删除重复列的 SQL 查询
通过本文,我们将学习如何从数据库表中删除重复的列。正如我们所知,我们数据库中的重复性往往会浪费内存空间。它记录不准确的数据,也无法从数据库中获取正确的数据。要删除重复的列,我们在 SELECT 语句中使用 DISTINCT运算符,如下所示:
句法:
SELECT DISTINCT
column1, column2, ...
FROM
table1;- DISTINCT 在一列中使用时,使用该列中的值来评估重复项。
- 当有两列或多列时,它使用这些列中的值组合来评估重复项。
注意: DISTINCT 不会删除表中的数据,它只会删除结果表中的重复项。
第 1 步:首先我们必须创建一个名为“employee”的表
询问:
CREATE TABLE employee
( name varchar(30),salary int);第 2 步:现在,我们必须在表中插入值或数据。
询问:
INSERT INTO employee (name,salary)
VALUES ('A',24000),
('B',17000),
('C',17000),
('D',24000),
('E',14000),
('F',14000);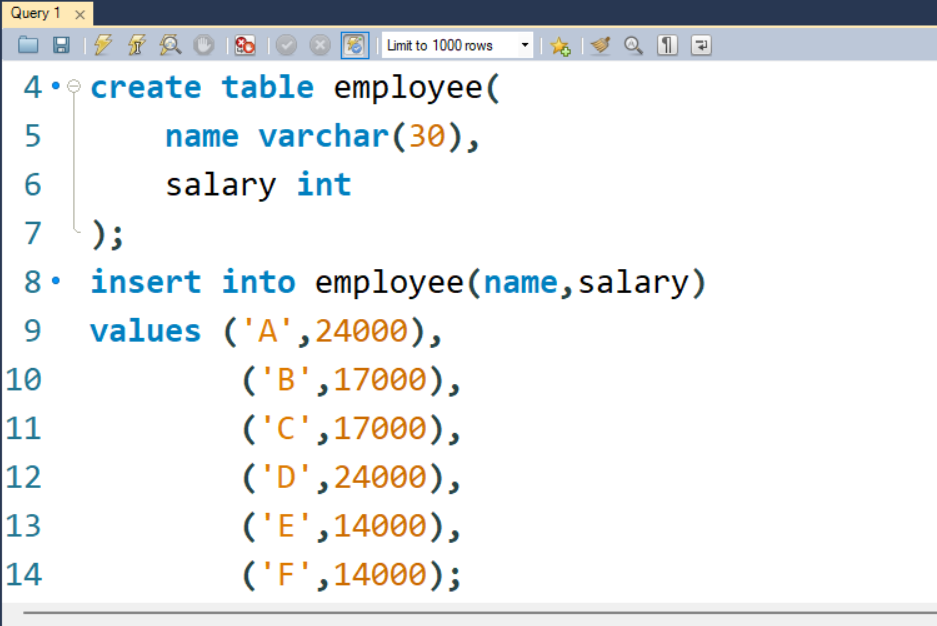
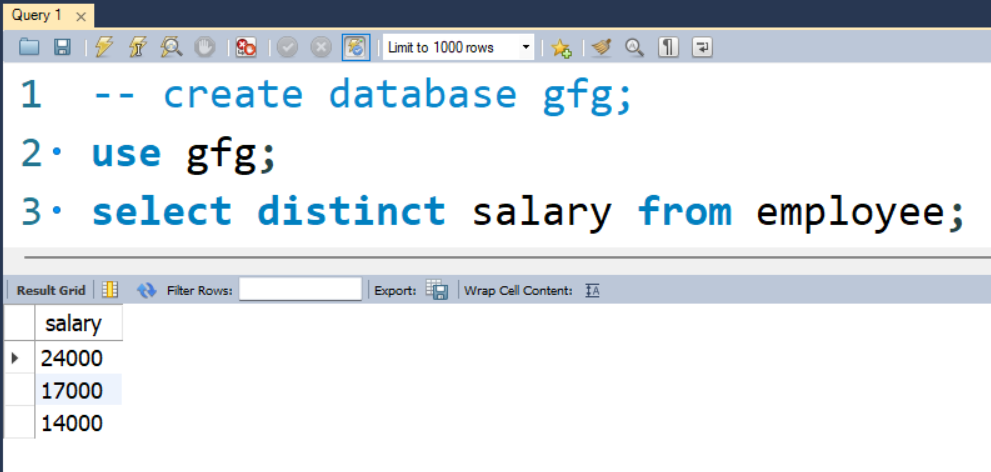
第 3 步:现在我们使用下面给出的查询查看完整的表值。
询问:
SELECT salary FROM employee;输出:

第 4 步:我们使用示例数据库中的员工表作为示例来展示 DISTINCT 的使用。
询问:
SELECT DISTINCT salary FROM employees;输出: