- 在Python中从 Wikipedia 的信息框中获取文本(1)
- wikipedia api (1)
- wikipedia api - 任何代码示例
- pip install wikipedia - Python (1)
- python 获取 html 信息 - Python (1)
- 使用c#获取图像信息(1)
- pip install wikipedia - Python 代码示例
- python wikipedia api search - Python (1)
- python 获取 html 信息 - Python 代码示例
- python wikipedia api search - Python 代码示例
- 使用c#代码示例获取图像信息
- wikipedia api url - Html (1)
- python信息——Python(1)
- 使用Python获取电话号码信息
- 使用Python获取电话号码信息(1)
- wikipedia api url - Html 代码示例
- 框中的乳胶文本 (1)
- 为 pandas 数据框中的列获取假人 - Python (1)
- 链信息 (1)
- 获取系统信息——使用Python脚本
- python信息——Python代码示例
- 为 pandas 数据框中的列获取假人 - Python 代码示例
- 从数据框中获取特定列 - Python (1)
- 在数据框中获取随机行 - Python (1)
- 在 python 中获取操作系统信息(1)
- 获取操作系统信息python(1)
- python 从分组数据框中获取列 - Python (1)
- python 获取 cpu 信息 - Python (1)
- 从数据框中获取特定列 - Python 代码示例
📅 最后修改于: 2020-05-14 04:23:06 🧑 作者: Mango
信息框是用于收集和显示有关其主题的信息子集的模板。它可以描述为包含一组属性-值对的结构化文档,在Wikipedia中,它表示有关文章主题的信息摘要。
因此,维基百科信息框是固定格式的表格,通常添加到文章的右上角,以表示该Wiki页面的摘要文章,有时还可以改善对其他相关文章的导航。
[要了解有关infobox的更多信息,请单击此处 ]
Web爬网是一种机制,可帮助从网站提取大量数据,从而提取数据并将其保存到计算机中的本地文件或表(电子表格)格式的数据库中。
有几种从网络中提取信息的方法。使用API是从网站提取数据的最佳方法之一。几乎所有大型网站(如Youtube,Facebook,Google,Twitter,StackOverflow)都提供API以更结构化的方式访问其数据。如果您可以通过API获得所需的东西,那么它几乎总是比Web抓取更受欢迎的方法。
有时,在我们开发任何项目或在其他地方使用时,都需要抓取Wikipedia页面的内容。在本文中,我将告诉您如何提取Wikipedia的信息框的内容。
基本上,我们可以使用两个Python模块来抓取数据:
Urllib2:这是一个可用于获取URL的Python模块。urllib2是用于获取URL的Python模块。它以urlopen函数的形式提供了一个非常简单的界面。这能够使用各种不同的协议来获取URL。有关更多详细信息,请参阅文档页面。
BeautifulSoup:这是从网页中提取信息的不可思议的工具。您可以使用它来提取表,列表,段落,还可以放置过滤器以从网页中提取信息。查看BeautifulSoup的文档页面,BeautifulSoup不会为我们获取该网页。我们可以将urllib2与BeautifulSoup库一起使用。
现在,我将告诉您另一种简便的抓取
步骤的方法:
我们将使用的模块是:
1)lxml: lxml是功能最丰富且易于使用的库,用于处理Python语言中的XML和HTML。(你可以参考此了解更多有关LXML模块)
2)requests: requests是一个Apache2许可的HTTP库,用Python编写.requests将允许您使用Python发送HTTP / 1.1请求。使用它,您可以通过简单的Python库添加诸如标题,表单数据,多部分文件和参数之类的内容。它还允许您以相同的方式访问Python的响应数据。有关更多信息,请单击此处。
我在这里使用过Python 2.7,
确保这些模块已安装在您的计算机上。
如果没有,则在控制台上或提示您可以使用pip安装它
# 导入模块
import requests
from lxml import etree
# 手动存储所需的URL
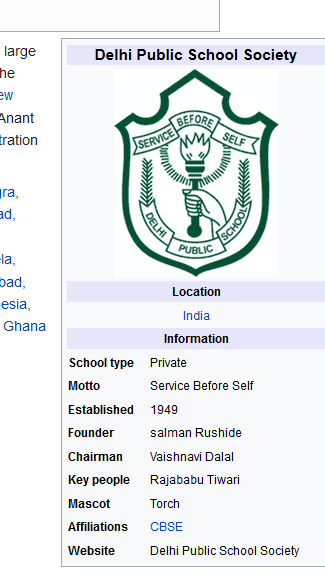
url='https://en.wikipedia.org/wiki/Delhi_Public_School_Society'
# 通过请求模块获取其URL
req = requests.get(url)
store = etree.fromstring(req.text)
# 这将在Wikipedia页面的URL的信息框中提供Motto部分
output = store.xpath('//table[@class="infobox vcard"]/tr[th/text()="Motto"]/td/i')
# 打印文字部分
print output[0].text
# 使用cmd或任何IDE在已安装的Python或本地系统上运行此程序.看到此链接,它将显示此维基百科页面信息框的“格言部分” 。(如此屏幕截图所示)
首先编写代码

现在终于在运行程序之后,


您还可以修改URL和store.xpath以获取信息框的不同部分。