K最近邻是机器学习中最基本但必不可少的分类算法之一。它属于监督学习领域,在模式识别,数据挖掘和入侵检测中得到了广泛的应用。
由于它是非参数的,因此在现实生活中广泛使用,这意味着它不对数据的分布进行任何基础假设(与其他算法(例如GMM等,假定给定数据呈高斯分布)相对) 。
我们获得了一些先验数据(也称为训练数据),这些数据将坐标分类为由属性标识的组。
例如,请考虑包含两个功能的下表数据点: 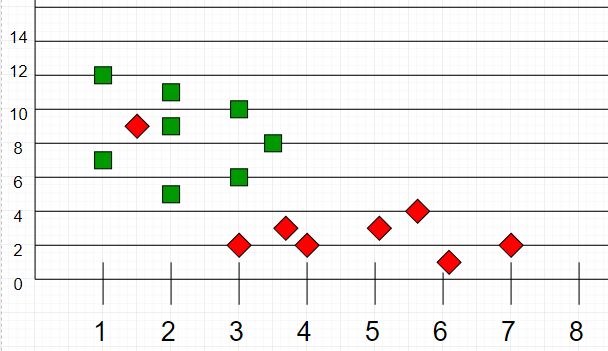
现在,给定另一组数据点(也称为测试数据),通过分析训练集将这些点分配为一组。请注意,未分类的点被标记为“白色”。
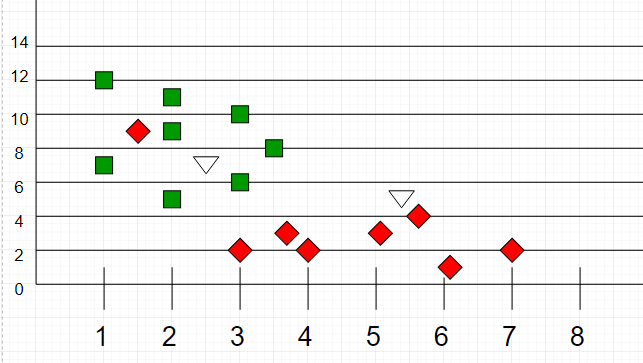
直觉
如果将这些点绘制在图形上,则可能能够找到一些群集或组。现在,给定一个未分类的点,我们可以通过观察其最近的邻居属于哪个组来将其分配给一个组。这意味着靠近被分类为“红色”的点的群集的点更有可能被分类为“红色”。
直观地,我们可以看到第一个点(2.5、7)应归类为“绿色”,第二个点(5.5、4.5)应归类为“红色”。
算法
令m为训练数据样本的数量。令p为未知点。
- 将训练样本存储在数据点arr []的数组中。这意味着该数组的每个元素都代表一个元组(x,y)。
-
for i=0 to m: Calculate Euclidean distance d(arr[i], p). - 使K的最小距离的集合S。这些距离中的每一个对应于已经分类的数据点。
- 返回S中的多数标签。
K可以保留为奇数,以便在只有两个组(例如红色/蓝色)的情况下,我们可以计算出明显的多数。随着K的增加,我们可以在不同类别之间获得更平滑,更明确的边界。同样,随着我们增加训练集中数据点的数量,上述分类器的准确性也会提高。
范例程序
假设0和1为两个分类器(组)。
C/C++
// C++ program to find groups of unknown
// Points using K nearest neighbour algorithm.
#include
using namespace std;
struct Point
{
int val; // Group of point
double x, y; // Co-ordinate of point
double distance; // Distance from test point
};
// Used to sort an array of points by increasing
// order of distance
bool comparison(Point a, Point b)
{
return (a.distance < b.distance);
}
// This function finds classification of point p using
// k nearest neighbour algorithm. It assumes only two
// groups and returns 0 if p belongs to group 0, else
// 1 (belongs to group 1).
