于确定给定一组测试数据的分类模型的性能的矩阵。只能确定测试数据的真实值是否已知。矩阵本身很容易理解,但是相关术语可能会造成混淆。由于它以矩阵形式显示模型性能中的误差,因此也称为误差矩阵。混淆矩阵的一些功能如下:
- 对于分类器的2个预测类,矩阵是2 * 2表,对于3个类,它是3 * 3表,依此类推。
- 矩阵分为两个维度,即预测值和实际值以及预测的总数。
- 预测值是由模型预测的那些值,而实际值是给定观测值的真实值。
- 如下表所示:

上表有以下几种情况:
- 真负:模型给出的预测为否,实际或实际值也为否。
- 真实肯定:模型预测为是,实际值也真实。
- 假阴性:模型预测为否,但实际值为是,也称为II型错误 。
- 误报:该模型预测为是,但实际值为否。它也称为Type-I错误。
机器学习中对混淆矩阵的需求
- 当它们对测试数据进行预测时,它会评估分类模型的性能,并告诉我们分类模型的性能如何。
- 它不仅告诉分类器所犯的错误,而且告诉错误的类型,例如I型或II型错误。
- 借助混淆矩阵,我们可以为模型计算不同的参数,例如精度,精度等。
例子:我们可以通过一个例子来理解混淆矩阵。
假设我们正在尝试创建一个模型,该模型可以预测某人患有或未患有该疾病的疾病的结果。因此,对此的混淆矩阵为:
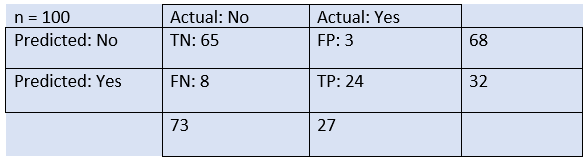
从上面的示例,我们可以得出以下结论:
- 该表是针对两类分类器给出的,该分类器具有两个预测“是”和“否”。在此,“是”定义患者患有该疾病,而“否”定义患者没有该疾病。
- 分类器总共做出了100个预测 。在100个预测中,有89个是正确的预测 ,有11个是错误的预测 。
- 该模型给出32次预测为“是”,给出68次预测为“否”。实际的“是”为27次,实际的“否”为73次。
使用混淆矩阵的计算:
我们可以使用此矩阵为模型执行各种计算,例如模型的准确性。这些计算如下:
- 分类精度:它是确定分类问题准确性的重要参数之一。它定义了模型预测正确输出的频率。可以将其计算为分类器做出的正确预测数与分类器做出的所有预测数之比。公式如下:

- 错误分类率:也称为错误率,它定义了模型多长时间给出一次错误的预测。可以将错误率的值计算为分类器所做的所有预测的不正确预测数。公式如下:

- 精度:可以定义为模型提供的正确输出的数量,或者是模型已正确预测的所有阳性类别中的正确输出的数量,其中有多少是真实的。可以使用以下公式计算:

- 回想一下:定义为总阳性类别之外,我们的模型如何正确预测。召回率必须尽可能高。

- F度量:如果两个模型的精度较低且召回率较高,反之亦然,则很难比较这两个模型。因此,为此,我们可以使用F分数。该分数有助于我们同时评估召回率和准确性。如果召回率等于精度,则F分数最大。可以使用以下公式计算:

混淆矩阵中使用的其他重要术语:
- 空错误率:它定义了如果模型总是预测多数类,那么我们的模型不正确的频率就会很高 。根据准确性悖论,可以说“ 最佳分类器的错误率比空错误率高。 “
- ROC曲线: ROC是显示所有可能阈值的分类器性能的图形。该图在真实的阳性率(在Y轴上)和错误的阳性率(在X轴上)之间绘制。