大数据的类型
用户每天产生 2.5 万亿字节的数据。 Statista 的预测表明,到 2021 年底,互联网将产生 74 Zettabytes(74 万亿 GB)的数据。管理如此空洞且长期存在的数据外包变得越来越困难。因此,为了管理如此庞大的复杂数据,引入了大数据,它涉及将大而复杂的数据提取成传统方法无法提取或分析的有意义的数据。
不能以相同的方式存储所有数据。在确定数据类型后,可以准确评估数据存储的方法。云服务,如 Microsoft Azure,是存储各种数据的一站式目的地; Blob、队列、文件、表、磁盘和应用程序数据。然而,即使在云中,也有特殊的服务来处理特定的数据子类别。
例如,Azure SQL 和 Azure Cosmos DB 等 Azure 云服务有助于处理和管理种类繁多的数据。
应用程序数据是由应用程序创建、读取、更新、删除或处理的数据。这些数据可以通过 Web 应用程序、Android 应用程序、iOS 应用程序或任何应用程序生成。由于所使用的数据种类多种多样,因此确定存储方法有些细微差别。
大数据的类型

结构化数据
结构化数据可以粗略地定义为位于记录内固定字段中的数据。它受特定模式的约束,因此所有数据都具有相同的一组属性。结构化数据也称为关系数据。它被拆分为多个表,以通过创建单个记录来描述实体来增强数据的完整性。关系是通过应用表约束来强制执行的。
需要结构化查询语言 (SQL)来将数据汇集在一起。结构化数据易于输入、查询和分析。所有数据都遵循相同的格式。但是,强制使用一致的结构也意味着对数据的任何更改都太困难了,因为必须更新每条记录以符合新结构。结构化数据的示例包括数字、日期、字符串等。电子商务网站的业务数据可以被认为是结构化数据。Name Class Section Roll No Grade Geek1 11 A 1 A Geek2 11 A 2 B Geek3 11 A 3 A
结构化数据的缺点
- 结构化数据只能在预定义功能的情况下使用。这意味着结构化数据的灵活性有限,仅适用于某些特定用例。
- 结构化数据存储在具有严格约束和明确模式的数据仓库中。需求的任何变化都意味着更新所有结构化数据以满足新的需求。这在资源和时间管理方面是一个巨大的缺陷。
半结构化数据
半结构化数据不受任何用于数据存储和处理的严格模式的约束。数据不是关系格式,也没有像电子表格中那样整齐地组织成行和列。但是,有一些特征,如键值对,有助于区分不同的实体。由于半结构化数据不需要结构化查询语言,因此通常称为NoSQL 数据。数据序列化语言用于跨系统交换半结构化数据,这些系统甚至可能具有不同的底层基础设施。
数据以纯文本形式创建,因此可以使用不同的文本编辑工具来得出有价值的见解。由于格式简单,数据序列化读取器可以在处理资源和带宽有限的硬件上实现。
数据序列化语言
软件开发人员使用序列化语言将基于内存的数据写入文件、传输、存储和解析。发送者和接收者不需要知道其他系统。只要使用相同的序列化语言,两个系统都可以轻松理解数据。主要使用三种序列化语言。

1. XML – XML 代表可扩展标记语言。它是一种基于文本的标记语言,旨在存储和传输数据。 XML 解析器可以在几乎所有流行的开发平台中找到。它是人类和机器可读的。 XML 有明确的模式、转换和显示标准。它是自我描述的。下面是 XML 中程序员详细信息的示例。
XML
Jane
Doe
GeeksforGeeks
Code4Eva!
CodeisLife
Javascript
{
"firstName": "Jane",
"lastName": "Doe",
"codingPlatforms": [
{ "type": "Fav", "value": "Geeksforgeeks" },
{ "type": "2ndFav", "value": "Code4Eva!" },
{ "type": "3rdFav", "value": "CodeisLife" }
]
}XML 使用标签(尖括号内的文本)来表达数据以塑造数据(例如:FirstName)和属性(例如:Type)来表征数据。然而,作为一种冗长而冗长的语言,其他格式已经获得了更多的欢迎。
2. JSON ——JSON(JavaScript Object Notation)是一种用于数据交换的轻量级开放标准文件格式。 JSON 易于使用,并使用人/机器可读的文本来存储和传输数据对象。
Javascript
{
"firstName": "Jane",
"lastName": "Doe",
"codingPlatforms": [
{ "type": "Fav", "value": "Geeksforgeeks" },
{ "type": "2ndFav", "value": "Code4Eva!" },
{ "type": "3rdFav", "value": "CodeisLife" }
]
}
这种格式不像 XML 那样正式。它更像是一个键/值对模型,而不是正式的数据描述。 Javascript 内置了对 JSON 的支持。尽管 JSON 在 Web 开发人员中非常流行,但非技术人员发现使用 JSON 很乏味,因为它严重依赖 JavaScript 和结构字符(大括号、逗号等)。
3. YAML – YAML 是一种用户友好的数据序列化语言。形象地说,它代表YAML Ain't Markup Language。由于其简单性,它被全球各地的技术和非技术处理人员采用。数据结构由行分隔和缩进定义,减少了对结构字符的依赖。 YAML 非常全面,它的流行是其人机可读性的结果。
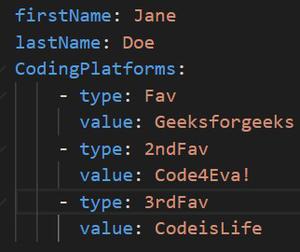
YAML 示例
由标签组织的产品目录是半结构化数据的一个例子。
非结构化数据
非结构化数据是一种不遵循任何明确模式或规则集的数据。它的安排是无计划的和随意的。照片、视频、文本文档和日志文件通常可以视为非结构化数据。尽管伴随图像或视频的元数据可能是半结构化的,但处理的实际数据是非结构化的。
概括
应用数据可以分为结构化、半结构化和非结构化数据。结构化数据被整齐地组织并遵守一组固定的规则。半结构化数据不遵循任何模式,但它对组织具有某些可识别的特征。数据序列化语言用于将数据对象转换为字节流。其中包括 XML、JSON 和 YAML。非结构化数据根本没有任何结构。所有这三种数据都存在于应用程序中。他们三者在开发资源丰富且有吸引力的应用程序方面发挥着同样重要的作用。