int classifyAPoint(Point arr[], int n, int k, Point p)
{
// Fill distances of all points from p
for (int i = 0; i < n; i++)
arr[i].distance =
sqrt((arr[i].x - p.x) * (arr[i].x - p.x) +
(arr[i].y - p.y) * (arr[i].y - p.y));
// Sort the Points by distance from p
sort(arr, arr+n, comparison);
// Now consider the first k elements and only
// two groups
int freq1 = 0; // Frequency of group 0
int freq2 = 0; // Frequency of group 1
for (int i = 0; i < k; i++)
{
if (arr[i].val == 0)
freq1++;
else if (arr[i].val == 1)
freq2++;
}
return (freq1 > freq2 ? 0 : 1);
}
// Driver code
int main()
{
int n = 17; // Number of data points
Point arr[n];
arr[0].x = 1;
arr[0].y = 12;
arr[0].val = 0;
arr[1].x = 2;
arr[1].y = 5;
arr[1].val = 0;
arr[2].x = 5;
arr[2].y = 3;
arr[2].val = 1;
arr[3].x = 3;
arr[3].y = 2;
arr[3].val = 1;
arr[4].x = 3;
arr[4].y = 6;
arr[4].val = 0;
arr[5].x = 1.5;
arr[5].y = 9;
arr[5].val = 1;
arr[6].x = 7;
arr[6].y = 2;
arr[6].val = 1;
arr[7].x = 6;
arr[7].y = 1;
arr[7].val = 1;
arr[8].x = 3.8;
arr[8].y = 3;
arr[8].val = 1;
arr[9].x = 3;
arr[9].y = 10;
arr[9].val = 0;
arr[10].x = 5.6;
arr[10].y = 4;
arr[10].val = 1;
arr[11].x = 4;
arr[11].y = 2;
arr[11].val = 1;
arr[12].x = 3.5;
arr[12].y = 8;
arr[12].val = 0;
arr[13].x = 2;
arr[13].y = 11;
arr[13].val = 0;
arr[14].x = 2;
arr[14].y = 5;
arr[14].val = 1;
arr[15].x = 2;
arr[15].y = 9;
arr[15].val = 0;
arr[16].x = 1;
arr[16].y = 7;
arr[16].val = 0;
/*Testing Point*/
Point p;
p.x = 2.5;
p.y = 7;
// Parameter to decide group of the testing point
int k = 3;
printf ("The value classified to unknown point"
" is %d.\n", classifyAPoint(arr, n, k, p));
return 0;
} Python
# Python3 program to find groups of unknown
# Points using K nearest neighbour algorithm.
import math
def classifyAPoint(points,p,k=3):
'''
This function finds the classification of p using
k nearest neighbor algorithm. It assumes only two
groups and returns 0 if p belongs to group 0, else
1 (belongs to group 1).
Parameters -
points: Dictionary of training points having two keys - 0 and 1
Each key have a list of training data points belong to that
p : A tuple, test data point of the form (x,y)
k : number of nearest neighbour to consider, default is 3
'''
distance=[]
for group in points:
for feature in points[group]:
#calculate the euclidean distance of p from training points
euclidean_distance = math.sqrt((feature[0]-p[0])**2 +(feature[1]-p[1])**2)
# Add a tuple of form (distance,group) in the distance list
distance.append((euclidean_distance,group))
# sort the distance list in ascending order
# and select first k distances
distance = sorted(distance)[:k]
freq1 = 0 #frequency of group 0
freq2 = 0 #frequency og group 1
for d in distance:
if d[1] == 0:
freq1 += 1
elif d[1] == 1:
freq2 += 1
return 0 if freq1>freq2 else 1
# driver function
def main():
# Dictionary of training points having two keys - 0 and 1
# key 0 have points belong to class 0
# key 1 have points belong to class 1
points = {0:[(1,12),(2,5),(3,6),(3,10),(3.5,8),(2,11),(2,9),(1,7)],
1:[(5,3),(3,2),(1.5,9),(7,2),(6,1),(3.8,1),(5.6,4),(4,2),(2,5)]}
# testing point p(x,y)
p = (2.5,7)
# Number of neighbours
k = 3
print("The value classified to unknown point is: {}".\
format(classifyAPoint(points,p,k)))
if __name__ == '__main__':
main()
# This code is contributed by Atul Kumar (www.fb.com/atul.kr.007)输出:
The value classified to unknown point is 0.